BGE M3-Embedding 模型介绍
BGE M3-Embedding来自BAAI和中国科学技术大学,是BAAI开源的模型。相关论文在https://arxiv.org/abs/2402.03216,论文提出了一种新的embedding模型,称为M3-Embedding,它在多语言性(Multi-Linguality)、多功能性(Multi-Functionality)和多粒度性(Multi-Granularity)方面表现出色。M3-Embedding支持超过100种工作语言,支持8192长度的输入文本,同时支持密集检索(Dense Retrieval)、多向量检索(Multi-Vector Retrieval)和稀疏检索(Sparse Retrieval),为现实世界中的信息检索(IR)应用提供了统一的模型基础,通过这几种检索方式的组合,取得了良好的混合召回效果。
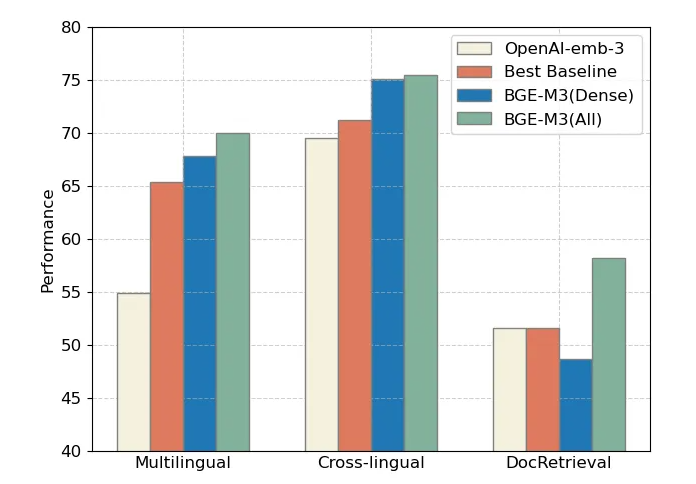
我们可以查看官方与openai模型的对比,整体来看,采用三种方式联合检索的BGE-M3(ALL)在三项评测中全面领先,而 BGE-M3(Dense)稠密检索在多语言、跨语言检索中具有明显优势。
BGE-M3 模型亮点
1. 多语言(Multi-Linguality),训练集包含100+种以上语言
2. 多功能(Multi-Functionality),支持稠密检索(Dense Retrieval),还支持稀疏检索(Sparse Retrieval)与多向量检索(Multi-vector Retrieval)
3. 多粒度(Multi-Granularity) BGE-M3目前可以处理最大长度为8192 的输入文本,支持“句子”、“段落”、“篇章”、“文档”等不同粒度的输入文本
BGE-M3 训练数据
M3-Embedding模型的训练数据组成是模型效果较好的一个关键创新点,因为它旨在支持多语言性、多功能性和多粒度性,训练数据分为三部分:
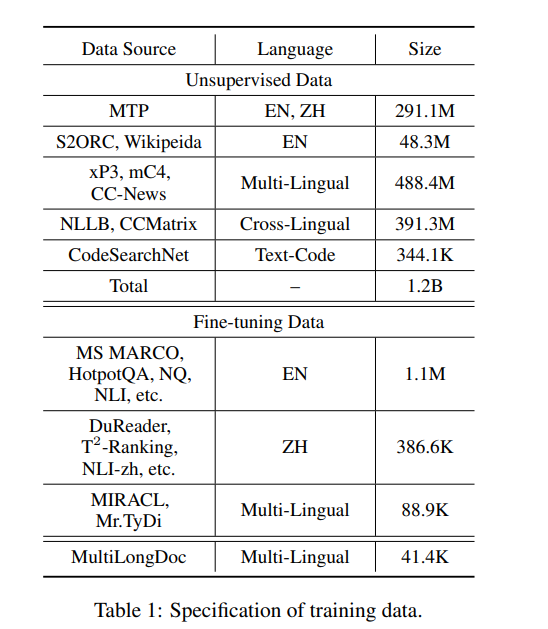
- 无监督数据(Unsupervised Data):
- 从大量多语言语料库中提取未经标记的文本数据,这些语料库包括Wikipedia、S2ORC、xP3、mC4和CC-News等。
- 这些数据通过提取丰富的语义结构(例如标题-正文、标题-摘要、指令-输出等)来丰富模型的语义理解能力。
- 无监督数据的规模达到了1.2亿文本对,覆盖了194种语言和2655种跨语言对应关系。
- 微调数据(Fine-tuning Data):
- 来自标记语料库的高质量数据,包括英语、中文和其他语言的数据集。
- 例如,英语数据集包括HotpotQA、TriviaQA、NQ、MS MARCO等,而中文数据集包括DuReader、T2-Ranking、NLI-zh等。
- 这些数据集用于进一步微调模型,以提高其在特定任务和语言上的性能。
- 合成数据(Synthetic Data):
- 为了解决长文档检索任务中数据不足的问题,研究者们生成了额外的多语言微调数据(称为MultiLongDoc)。
- 通过从Wikipedia和MC4数据集中随机选择长文章,并从中随机选择段落,然后使用GPT-3.5生成基于这些段落的问题,生成的问题和所选文章构成新的文本对,增加了训练数据的多样性和覆盖范围。
这些训练数据的创新之处在于:
- 多语言覆盖:M3-Embedding通过大规模的多语言无监督数据,学习不同语言之间的共同语义空间,从而支持多语言检索和跨语言检索。
- 数据多样性:通过结合无监督数据、微调数据和合成数据,M3-Embedding能够捕捉到不同类型和长度的文本数据的语义信息,从而提高模型对不同输入粒度的处理能力。
- 高质量数据整合:通过精心筛选和整合不同来源的数据,M3-Embedding确保了训练数据的高质量,这对于模型学习有效的文本嵌入至关重要。
通过这种创新的训练数据组成,M3-Embedding能够有效地学习并支持超过100种语言的文本嵌入,同时处理从短句到长达8192个词符的长文档,实现了在多语言、多功能和多粒度方面的突破。
从业界来看,M3-Embedding、E5-mistral-7b,都是利用GPT这样的LLM来合成了大量多语言数据,这个应该是后续的主流方案。
BGE-M3 混合检索
M3-Embedding统一了嵌入模型的三种常见检索功能,即密集检索(Dense retrieval)、词汇(稀疏)检索(Lexical retrieval)和多向量检索(Multi-vector retrieval)。以下是这些方法的公式化描述:
