04:sqlalchemy操作数据库
目录:
- 1.1 ORM介绍(作用:不用原生SQL语句对数据库操作)
- 1.2 安装sqlalchemy并创建表
- 1.3 使用sqlalchemy对表基本操作
- 1.4 一对多外键关联
- 1.5 sqlalchemy多对多关联
1.1 ORM介绍(作用:不用原生SQL语句对数据库操作) 返回顶部
1、什么是orm(orm是一种术语而不是软件)
1)orm英文全称object relational mapping,就是对象映射关系程序
2)简单来说我们类似python这种面向对象的程序来说一切皆对象,但是我们使用的数据库却都是关系型的
3)为了保证一致的使用习惯,通过orm将编程语言的对象模型和数据库的关系模型建立映射关系
4)这样我们在使用编程语言对数据库进行操作的时候可以直接使用编程语言的对象模型进行操作就可以了,
而不用直接使用sql语言
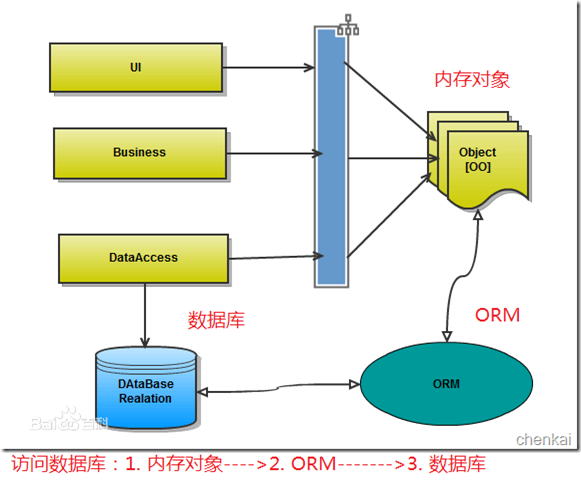
2、ORM作用
1)隐藏了数据访问细节,“封闭”的通用数据库交互,ORM的核心。他使得我们的通用数据库交互变得简单
易行,并且完全不用考虑该死的SQL语句。快速开发,由此而来
2)ORM使我们构造固化数据结构变得简单易行。
3、ORM缺点
1)无可避免的,自动化意味着映射和关联管理,代价是牺牲性能
2)现在的各种ORM框架都在尝试使用各种方法来减轻这块(LazyLoad,Cache),效果还是很显著的。
1.2 安装sqlalchemy并创建表 返回顶部
1、在win10中直接用pip3安装即可
pip3 install sqlalchemy
2、sqlalchemy可以支持多种数据库的连接使用:下面是常用的几种
MySQL-Python
mysql+mysqldb://<user>:<password>@<host>[:<port>]/<dbname>
pymysql
mysql+pymysql://<username>:<password>@<host>/<dbname>[?<options>]
MySQL-Connector
mysql+mysqlconnector://<user>:<password>@<host>[:<port>]/<dbname>
cx_Oracle
oracle+cx_oracle://user:pass@host:port/dbname[?key=value&key=value...]
