2.格式输出 运算符 字符编码
1.格式输出
现在有以下需求,让用户输入name, age, job,hobby 然后输出如下所示
------------ info of Alex Li ---------- Name : Alex Li Age : 22 job : Teacher Hobbie: girl ------------- end ----------------
你怎么实现呢?你会发现,用字符拼接的方式还难实现这种格式的输出,所以一起来学一下新姿势 只需要把要打印的格式先准备好, 由于里面的 一些信息是需要用户输入的,你没办法预设知道,因此可以先放置个占位符,再把字符串里的占位符与外部的变量量做个映射关系就好啦
name = input("Name:")
age = input("Age:")
job = input("Job:")
hobby = input("Hobbie:")
info = """
------------ info of %s ----------
Name : %s
Age : %s
job : %s
Hobbie: %s
------------- end ----------------
""" %(name,name,age,job,hobby)
print(info)
%s就是代表字符串占位符,除此之外,还有%d, 是数字占位符, 如果把上面的age后面的换成%d,就代表你必须只能输入数字啦 这时对应的数据必须是int类型. 否则程序会报错
使用时,需要进行类型转换.
int(str) #字符串转换成int str(int) #int转换成字符串
类似这样的操作在后面还有很多如果, 你头铁. 就不想转换. 觉着转换很麻烦. 也可以全部都用%s. 因为任何东西都可以直接转换成字符串--> 仅限%s 现在又来新问题了. 如果想输出:
我叫小钱, 今年22岁了,我们已经学习了2%的python基础了
这里的问题出在哪里呢? 没错2%, 在字符串中如果使用了%s这样的占位符. 那么所有的%都将变成占位符. 我们的2%也变成了占位符. 而"%的"是不存在的, 这里我们需要使用%%来表示字符串中的%. 注意: 如果你的字符串中没有使用过%s,%d站位. 那么不需要考虑这么多. 该%就%.没毛病老铁.
print("我是%s,今年22岁了,学习了python2%%了" % '小钱') #有占位符
print("我是小钱,今年22岁了,学习了python2%了" ) #没有占位符
字符串格式化使用操作符百分号(%)实现
符 号 说 明 %c 格式化字符及其ASCII码 %s 格式化字符串 %d 格式化整数 %o 格式化无符号八进制数 %x 格式化无符号十六进制数 %X 格式化无符号十六进制数(大写) %f 格式化定点数,可指定小数点后的精度 %e 用科学计数法格式化定点数 %E 作用同%e,用科学计数法格式化定点数 %g 根据值的大小决定使用%f活%e %G 作用同%g,根据值的大小决定使用%f或者%E
# -*- coding:utf-8 -*-
name = input("输入姓名:").strip()
address = input("你来自哪里:").strip()
wife = input("输入老婆名字:").strip()
notlike = input("不喜欢的明星:").strip()
print("我叫"+name+",我来自"+address+",我老婆是"+wife+",不喜欢的明星"+notlike)
print("我叫%s,我来自%s,我老婆是%s,不喜欢的明星%s" % (name, address, wife, notlike))
print(f"我叫{name},我来自{address},我老婆是{wife},不喜欢的明星{notlike}")
print("我叫{},我来自{},我老婆是{},不喜欢的明星{}".format(name, address, wife, notlike))
2.运算符
基本运算符
计算机可以进行的运算有很多种,可不只加减乘除这么简单,运算按种类可分为:
算数运算、 比较运算、逻辑运算、 赋值运算、 成员运算、 身份运算、 位运算.