- 密集检索(Dense retrieval):输入查询q被转换为基于文本编码器的隐藏状态Hq,使用特殊标记“[CLS]”的归一化隐藏状态来表示查询:$e_q = \text{norm}(H_q[0])$。类似地,我们可以获取段落p的嵌入表示为 $e_p = \text{norm}(H_p[0])$。查询和段落之间的相关性得分通过两个嵌入向量 $e_p$ 和 $e_q$的内积来度量:$s_{\text{dense}} \leftarrow \langle e_p, e_q \rangle$。
def dense_embedding(self, hidden_state, mask):
if self.sentence_pooling_method == 'cls':
return hidden_state[:, 0]
elif self.sentence_pooling_method == 'mean':
s = torch.sum(hidden_state * mask.unsqueeze(-1).float(), dim=1)
d = mask.sum(axis=1, keepdim=True).float()
return s / d
- 词汇检索(Lexical Retrieval):输出嵌入还被用来估计每个词项的重要性,以促进词汇检索。对于查询中的每个词项t(在我们的工作中,词项对应于一个标记),词项权重被计算为 $w_{qt} \leftarrow \text{Relu}(W_{\text{lex}} H_q[i])$,其中 $W_{\text{lex}} \in \mathbb{R}^{d \times 1}$ 是将隐藏状态映射到一个实数的矩阵。如果词项t在查询中出现多次,我们只保留其最大权重。我们以相同的方式计算段落中每个词项的权重。基于估计的词项权重,查询和段落之间的相关性得分通过查询和段落中共同出现的词项(表示为$q ∩ p$)的联合重要性来计算:$s_{\text{lex}} \leftarrow \sum_{t \in q \cap p}(w_{qt} \cdot w_{pt})$。
def sparse_embedding(self, hidden_state, input_ids, return_embedding: bool = True):
# sparse_linear 线性层= torch.nn.Linear(in_features=self.model.config.hidden_size, out_features=1)
# 通过relu计算token weight
token_weights = torch.relu(self.sparse_linear(hidden_state))
if not return_embedding: return token_weights
# 形状为(input_ids.size(0), input_ids.size(1), self.vocab_size)的零张量
sparse_embedding = torch.zeros(input_ids.size(0), input_ids.size(1), self.vocab_size,
dtype=token_weights.dtype,
device=token_weights.device)
# 将token_weights中的值分散scatter到sparse_embedding的相应位置,索引位置根据input_ids提供
sparse_embedding = torch.scatter(sparse_embedding, dim=-1, index=input_ids.unsqueeze(-1), src=token_weights)
# CLS,PAD 等无用token
unused_tokens = [self.tokenizer.cls_token_id, self.tokenizer.eos_token_id, self.tokenizer.pad_token_id,
self.tokenizer.unk_token_id]
sparse_embedding = torch.max(sparse_embedding, dim=1).values
# 无用token weight设置为0
sparse_embedding[:, unused_tokens] *= 0.
