

【202501】REGMIX:将数据混合作为回归任务用于语言模型预训练
-
值得关注的:
- 数据混合过程能用于制备语料库或者数据集吗?
- 关键假设:数据混合排名的不变性,这个假设让作者通过1M小模型的训练来收集数据混合的样本,训练混合预测器后在1B模型上验证。作者的实验使用了1M、60M和1B模型来验证假设,更大规模的模型是否有变化。
- 作者的发现是数据混合的部分规律难以直观理解,说明了模型预测的作用。
- 实验基本上基于数据源的混合完成,更细粒度的实验也有但是对样本的重新聚类是个麻烦的事情。
- 相关工作中提到本文方法是一种离线选择,还有在训练过程中的在线选择。
论文基本信息
-
标题:REGMIX: DATA MIXTURE AS REGRESSION FOR LANGUAGE MODEL PRE-TRAINING
-
标题中文翻译:REGMIX:将数据混合作为回归任务用于语言模型预训练
-
作者:Qian Liu, Xiaosen Zheng, Niklas Muennighoff, Guangtao Zeng, Longxu Dou, Tianyu Pang, Jing Jiang, Min Lin
-
发表时间:2025年1月23日(根据论文中的版本信息)
-
发表地址:ICLR 2025(国际学习表征会议)
-
互联网能查到的资料:
- 论文发表在arXiv上,预印本版本为 https://arxiv.org/pdf/2407.01492。
- 论文代码已开源,可在GitHub上找到:https://github.com/sail-sg/regmix。
-
摘要中文翻译:
大型语言模型的预训练中,数据混合对模型性能有着显著的影响,然而如何确定有效的数据混合方式仍然是一个悬而未决的问题。为此,我们提出了REGMIX方法,通过将数据混合问题转化为回归任务,从而自动识别出高性能的数据混合方案。REGMIX先训练许多小型模型在多样化的数据混合上,接着利用回归方法来预测未尝试过的数据混合的性能表现,并最终将预测出的最佳数据混合方案应用于训练计算资源需求大得多的大型模型。
为了对REGMIX进行实证验证,我们训练了512个拥有100万参数的小模型,每个模型在10亿个token上进行训练,以此来拟合回归模型并预测出最佳的数据混合方案。随后,我们使用这一预测出的最佳混合方案,训练了一个拥有10亿参数的大型模型,训练了250亿个token(模型规模比其他混合方案的模型大1000倍,训练时长也增加了25倍)。结果表明,该模型在64个不同数据混合方案的10亿参数候选模型中表现最佳。此外,REGMIX在涉及多达70亿参数模型、训练1000亿个token的实验中,始终优于人类选择的数据混合方案,同时仅使用了DoReMi方法10%的计算资源,就达到了甚至超过了其性能表现。
我们的实验还揭示了以下几点:(1)数据混合对下游任务的性能有着显著的影响;(2)与普遍认为高质量的数据(如维基百科)相比,普通的网络语料库(例如CommonCrawl)与下游任务性能的正相关性更强;(3)不同领域之间的交互方式复杂多样,常常与常识相悖,这凸显了像REGMIX这样自动化方法的必要性;(4)数据混合的效应超越了简单的规模定律。我们的代码已开源,可在 https://github.com/sail-sg/regmix 获取。
REGMIX 论文速读报告
研究背景
在大规模语言模型(LLM)的预训练中,数据混合的选择对模型性能有显著影响。然而,随着数据规模和多样性的增加,如何高效地选择最优的数据混合成为一个关键问题。以往的方法通常依赖于手动选择或基于启发式规则,这些方法不仅耗时,而且难以扩展到大规模数据集。因此,本文提出了REGMIX方法,通过将数据混合问题转化为回归任务,自动预测最优的数据混合方案。
研究方法
REGMIX的核心思想是利用小规模模型在有限数据上的训练结果,通过回归模型预测大规模模型在不同数据混合下的性能,从而选择最优的数据混合方案。具体步骤如下:
- 训练小规模代理模型:使用1M参数的小模型在不同的数据混合上训练,并记录其性能。
- 拟合回归模型:以数据混合比例为特征,以目标性能指标(如验证损失)为标签,训练线性回归或LightGBM模型。
- 预测最优数据混合:利用回归模型预测大规模模型在不同数据混合下的性能,选择预测性能最优的混合方案。
- 训练大规模模型:使用预测出的最优数据混合方案训练大规模模型(如1B参数模型)。
(1M参数模型是什么概念,BERT-Base是参数规模是110M或者0.11B。所以在如此小规模模型上得出的数据混合规律是否适配1B模型?又是否能扩展到更大模型?)