更多详见: http://docs.sqlalchemy.org/en/latest/dialects/index.html
3、sqlalchemy说明
1) sqlalchemy的底层还是对mysqldb, pymysql的封装
2) 我们不用写原生SQL了,但是sqlalchemy执行的时候还是要用原生SQL
3) Sqlalchemy就是通过使用mysqldb, pymysql等来执行原生SQL语句
4、创建表
1. 使用原生sql创建表
CREATE TABLE user (
id INTEGER NOT NULL AUTO_INCREMENT,
name VARCHAR(32),
password VARCHAR(64),
PRIMARY KEY (id)
)
2. 使用sqlalchemy创建表的两种方法


from sqlalchemy import Table, MetaData, Column, Integer, String, ForeignKey from sqlalchemy.orm import mapper metadata = MetaData() user = Table('user', metadata, Column('id', Integer, primary_key=True), Column('name', String(50)), Column('fullname', String(50)), Column('password', String(12)) ) class User(object): def __init__(self, name, fullname, password): self.name = name self.fullname = fullname self.password = password mapper(User, user)
import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String #1 上面的create_engine就是用来连接数据库的引擎: #2 mysql+pymysql指定使用pymysql来执行原生SQL语句 #3 //root:1@10.1.0.51/tomdb <<==>> //用户名:密码@ip/数据库名 #4 encoding='utf-8' 指定创建的表用‘utf-8'编码(可以存中文) #5 echo=True 将执行SQL原生语句的执行细节打印出来 engine = create_engine("mysql+pymysql://root:1@10.1.0.51/oldboydb?charset=utf8") # engine = create_engine("mysql+pymysql://root:1@10.1.0.51/tomdb",encoding='utf-8', echo=True) '''第一步 建表: 创建表结构''' Base = declarative_base() #生成orm基类,执行SQL语句的类就继承Base # 这里仅仅是声明如何定义,到这一步并未执行 class User(Base): __tablename__ = 'user' #表名 id = Column(Integer, primary_key=True) #Column是导入的模块 name = Column(String(32)) #String也是导入的模块 password = Column(String(64)) def __repr__(self): #如果想让它变的可读,只需在定义表的类下面加上这样的代码 return "<id:%s name:%s password:%s>\n"%(self.id,self.name,self.password) Base.metadata.create_all(engine) #创建表结构 #1 Base是上面定义的orm父类,metadata.create_all是他的方法 #2 engine是连接数据库的引擎 #3 执行create_all(engine)将会执行所有继承Base的语句
#! -*- coding:utf8 -*- import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker '''第一步:连接数据库''' engine = create_engine("mysql+pymysql://root:1@127.0.0.1/bsp?charset=utf8") # engine = create_engine("mysql+pymysql://root:1@127.0.0.1/tomdb",encoding='utf-8', echo=True) '''附加: 无论是增删改查都要先创建与数据库的会话session class''' #创建与数据库的会话session class ,注意,这里返回给session的是个class类,不是实例 Session_class = sessionmaker(bind=engine) #创建用于数据库session的类 session = Session_class() #这里才是生成session实例可以理解为cursor '''第二步:操作数据库''' #1、查看mysql中有哪些数据库 dbs=session.execute('show databases;').fetchall() #2、切换当前数据库 session.execute('use bsp;') #3、查询时过滤出第一条 row1=session.execute('select * from relations_department where Id>1;').first() fid_id = row1.fid_id #4、一对多关联查询: 根据上面查询的父部门id 可以找到父部门信息 row2=session.execute('select * from relations_department where Id=%s;'%fid_id).first() print row2.name # 政府事业部
1.3 使用sqlalchemy对表基本操作 返回顶部
import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String engine = create_engine("mysql+pymysql://root:1@127.0.0.1/tomdb?charset=utf8") # engine = create_engine("mysql+pymysql://root:1@127.0.0.1/tomdb",encoding='utf-8', echo=True) #1 上面的create_engine就是用来连接数据库的引擎: #2 mysql+pymysql指定使用pymysql来执行原生SQL语句 #3 //root:1@127.0.0.1/tomdb <<==>> //用户名:密码@ip/数据库名 #4 encoding='utf-8' 指定创建的表用‘utf-8'编码(可以存中文) #5 echo=True 将执行SQL原生语句的执行细节打印出来
'''第一步 建表: 创建表结构''' Base = declarative_base() #生成orm基类,执行SQL语句的类就继承Base class User(Base): __tablename__ = 'user' #表名 id = Column(Integer, primary_key=True) #Column是导入的模块 name = Column(String(32)) #String也是导入的模块 password = Column(String(64)) def __repr__(self): #如果想让它变的可读,只需在定义表的类下面加上这样的代码 return "<id:%s name:%s password:%s>\n"%(self.id,self.name,self.password) Base.metadata.create_all(engine) #创建表结构 #1 Base是上面定义的orm父类,metadata.create_all是他的方法 #2 engine是连接数据库的引擎 #3 执行create_all(engine)将会执行所有继承Base的语句