return sparse_embedding
- 多向量检索(Multi-Vector Retrieval):作为密集检索的扩展,多向量方法利用整个输出嵌入来表示查询和段落:$E_q = \text{norm}(W_{\text{mul}} H_q), E_p = \text{norm}(W_{\text{mul}} H_p)$,其中 $W_{\text{mul}} \in \mathbb{R}^{d \times d}$ 是可学习的投影矩阵。按照ColBERT(Khattab和Zaharia, 2020)的方法,使用后期交互来计算细粒度的相关性得分:$s_{\text{mul}} \leftarrow \frac{1}{N} \sum_{i=1}^{N} \max_{j=1}^{M} E_q[i] \cdot E_p[j]$;N和M分别是查询和段落的长度。
由于嵌入模型的多功能性,检索过程可以在混合过程中进行。首先,可以通过每种方法单独检索候选结果(由于其高成本,可以免去多向量方法的这一步)。最终的检索结果是根据集成的相关性得分重新排序的:$s_{\text{rank}} \leftarrow s_{\text{dense}} + s_{\text{lex}} + s_{\text{mul}}$。
BGE-M3训练方式和创新点
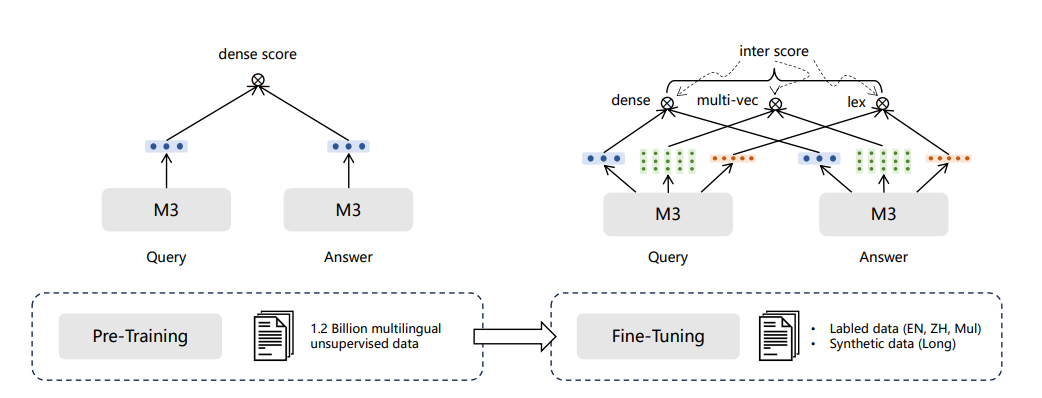
BGE-M3模型训练分为三个阶段:
-
1)RetroMAE预训练,在105种语言的网页数据和wiki数据上进行,提供一个可以支持8192长度和面向表示任务的基座模型;
-
2)无监督对比学习,在194种单语言和1390种翻译对数据共1.1B的文本对上进行的大规模对比学习;