实验设计
- 数据集:使用Pile数据集,包含多个不同领域的子数据集。
- 模型规模:实验涉及1M、60M、1B和7B参数的模型。
- 训练数据量:从1B到100B tokens不等。
- 性能指标:主要关注验证损失、下游任务性能(如Winogrande、QQP等)。
关键结论
-
性能提升:REGMIX在多个下游任务上显著优于人类选择的数据混合方案,平均性能提升约2%。
- (相比人类混合方案2%的性能提升太少。)
-
数据混合的重要性:数据混合对模型性能的影响显著,不同混合方案的性能差异可达14.6%。
-
网络语料库的优势:与传统认为高质量的数据(如维基百科)相比,普通网络语料库(如CommonCrawl)与下游任务性能的正相关性更强。
- (还得看具体的下游任务是什么。)
-
复杂领域交互:不同领域之间的交互复杂,常常与直觉相悖,自动方法(如REGMIX)比手动选择更有效。
-
超越规模定律:REGMIX能够捕捉数据混合的复杂性,其效果超越了简单的规模定律。
方法优势
-
高效性:REGMIX通过小规模模型预测大规模模型的性能,大大减少了计算资源的消耗。
-
可扩展性:该方法可以轻松扩展到更大规模的模型和数据集。
- (真的能轻松扩展到更大模型但是效果一致吗?)
-
自动化:减少了人工干预,提高了数据混合选择的效率和准确性。
局限性
- 模型规模限制:虽然REGMIX在1B和7B模型上表现出色,但其在更大规模模型(如10B以上)的效果尚未验证。
- 数据集依赖性:该方法的效果可能依赖于特定的数据集和领域分布。
- 计算资源:尽管REGMIX减少了计算资源的消耗,但训练小规模模型和拟合回归模型仍需要一定的计算能力。
总结
REGMIX为语言模型预训练中的数据混合选择提供了一种高效、自动化的解决方案。通过将数据混合问题转化为回归任务,REGMIX能够有效预测最优的数据混合方案,并在多个下游任务上验证了其优越性。该方法不仅提高了模型性能,还为大规模语言模型的预训练提供了一种可扩展的策略。
1 引言
大规模公共数据集的可用性是创建大型语言模型(LLMs)的关键因素。大多数数据来自互联网,包括学术论文(例如 arXiv)、书籍(例如 Project Gutenberg)和代码(例如 GitHub)。对于第一个大型语言模型之一 GPT-3 的创建,作者们已经认识到选择最佳训练数据的重要性,因此他们决定对 Wikipedia 进行上采样,因为它被认为具有高质量。然而,这种手动数据选择方法不可扩展,可能导致次优选择。随着用于 LLM 预训练的数据的规模和多样性不断增加,确定最佳数据混合变得更加具有挑战性。这引发了关键的研究问题:我们如何以一种可扩展且高效的方式选择最佳的数据混合?
先前的研究(Xie et al., 2023a; Fan et al., 2023; Albalak et al., 2023)使用小型模型(“代理模型”)来预测大型语言模型的领域权重。这些研究训练代理模型时使用了大量 token(例如 1000 亿),有时甚至与训练 LLMs 所用的 token 数量相同,并通过监控训练动态来动态调整数据分配策略。然而,随着 LLM 预训练所用的训练数据不断增加,这些方法变得低效。例如,训练像 Llama-3 这样的当前模型的代理模型需要使用高达 15 万亿 tokens(AI, 2024),这可能过于昂贵且速度太慢,不值得尝试。
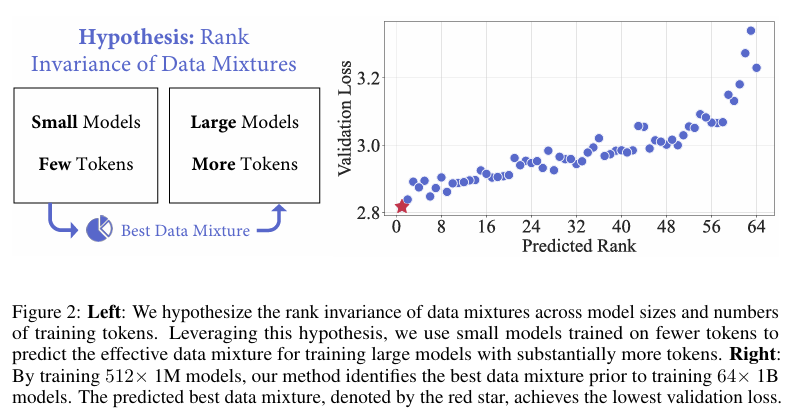
在本研究中,我们认为在有限的 token 集合上训练小型模型足以预测 LLM 训练的有效数据混合。我们的关键假设是数据混合的排名不变性,即假设在不同模型大小和训练 token 数量下,数据混合对模型性能的影响排名是一致的。基于这一假设,关键挑战在于从近乎无限数量的潜在数据混合中发现排名最高的数据混合。为此,我们将数据混合选择视为一个回归任务。而不是穷尽地训练小型模型以涵盖每一种可能的混合,我们只训练一组小型模型,每个模型都有一个独特的数据混合。根据这些模型的性能及其混合情况,我们拟合一个回归模型,以预测其他数据混合的性能。与以往工作相比,我们的方法显著更具可扩展性,因为它允许并行训练小型代理模型,而不是长时间训练单个模型。此外,回归模型提供了对领域交互的见解,有助于理解和数据策划。
(对于数据混合排名不变性的假设是前提,但是作者的假设依据是什么?是因为实验中百万参数模型训练出的混合预测器能够为十亿参数模型决定数据混合方案吗?)