'''附加: 无论是增删改查都要先创建与数据库的会话session class''' from sqlalchemy.orm import sessionmaker #创建与数据库的会话session class ,注意,这里返回给session的是个class类,不是实例 Session_class = sessionmaker(bind=engine) #创建用于数据库session的类 Session = Session_class() #这里才是生成session实例可以理解为cursor
'''第二步 增1: 向表中添加单条数据''' user_obj = User(name="tom",password="123456") #生成你要创建的数据对象,此时还没创建对象呢,不信你打印一下id发现还是None Session.add(user_obj) #把要创建的数据对象(user_obj)添加到这个session里, 一会统一创建 print(user_obj.name,user_obj.id) #此时也依然还没创建 Session.commit() #到此才统一提交,创建数据,但是为了演示后面内容可以放到最后面 '''第二步 增2: 向表中添加多条数据''' user_obj1 = User(name='tom',password='123456') user_obj2 = User(name='jack',password='123456') Session.add_all([user_obj1,user_obj2]) Session.commit()
#1、删除单条数据 Session.query(User).filter((User.id == 1)).delete() Session.commit() #2、删除多条数据 Session.query(User).filter((User.id.in_([4,5,6]))).delete(synchronize_session=False) session.commit()
# 先搜索出来,然后赋值就可以修改数据了 #<id: 2 name: tom password:123456> data = Session.query(User).filter(User.id>1).filter(User.id<3).first() data.name = 'new name' data.password = '123456' Session.commit()
#1 打印user表中所有数据 ret = Session.query(User).all() #user表中所有数据 #2 打印user表中所有name=jack的用户 ret = Session.query(User).filter_by(name='jack').all() #3 打印user表中第一条name=jack的用户 ret = Session.query(User).filter_by(name='jack').first() #user表中所有name=jack的数据 #4 单条件查询 data4 = Session.query(User).filter(User.id<100).all() data5 = Session.query(User).filter(User.id==2).all() data6 = Session.query(User).filter_by(id=2).all() #5 filter多条件查询 data7 = Session.query(User).filter(User.id>1).filter(User.id<3).all() ret = Session.query(User).filter(User.id > 1, User.name == 'jack').all() ret = Session.query(User).filter(User.id.between(1, 3), User.name == 'jack').all() ret = Session.query(User).filter(User.id.in_([3,4])).all() from sqlalchemy import and_, or_ ret = Session.query(User).filter(and_(User.id > 3, User.name == 'jack')).all() ret = Session.query(User).filter(or_(User.id < 2, User.name == 'jack')).all()
'''第1步 查: 通配符 ''' ret1 = Session.query(User).filter(User.name.like('j%')).all() '''第2步 查: 限制 ''' ret = Session.query(User)[0:3] #这里过滤id但是从0开始计算[0:3]=id从1到4 '''第3步: 排序''' ret = Session.query(User).order_by(User.id.desc()).all() ret = Session.query(User).order_by( User.id.asc()).all() ret = Session.query(User).order_by(User.name.desc(), User.id.asc()).all()
ret = Session.query(User).group_by(User.name).all() #有多个同名的只会打印id靠前的yige ret = Session.query(User.name,func.count(User.name)).group_by(User.name).all() #[('jack', 2), ('new name', 1), ('tom', 3)] ret = Session.query( func.max(User.id), func.sum(User.id), func.min(User.id)).group_by(User.name).all()
fake_user = User(name='Rain', password='12345') #创建一个用户 Session.add(fake_user) Session.rollback() #此时你rollback一下 Session.commit()
1.4 一对多外键关联 返回顶部
import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String,DATE,ForeignKey from sqlalchemy.orm import sessionmaker,relationship engine = create_engine("mysql+pymysql://root:1@127.0.0.1/tomdb?charset=utf8") '''第一步: 创建表结构''' Base = declarative_base() #生成orm基类,执行SQL语句的类就继承Base class User(Base): __tablename__ = 'user' #表名 id = Column(Integer, primary_key=True) name = Column(String(32),nullable=False,unique=True) register_date = Column(DATE,default='2014-05-21') user_type_id = Column(Integer,ForeignKey("user_type.id",ondelete='CASCADE')) #这里和UserType表的id字段关联 user_type = relationship("UserType",backref="user", cascade="all, delete-orphan",single_parent=True) #仅仅是内存中关联关系 def __repr__(self): return "<id:%s name:%s UserType:%s>\n"%(self.id,self.name,self.user_type) class UserType(Base): __tablename__ = "user_type" id = Column(Integer, primary_key=True) name = Column(String(32),unique=True,nullable=False) def __repr__(self): return "<用户类型:%s>"%self.name Base.metadata.create_all(engine) #创建表结构 #注:一对多中,sqlalchemy 联级删除必须要设置下面参数 # ForeignKey中添加:ondelete='CASCADE' # relationship关联中添加:cascade="all, delete-orphan",single_parent=True
