12.协同过滤算法 预测和推荐
1.1 协同过滤算法介绍
1.什么是协同过滤算法
1. 协同过滤推荐算法是诞生最早,并且较为著名的推荐算法,主要的功能是预测和推荐。
2. 算法通过对用户历史行为数据的挖掘发现用户的偏好,基于不同的偏好对用户进行群组划分并推荐品味相似的商品。
3. 协同过滤推荐算法分为两类,分别是基于用户的协同过滤算法(user-based collaboratIve filtering),和基于物品的协同过滤算法(item-based collaborative filtering)。
4. 简单的说就是:人以类聚,物以群分。下面我们将分别说明这两类推荐算法的原理和实现方法。
2.基于用户的协同过滤算法
2. 假设有甲和乙两名用户,有a、b、c三款产品。
3. 如果甲和乙都购买了a和b这两种产品,我们可以假定甲和乙有近似的购物品味。
4. 当甲购买了产品c而乙还没有购买c的时候,我们就可以把c也推荐给乙。
举例:

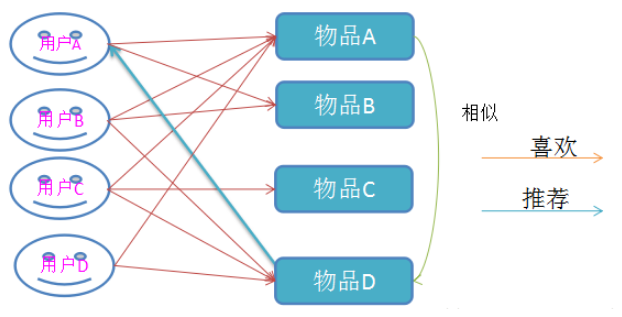
3.基于物品的协同过滤算法
举例:
1)物品组合(A,D)被同时偏好出现的次数最多,因而可以认为A/D两件物品的相似度最高
2)从而,可以为选择了A物品的用户推荐D物品
1.2 欧几里德距离评价
1.欧几里得度量 是什么?
1. 欧几里得度量(euclidean metric)(也称欧氏距离)是一个通常采用的距离定义
2. 指在m维空间中两个点之间的真实距离,或者向量的自然长度(即该点到原点的距离)。
3. 在二维和三维空间中的欧氏距离就是两点之间的实际距离

4. n维空间的公式

2. 借助“欧几里得度量” 寻找偏好相似的用户原理
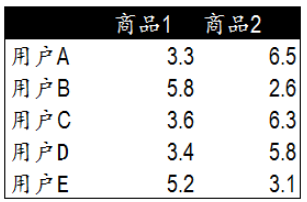
1)在示例中,5个用户分别对两件商品进行了评分。
2)这里的分值可能表示真实的购买,也可以是用户对商品不同行为的量化指标。
3)例如,浏览商品的次数,向朋友推荐商品,收藏,分享,或评论等等。
4)这些行为都可以表示用户对商品的态度和偏好程度。
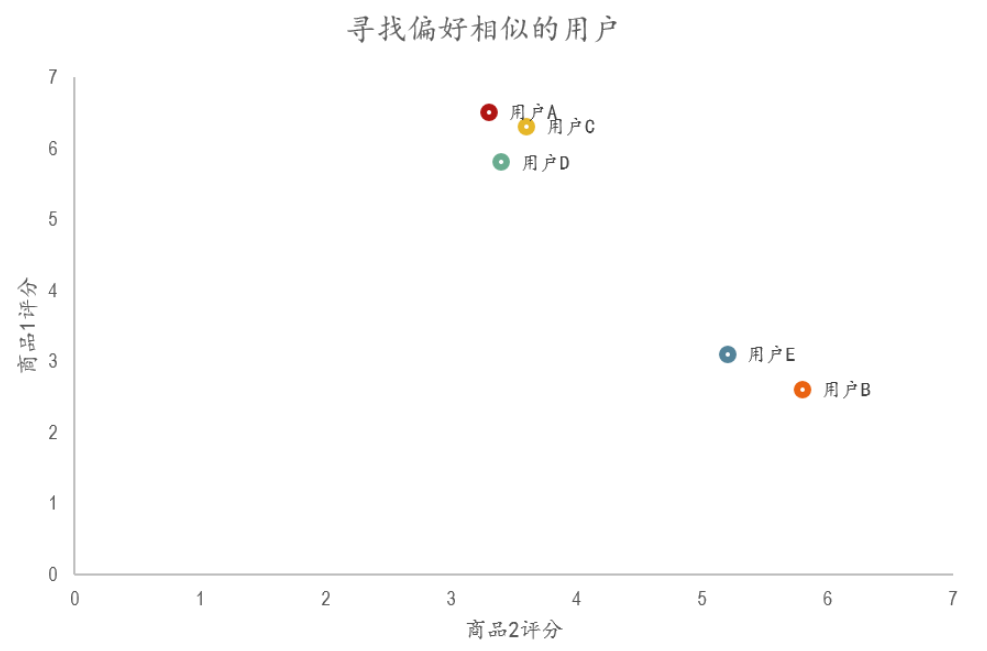
5)在散点图中,Y轴是商品1的评分,X轴是商品2的评分,通过用户的分布情况可以发现,A,C,D三个用户距离较近。
6)用户A(3.3 6.5)和用户C(3.6 6.3),用户D(3.4 5.8)对两件商品的评分较为接近。而用户E和用户B则形成了另一个群体。
7)散点图虽然直观,但无法投入实际的应用,也不能准确的度量用户间的关系。
8)因此我们需要通过数字对用户的关系进行准确的度量,并依据这些关系完成商品的推荐。
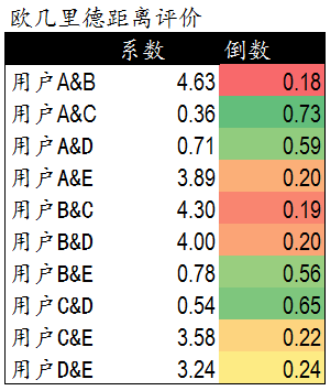
1. 通过公式我们获得了5个用户相互间的欧几里德系数,也就是用户间的距离。
2. 系数越小表示两个用户间的距离越近,偏好也越是接近。
3. 不过这里有个问题,太小的数值可能无法准确的表现出不同用户间距离的差异,因此我们对求得的系数取倒数,使用户间的距离约接近,数值越大。
4. 在下面的表格中,可以发现,用户A&C用户A&D和用户C&D距离较近。同时用户B&E的距离也较为接近。与我们前面在散点图中看到的情况一致。
1.3 使用协同过滤算法简单测试
第一步,将数据读取并格式化为字典形式,便于解析
第二步:借助"欧几里德"算法计算用户相似度
第三步:计算某个用户与其他用户的相似度
第四步:根据相似度最高的用户喜好商品排序,把相似度最高用户的喜好推荐给当前用户