-
3)多检索方式统一优化,在高质量多样化的数据上进行多功能检索优化,使模型具备多种检索能力。
-
其中,一些重要的关键技术如下:
1. 自学习蒸馏
人类可以利用多种不同的方式计算结果,矫正误差。模型也可以,通过联合多种检索方式的输出,可以取得比单检索模式更好的效果。因此,BGE-M3使用了一种自激励蒸馏方法来提高检索性能。具体来说,合并三种检索模式的输出,得到新的文本相似度分数,将其作为激励信号,让各单模式学习该信号,以提高单检索模式的效果。
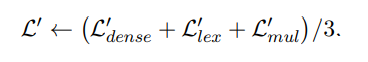
2. 训练效率优化
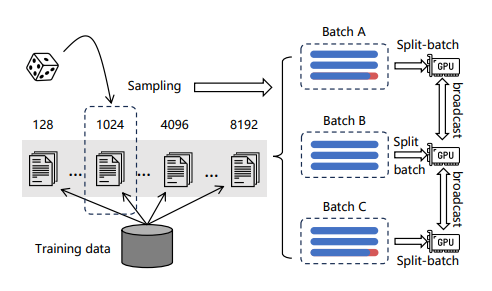
通过根据长度对文本数据进行分组,确保一个batch内文本长度相对相似,从而减少填充。为了减少文本建模时的显存消耗,将一批数据分成多个小批。对于每个小批,利用模型编码文本,收集输出的向量同时丢弃所有前向传播中的中间状态,最后汇总向量计算损失,可以显著增加训练的batch size。
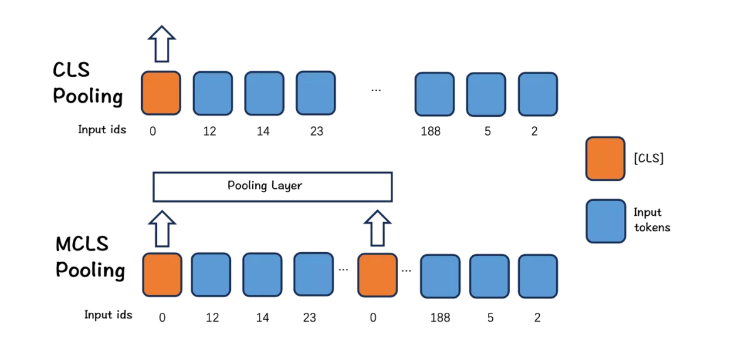
3. 长文本优化
BGE-M3提出了一种简单而有效的方法:MCLS(Multiple CLS)来增强模型的能力,而无需对长文本进行微调。
MCLS方法旨在利用多个CLS令牌来联合捕获长文本的语义。为每个固定数量的令牌插入一个cls令牌,每个cls令牌可以从相邻的令牌获取语义信息,最后通过对所有cls令牌的最后隐藏状态求平均值来获得最终的文本嵌入。
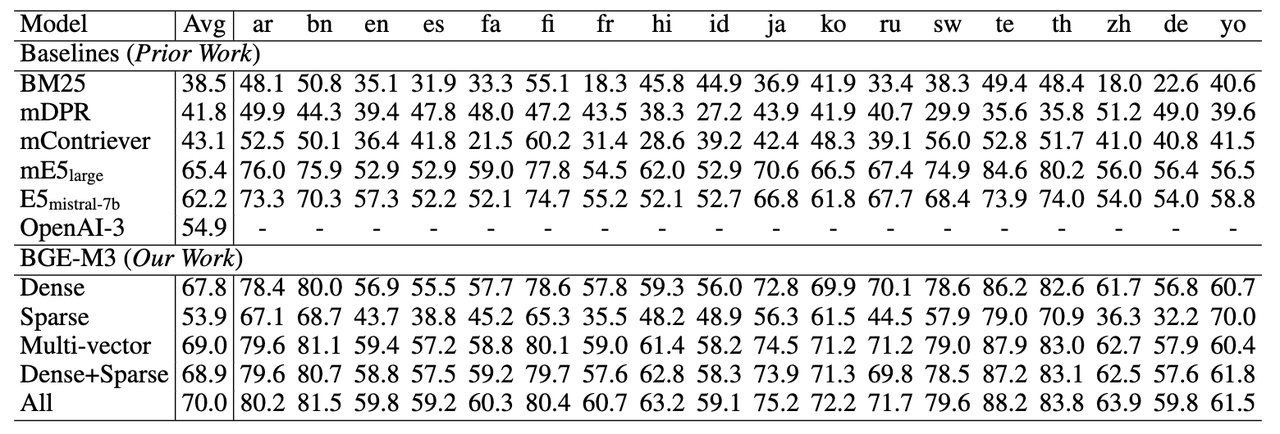