import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy import Column, Integer, String,DATE,ForeignKey from sqlalchemy.orm import sessionmaker,relationship engine = create_engine("mysql+pymysql://root:1@127.0.0.1/tomdb?charset=utf8") '''第一步: 创建表结构''' Base = declarative_base() #生成orm基类,执行SQL语句的类就继承Base class User(Base): __tablename__ = 'user' #表名 id = Column(Integer, primary_key=True) name = Column(String(32),nullable=False,unique=True) register_date = Column(DATE,default='2014-05-21') user_type_id = Column(Integer,ForeignKey("user_type.id")) #这里和UserType表的id字段关联 user_type = relationship("UserType",backref="user") #仅仅是内存中关联关系 def __repr__(self): return "<id:%s name:%s UserType:%s>\n"%(self.id,self.name,self.user_type) class UserType(Base): __tablename__ = "user_type" id = Column(Integer, primary_key=True) name = Column(String(32)) def __repr__(self): return "<用户类型:%s>"%self.name Base.metadata.create_all(engine) #创建表结构
from sqlalchemy.orm import sessionmaker from orm_test import models #创建与数据库的会话session class ,注意,这里返回给session的是个class类,不是实例 Session_class = sessionmaker(bind=models.engine) #创建用于数据库session的类 session = Session_class() #这里才是生成session实例可以理解为cursor #1、创建用户类型 user_type_obj1 = models.UserType(name='内部员工') user_type_obj2 = models.UserType(name='外部用户') session.add_all([user_type_obj1,user_type_obj2]) session.commit() #到此才统一提交,创建数据:只有执行这一步增删改才会真正写入硬盘 #2、添加一对多数据的两种方法 user_type_obj = session.query(models.UserType).filter(models.UserType.name=='内部员工').first() user1 = models.User(name="zhangsan",register_date="2014-05-21",user_type=user_type_obj) # 法1 user2 = models.User(name="lisi",register_date="2014-03-21",user_type_id=1) # 法2 user3 = models.User(name="wangwu",register_date="2014-02-21",user_type_id=2) session.add_all([user1,user2,user3]) session.commit() #到此才统一提交,创建数据:只有执行这一步增删改才会真正写入硬盘
from sqlalchemy.orm import sessionmaker from orm_test import models Session_class = sessionmaker(bind=models.engine) session = Session_class() #先在两表中获取一条数据 user_obj = session.query(models.User).filter(models.User.name=='zhangsan').first() user_type_obj = session.query(models.UserType).filter(models.UserType.name=='内部员工').first() #1、正向查找:查找张三用户的用户类型 print('zhangsan用户类型:',user_obj.user_type) #2、反向查找:查找用户类型为"内部员工",的有哪些 print('内部员工有哪些:',user_type_obj.user)
from sqlalchemy.orm import sessionmaker from orm_test import models Session_class = sessionmaker(bind=models.engine) session = Session_class() #先在两表中获取一条数据 user_obj = session.query(models.User).filter(models.User.name=='zhangsan').first() user_obj2 = session.query(models.User).filter(models.User.name=='lisi').first() user_type_obj = session.query(models.UserType).filter(models.UserType.name=='外部用户').first() #1、正向修改的两种方法:将zhangsan的用户类型修改为 "外部用户" user_obj.user_type = user_type_obj # 法1 user_obj.user_type_id = user_type_obj.id # 法2 session.commit() #2、反向修改方法:将"外部用户"类型中的用户修改成只有:zhangsan、lisi user_type_obj.user = [user_obj,user_obj2] session.commit()