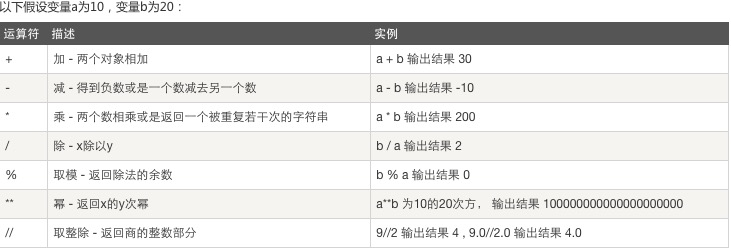
算数运算
比较运算

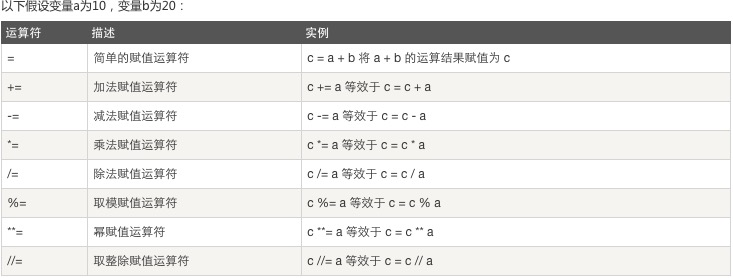
赋值运算
逻辑运算

and
x and y, x为真,值是y,x为假,值是x
print(12 and 13) # 13 print(0 and 13) # 0
or
x or y , x为真,值就是x,x为假,值是y
print(12 or 13) # 12 print(0 or 13) # 13
not
如果x为True,返回False,如果x为False,返回Ture
print(not 2 > 1) # False print(not 2 < 1) #Ture
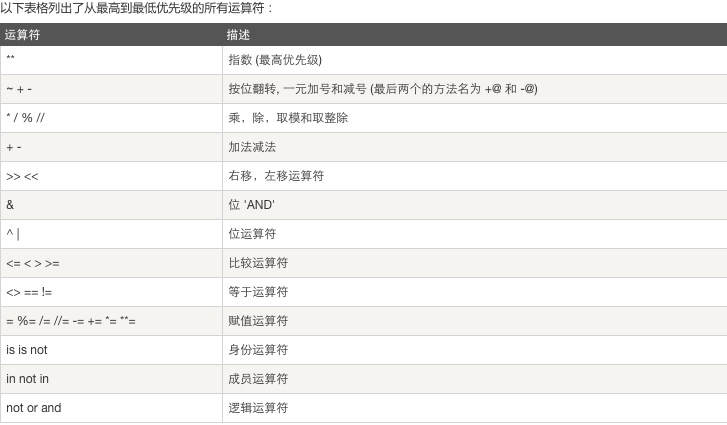
运算顺序
1, 在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算
()=> not => and =>or
print(6 or 8 and 3 or 5) #6 print(8 or 3 and 4 or 2 and 0 or 9 and 7) #8 print(0 or 2 and 3 and 4 or 6 and 0 or 3) #4 print(4 > 5 or 7 and 8 < 6 or 3 and 4) #4
函数
abs(number) 返回指定数的绝对值 bytes(string, encoding[, errors]) 对指定的字符串进行编码,并以指定的方式处理错误 cmath.sqrt(number) 返回平方根;可用于负数 float(object) 将字符串或数字转换为浮点数 help([object]) 提供交互式帮助 input(prompt) 以字符串的方式获取用户输入 int(object) 将字符串或数转换为整数 math.ceil(number) 以浮点数的方式返回向上圆整的结果 math.floor(number) 以浮点数的方式返回向下圆整的结果 math.sqrt(number) 返回平方根;不能用于负数 pow(x, y[, z]) 返回x的y次方对z求模的结果 print(object, ...) 将提供的实参打印出来,并用空格分隔 repr(object) 返回指定值的字符串表示 round(number[, ndigits]) 四舍五入为指定的精度,正好为5时舍入到偶数 str(object) 将指定的值转换为字符串。用于转换bytes时,可指定编码和错误处理方式
数学表达式
10 % -3 = -2
x % y 等价于 x - (x // y) * y
10 // -3 = -4
import math math.floor(2.6) #2 math.floor(2.4) #2 math.ceil(2.4) #3 math.ceil(2.6) #3
round(2.6) #3 round(2.4) #2
3.字符编码
编码问题
python2解释器在加载 .py 文件中的代码时,会对内容进行编码(默认ascill),而python3对内容进行编码的默认为utf8。
计算机:
早期. 计算机是美国发明的. 普及率不高, 一般只是在美国使用. 所以. 早的编码结构就是按照美国人的习惯来编码的. 对应数字+字⺟母+特殊字符一共也没多少. 所以就形成了早的编码ASCII码. 直到今天ASCII依然深的影响着我们.
ASCII(American Standard Code for Information Interchange,美国标准信息交换代码)是基于拉丁字⺟母的一套电 脑编码系统,主要用于显示现代英语和其他⻄西欧语言,其多只能⽤ 8 位来表示(一个字节bytes),即:2**8 = 256,所 以,ASCII码多只能表示 256 个符号。
随着计算机的发展. 以及普及率的提高. 流行到欧洲和亚洲. 这时ASCII码就不合适了. 比如: 中文汉字有几万个. 而ASCII 多也就256个位置. 所以ASCII不行了. 怎么办呢? 这时, 不同的国家就提出了不同的编码用来适用于各自的语言环境. 比如, 中国的GBK, GB2312, BIG5, ISO-8859-1等等. 这时各个国家都可以使用计算机了.
GBK, 国标码占用2个字节. 对应ASCII码 GBK直接兼容. 因为计算机底层是用英⽂写的. 你不支持英文肯定不行. 而英文已经使用了了ASCII码. 所以GBK要兼容ASCII.