BGE-M3 实验结果
多语言检索任务,稀疏检索(Sparse)大幅超过了传统的稀疏匹配算法BM25。多向量检索(multi-vector)则获得了三种检索方式中的最佳效果。
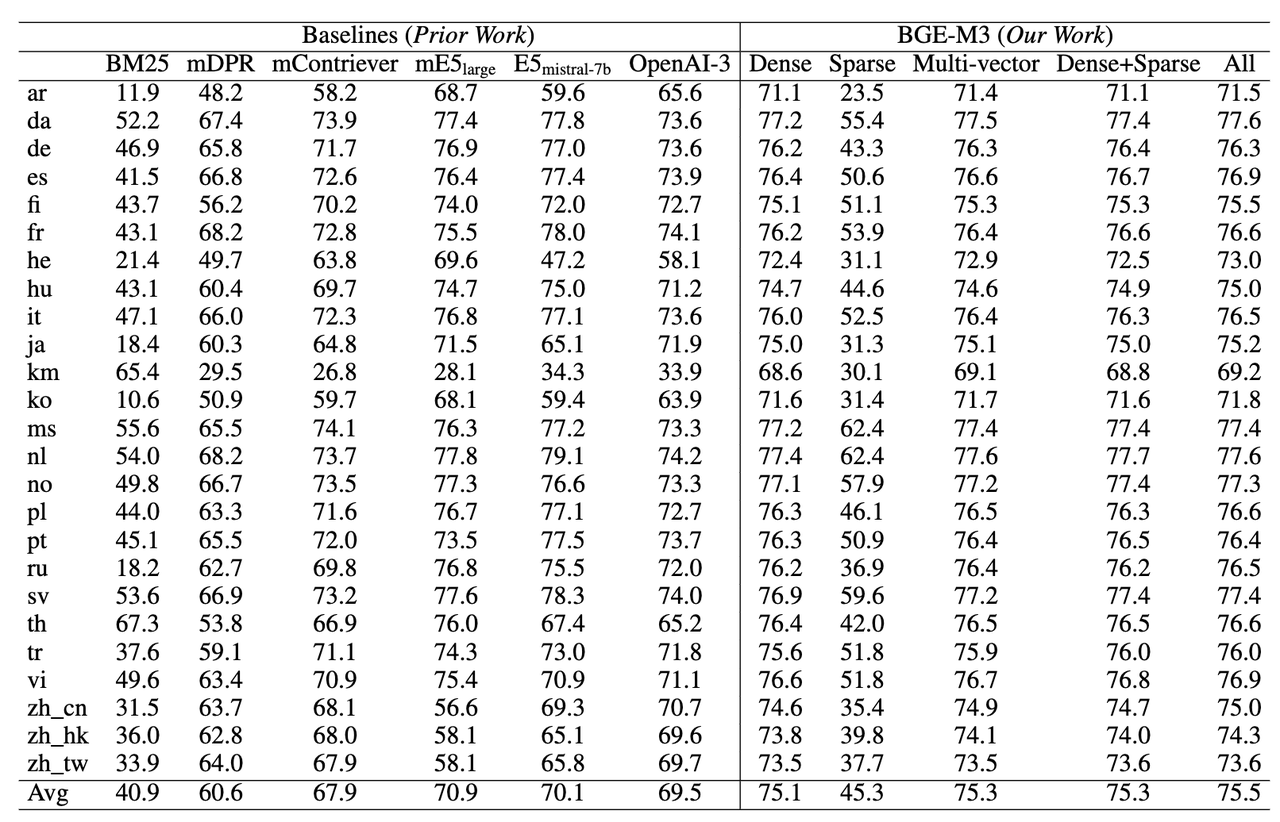
跨语言检索能力(MKQA)
BGE-M3在跨语言任务上依然具备最佳的检索效果。稀疏检索并不擅长应对跨语言检索这种词汇重合度很小的场景。因此,稀疏检索的自身效果以及与其他方法混搭所带来的收益相对较小。
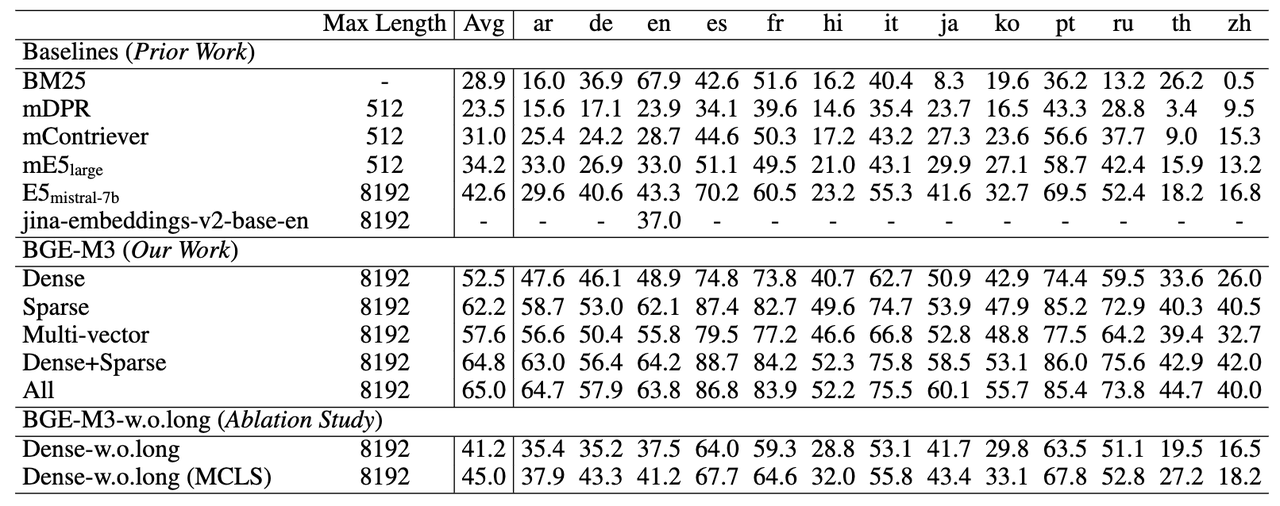
长文档检索能力 (MLRB: Multi-Lingual Long Retrieval Benchmark)
BGE-M3可以支持长达8192的输入文档,从实验结果可以观察到,稀疏检索(Sparse)的效果要显著高于稠密检索(Dense),这说明关键词信息对于长文档检索极为重要。
BGE-M3 模型微调
需要先安装,
- with pip
pip install -U FlagEmbedding
- from source
git clone https://github.com/FlagOpen/FlagEmbedding.git
cd FlagEmbedding
pip install -e .
模型微调的数据集格式是json line格式文件,json格式如下:
{"query": str, "pos": List[str], "neg":List[str]}
query 是查询,pos 是正文本列表,neg 是负文本列表。
模型训练:
torchrun --nproc_per_node {number of gpus} \
-m FlagEmbedding.BGE_M3.run \
--output_dir {path to save model} \
--model_name_or_path BAAI/bge-m3 \
--train_data ./toy_train_data \
--learning_rate 1e-5 \
--fp16 \
--num_train_epochs 5 \
--per_device_train_batch_size {large batch size; set 1 for toy data} \
--dataloader_drop_last True \
--normlized True \
--temperature 0.02 \
--query_max_len 64 \
--passage_max_len 256 \
--train_group_size 2 \
--negatives_cross_device \
--logging_steps 10 \
--same_task_within_batch True \
--unified_finetuning True \
--use_self_distill True
参考文献
- 1 BGE M3-Embedding: Multi-Lingual, Multi-Functionality, Multi-Granularity Text Embeddings Through Self-Knowledge Distillation
https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号