from sqlalchemy.orm import sessionmaker from orm_test import models #创建与数据库的会话session class ,注意,这里返回给session的是个class类,不是实例 Session_class = sessionmaker(bind=models.engine) #创建用于数据库session的类 session = Session_class() #这里才是生成session实例可以理解为cursor #1、删除指定用户 session.query(models.User).filter(models.User.name=='zhangsan').delete() session.commit() #2、sqlalchemy 联级删除:删除UserType表中类型"内部员工",在user表中所有类型为"内部员工"的用户全部删除 user_type_obj = session.query(models.UserType).filter(models.UserType.name=='内部员工').delete() session.commit()
1.5 sqlalchemy多对多关联 返回顶部
from sqlalchemy import create_engine from sqlalchemy.ext.declarative import declarative_base from sqlalchemy.orm import relationship from sqlalchemy import Table, Column, Integer,String,DATE, ForeignKey engine = create_engine("mysql+pymysql://root:1@127.0.0.1/tomdb?charset=utf8") Base = declarative_base() #生成orm基类,执行SQL语句的类就继承Base '''1 创建关联表: 第三张表book_m2m_author:用来关联下面的authors和books表''' # 这张关系表不必使用类创建可以直接使用Table创建,因为这张表创建后不必手动向表中插数据 # 对这张表的维护完全是由ORM自己维护的 # 表中仅有两个字段:book_id关联books表的id,author_id关联authors表的id # 这张表创建完成后必须要在books表和authors表中指定要到book_m2m_author表查询 book_m2m_author = Table('book_m2m_author', Base.metadata, Column('book_id',Integer,ForeignKey('books.id')), Column('author_id',Integer,ForeignKey('authors.id')), ) '''2 创建books表: 用来存储所有作者的名字 ''' class Book(Base): __tablename__ = 'books' id = Column(Integer,primary_key=True) name = Column(String(64)) pub_date = Column(DATE) authors = relationship('Author',secondary=book_m2m_author,backref='books') # books通过authors关联Author表,Book通过字段secondary去查第三张表:book_m2m_author # backref='books'用来反向查一个作者有多少本书 def __repr__(self): return self.name '''3 创建authors表 用来存储所有的书 ''' class Author(Base): __tablename__ = 'authors' id = Column(Integer, primary_key=True) name = Column(String(32)) def __repr__(self): return self.name Base.metadata.create_all(engine)
from orm_test import models from sqlalchemy.orm import sessionmaker Session_class = sessionmaker(bind=models.engine) session = Session_class() '''第一步:向books表和authors表中分别插入三条数据''' #1、向books表插入三条书名记录 b1 = models.Book(name="python基础教程",pub_date="2014-05-02") b2 = models.Book(name="从删库到跑路",pub_date="2014-05-02") b3 = models.Book(name="wireshark网路分析实战",pub_date="2014-05-02") #2、向authors表插入三条作者记录 a1 = models.Author(name="Tom") a2 = models.Author(name="Jack") a3 = models.Author(name="Fly") #3、这里指定执行上面的创建表命令 session.add_all([b1,b2,b3,a1,a2,a3]) session.commit() '''第二步:第三张表:book_m2m_author 中创建 作者与书籍的对应关系''' b1 = session.query(models.Book).filter(models.Book.name=='python基础教程').first() b2 = session.query(models.Book).filter(models.Book.name=='从删库到跑路').first() b3 = session.query(models.Book).filter(models.Book.name=='wireshark网路分析实战').first() a1 = session.query(models.Author).filter(models.Author.name=='Tom').first() a2 = session.query(models.Author).filter(models.Author.name=='Jack').first() a3 = session.query(models.Author).filter(models.Author.name=='Fly').first() b1.authors = [a1,a2] # 'python基础教程'这本书的作者有:"Tom", "Jack" a1.books = [b1,b2,b3] # 作者 "Tom" 出版的书有:python基础教程、从删库到跑路、wireshark网路分析实战 session.commit()
from orm_test import models from sqlalchemy.orm import sessionmaker Session_class = sessionmaker(bind=models.engine) session = Session_class() b1 = session.query(models.Book).filter(models.Book.name=='python基础教程').first() a1 = session.query(models.Author).filter(models.Author.name=='Tom').first() #1、正向查找: "python基础教程" 这本书的所有作者 print( b1.authors ) # [Tom, Jack] #2、反向查找:作者"Tom" 出版的所有书 print( a1.books ) # [python基础教程, 从删库到跑路, wireshark网路分析实战]