这⾥里GBK国标码. 前面的ASCII码部分. 由于使用两个字节. 所以对于ASCII码而言. 前9位都是0
字⺟母A:0100 0001 # ASCII 字⺟母A:0000 0000 0100 0001 # 国标码
国标码的弊端: 只能中国用. 日本就垮了. 所以国标码不满足我们的使用. 这时提出了一个万国码Unicode.
unicode一 开始设计是每个字符两个字节. 设计完了. 发现我大中国汉字依然无法进行编码. 只能进行扩充. 扩充成32位也就是4个字节. 这回够了. 但是. 问题来了. 中国字9万多. 而unicode可以表⽰示40多亿. 根本用不了. 太浪费了. 于是乎, 就提出了新的
UTF编码.可变长度编码
UTF-8: 每个字符最少占8位. 每个字符占用的字节数不定.根据文字内容进行具体编码. 比如. 英⽂. 就一个字节就够了. 汉字占3个字节. 这时即满足了中文. 也满足了节约. 也是目前使用频率最高的一种编码
UTF-16: 每个字符最少占16位.
GBK: 每个字符占2个字节, 16位.
初识编码
ASCLL 1967年
GB2312 1980年
Unicode 1991年
GBK 1995年
UYF-8 1992年
ascii
8bit 1byte(字节) 256个码位 只用到了7bit, 用到了前128个 最前面的一位是0
中国人自己对计算机编码进行统计. 自己设计. 对ascii进行扩展 ANSI 16bit -> 清华同方 -> gbk
GBK
放的是中文编码. 16bit 2byte 兼容ascii
unicode
对所有编码进行统一.
万国码. 32bit. 4byte. 够用了但是很浪费
Unicode 升级 utf-8 utf-16 utf-32
Unicode的两该字节表示一个字符(偏僻字符需要4个字节)
utf-8
可变长度的unicode
英文: 1byte
欧洲文字: 2byte
中文: 3byte
生僻字4 - 6vyte
ASCLL编码与Unicode编码的区别:
ASCLL编码是1个字节,而Unicode编码通常2个字节
文本全用英文用Unicode编码比ASCLL编码需要多一倍的存储空间。
字节(byte)
8bit = 1byte
1024byte = 1KB
1024KB = 1MB
1024MB = 1GB
1024GB = 1TB
1024TB = 1PB
1024TB = 1EB
1024EB = 1ZB
1024ZB = 1YB
1024YB = 1NB


1. 初识python python是一门弱类型的解释型高级编程语言 解释器: CPython 官方提供的默认解释器. c语言实现的 PyPy 把python程序一次性进行编译. IPython 2. python的版本 2.x 3.x 3. 变量 概念: 程序运行过程中产生的中间值. 暂时存储在内存, 方便后面的程序使用它 就是一个符号. x = 10 郝建 -> 沈腾 白云 -> 宋丹丹 命名规范: 1. 数字, 字母, 下划线组成 2. 不能是数字开头, 更不能是纯数字 3. 不能用python的关键字 4. 不要用中文 5. 不要太长 6. 有意义 7. 区分大小写 8. 用驼峰或者下划线 数据类型: 1. int 整数 +-*/% // ** 2. str 字符串, 把字符连城串 字符:单一的文字符号 '', "", ''', """ + 拼接. 要求两端都得是字符串 * 重复 必须乘以一个数字 3. bool 布尔值 True False 用来判断 用户交互 变量 = input(提示语) 条件判断: if 条件: if-语句块 if 条件: if-语句块 else: else-语句块 if 条件1: if-1 elif 条件2: if-2 ...... else: 二. 作业 三. 今日主要内容 1. while循环 (难点) while 条件: 循环体(break, continue) 2. 格式化输出 %s %d f"{变量}" 3. 运算符 and or not (难点) 运算顺序: ()=> not => and =>or 4. 初识编码 gbk unicode utf-8 1. ascii 8bit 1byte(字节) 256个码位 只用到了7bit, 用到了前128个 最前面的一位是0 2. 中国人自己对计算机编码进行统计. 自己设计. 对ascii进行扩展 ANSI 16bit -> 清华同方 -> gbk GBK 放的是中文编码. 16bit 2byte 兼容ascii 3. 对所有编码进行统一. unicode. 万国码. 32bit. 4byte. 够用了但是很浪费 4. utf-8 可变长度的unicode 英文: 1byte 欧洲文字: 2byte 中文: 3byte 字节(byte) 1byte = 8bit 1kb = 1024byte 1mb = 1024kb 1gb = 1024mb 1tb = 1024gb 1pb = 1024tb
作业

 浙公网安备 33010602011771号
浙公网安备 33010602011771号