1,华为p30,2.0 1,三星s10,5.0 1,小米9,2.6 2,华为p30,1.0 2,vivo,5.0 2,htc,4.6 3,魅族,2.0 3,iphone,5.0 3,pixel2,2.6
#!/usr/bin/env python3 # -*- coding: utf-8 -*- with open('./phone.txt', 'r', encoding='utf-8') as fp: content = fp.readlines() # 第一步,将数据读取并格式化为字典形式,便于解析 def parse_data(): with open('./phone.txt','r',encoding='utf-8') as fp: content = fp.readlines() # 将用户、评分、和手机写入字典data data = {} for line in content: line = line.strip().split(',') #如果字典中没有某位用户,则使用用户ID来创建这位用户 if not line[0] in data.keys(): data[line[0]] = {line[1]:line[2]} #否则直接添加以该用户ID为key字典中 else: data[line[0]][line[1]] = line[2] return data data = parse_data() ''' { "1":{ "华为p30":"2.0", "三星s10":"5.0", "小米9":"2.6" }, "2":{ "华为p30":"1.0", "vivo":"5.0", "htc":"4.6" }, "3":{ "魅族":"2.0", "iphone":"5.0", "pixel2":"2.6" } } ''' # 第二步:借助"欧几里德"算法计算用户相似度 from math import * def Euclid(user1, user2): # 取出两位用户购买过的手机和评分 user1_data = data[user1] user2_data = data[user2] distance = 0 # 找到两位用户都购买过的手机,并计算欧式距离 for key in user1_data.keys(): if key in user2_data.keys(): # 注意,distance越大表示两者越相似 distance += pow(float(user1_data[key]) - float(user2_data[key]), 2) return 1 / (1 + sqrt(distance)) # 这里返回值越小,相似度越大 # 第三步:计算某个用户与其他用户的相似度 def top_simliar(userID): res = [] for userid in data.keys(): #排除与自己计算相似度 if not userid == userID: simliar = Euclid(userID,userid) res.append((userid,simliar)) # res = # [('2', 0.5), ('3', 1.0)] res.sort(key=lambda val:val[1]) return res # 第四步:根据相似度最高的用户喜好商品排序,把相似度最高用户的喜好推荐给当前用户 def recommend(userid): #相似度最高的用户 top_sim_user = top_simliar(userid)[0][0] # top_sim_user=2 找到相似度最高的用户ID #相似度最高的用户的购买记录 items = data[top_sim_user] # items = {'华为p30': '1.0', 'vivo': '5.0', 'htc': '4.6'} recommendations = [] #筛选出该用户未购买的手机并添加到列表中 for item in items.keys(): if item not in data[userid].keys(): recommendations.append((item,items[item])) recommendations.sort(key=lambda val:val[1],reverse=True)#按照评分排序 return recommendations if __name__ == '__main__': # 找到与用户id为1的用户相似度最高的用户 print(recommend('1')) # [('vivo', '5.0'), ('htc', '4.6')]
作者:学无止境
出处:https://www.cnblogs.com/xiaonq
生活不只是眼前的苟且,还有诗和远方。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号