from orm_test import models from sqlalchemy.orm import sessionmaker Session_class = sessionmaker(bind=models.engine) session = Session_class() b1 = session.query(models.Book).filter(models.Book.name=='python基础教程').first() b2 = session.query(models.Book).filter(models.Book.name=='从删库到跑路').first() b3 = session.query(models.Book).filter(models.Book.name=='wireshark网路分析实战').first() a1 = session.query(models.Author).filter(models.Author.name=='Tom').first() a2 = session.query(models.Author).filter(models.Author.name=='Jack').first() a3 = session.query(models.Author).filter(models.Author.name=='Fly').first() '''1、正向修改''' #1.1 将书籍b1的作者从[Tom, Jack] 修改成只有 [Tom] print(b1.authors) # [Tom, Jack] b1.authors = [a1] print(b1.authors) # [Tom] session.commit() #1.2 通过books表将authors表中作者 "Tom" 名字改成 "Tom New" b1.authors[0].name = 'Tom' session.commit() '''2、反向修改''' #2.1 将作者 "Tom" 出版的书籍修改成 [python基础教程, 从删库到跑路] print(a1.books) # [python基础教程, 从删库到跑路, wireshark网路分析实战] a1.books = [b1,b2] print(a1.books) # [python基础教程, 从删库到跑路] session.commit() #2.2 通过authors表将书籍 "python基础教程"名字修改成 "python基础教程第二版" a1.books[0].name = "python基础教程第二版" session.commit()
from orm_test import models from sqlalchemy.orm import sessionmaker Session_class = sessionmaker(bind=models.engine) session = Session_class() b1 = session.query(models.Book).filter(models.Book.name=='python基础教程').first() a1 = session.query(models.Author).filter(models.Author.name=='Tom').first() #1、正向删除: 将书籍b1的作者 Tom 删除(只是删除book_m2m_author表中的记录,不会删除authors表中的 'Tom') print(b1.authors) # [Tom, Jack] b1.authors.remove(a1) print(b1.authors) # [Jack] session.commit() #2、反向删除: print(a1.books) # [python基础教程, 从删库到跑路, wireshark网路分析实战] a1.books.remove(b1) # [从删库到跑路, wireshark网路分析实战] print(a1.books) #3、多对多联级删除: 删除作者时,会把这个作者跟所有书的关联关系数据也自动删除(book_m2m_author中的对应信息) session.delete(a1) session.commit()
1.6 sqlalchemy执行原生SQL语句
1、执行原生SQL语句
#! -*- coding:utf8 -*- import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker '''第一步:连接数据库''' engine = create_engine("mysql+pymysql://root:1@127.0.0.1/bsp?charset=utf8") # engine = create_engine("mysql+pymysql://root:1@127.0.0.1/tomdb",encoding='utf-8', echo=True) '''附加: 无论是增删改查都要先创建与数据库的会话session class''' #创建与数据库的会话session class ,注意,这里返回给session的是个class类,不是实例 Session_class = sessionmaker(bind=engine) #创建用于数据库session的类 session = Session_class() #这里才是生成session实例可以理解为cursor '''第二步:操作数据库''' #1、查看mysql中有哪些数据库 dbs=session.execute('show databases;').fetchall() #2、切换当前数据库 session.execute('use bsp;') #3、查询时过滤出第一条 row1=session.execute('select * from relations_department where Id>1;').first() fid_id = row1.fid_id #4、一对多关联查询: 根据上面查询的父部门id 可以找到父部门信息 row2=session.execute('select * from relations_department where Id=%s;'%fid_id).first() print row2.name # 政府事业部
2、找到当前数据库中所有非空表
#! -*- coding:utf8 -*- import sqlalchemy from sqlalchemy import create_engine from sqlalchemy.orm import sessionmaker '''第一步连接数据库''' engine = create_engine("mysql+pymysql://root:1@127.0.0.1/bsp?charset=utf8") Session_class = sessionmaker(bind=engine) #创建用于数据库session的类 session = Session_class() #这里才是生成session实例可以理解为cursor '''第二步:操作数据库''' #1、查看mysql中有哪些数据库 dbs=session.execute('show databases;').fetchall() #2、切换当前数据库 session.execute('use bsp;') #3、查看当前数据库中有哪些表 tables = session.execute('show tables;') #4、找到当前数据库中所有非空表 tb_list = [] for tb in tables: tb_name = tb[0] rows = session.execute('select * from %s;'%tb_name) row_count = rows.rowcount # 当前表中数据条数 if row_count > 1: tb_list.append(tb_name) print tb_list
作者:学无止境
出处:https://www.cnblogs.com/xiaonq
生活不只是眼前的苟且,还有诗和远方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号