为了验证 REGMIX,我们训练了具有 100 万和 10 亿参数的模型,使用不同的数据混合。通过训练 512 个具有 100 万参数的模型,每个模型训练 10 亿 tokens,我们能够预测出在 64 个模型中表现最佳的数据混合,这些模型的大小是前者的 1000 倍(10 亿参数),并且训练时间更长(250 亿 tokens),如图 2 所示。此外,使用 REGMIX 优化的数据混合比人工选择表现更好,并且在计算量更少的情况下达到了与旗舰方法 DoReMi(Xie et al., 2023a)相当的性能,同时允许并行训练。我们还发现,数据混合对下游性能有显著影响,导致单任务性能的最大差异可达 14.6%;普通网络语料库(例如 CommonCrawl)而不是像 Wikipedia 这样的“高质量”数据,在跨下游任务的性能提升方面表现出最强的正相关性;领域之间的交互非常复杂,常常违背直觉,这突显了像 REGMIX 这样的自动化方法的必要性;数据混合效应超越了扩展定律,REGMIX 通过考虑所有领域来捕捉这种复杂性。
2 相关工作
数据选择和混合涉及策划数据以优化某些目标,通常是模型性能(Koh & Liang, 2017; Albalak et al., 2024)。以往的方法可以分为以下几类:(1)Token 级别选择 是最细粒度的选择,涉及过滤 token(Lin et al., 2024)。 (2)样本级别选择 是关于选择单个训练样本。它通常用于选择微调数据(Thakkar et al., 2023; Das & Khetan, 2023; Xie et al., 2023b; Engstrom et al., 2024; Xia et al., 2024; Liu et al., 2024; Bukharin & Zhao, 2023; Kang et al., 2024; Mekala et al., 2024; Sachin Parkar et al., 2024; Yang et al., 2024b)。对于预训练 LLMs,大多数方法依赖于启发式方法(Rae et al., 2021; Sharma et al., 2024; Soldaini et al., 2024; Li et al., 2024),但也有一些使用优化算法的学习方法(Chen et al., 2024; Mindermann et al., 2022; Shao et al., 2024; Yu et al., 2024),模型困惑度(Marion et al., 2023; Muennighoff et al., 2023; Ankner et al., 2024)或利用 LLMs 来指导样本选择过程(Wettig et al., 2024; Sachdeva et al., 2024; Zhang et al., 2024b)。 (3)组级别选择 假设数据可以分组,然后最优地混合这些组。虽然早期工作再次依赖于手动混合(Gao et al., 2021; Brown et al., 2020),但学习混合的方法越来越常见(Albalak et al., 2024)。学习方法要么利用代理模型来确定每个组的固定权重(“离线选择”)(Rae et al., 2021; Xie et al., 2023a; Fan et al., 2023),要么在训练最终模型时动态调整权重(“在线选择”)(Wang et al., 2020; Chen et al., 2023; Albalak et al., 2023)。我们的方法 REGMIX 是一种离线组级别选择方法。与这一类别的旗舰算法 DoReMi(Xie et al., 2023a)不同,REGMIX 不需要训练单个模型数十万步,而是训练少量小模型较短时间。由于这些模型可以并行训练,我们的方法更具可扩展性,同时也能产生更好的权重,从而得到性能更优的最终模型。
(token、样本、组,三个级别的数据选择和混合,这种分类方式值得关注,把常规的token过滤动作当成是数据选择的一部分。)
数据扩展定律研究了随着 LLMs 扩大规模时数据数量、质量和混合比例之间的相互作用。Muennighoff et al.(2023)引入了数据受限场景下的扩展定律,而 Goyal et al.(2024)试图将这种方法扩展到处理多个数据池。先前的研究已经确认不同数据集需要不同的扩展(Hoffmann et al., 2022; Pandey, 2024),因此 Ye et al.(2024)和 Ge et al.(2024)提出了函数关系来预测混合对语言建模损失的影响。一些工作还研究了在持续预训练期间的最佳混合,而不是从头开始训练(Que et al., 2024; Dou et al., 2024)。与专注于验证损失的数据扩展工作不同,REGMIX 直接使用回归模型优化目标指标。REGMIX 是为从头开始的预训练设计的。与先前的研究(Huang et al., 2024)一致,我们也发现损失与下游性能之间存在强相关性,尤其是对于网络语料库的损失。
(本文之前已经出现了用函数关系预测数据混合对语言建模的影响,所以作者将其扩展到使用线性回归模型预测也是顺其自然的。)
3 REGMIX:数据混合作为回归问题
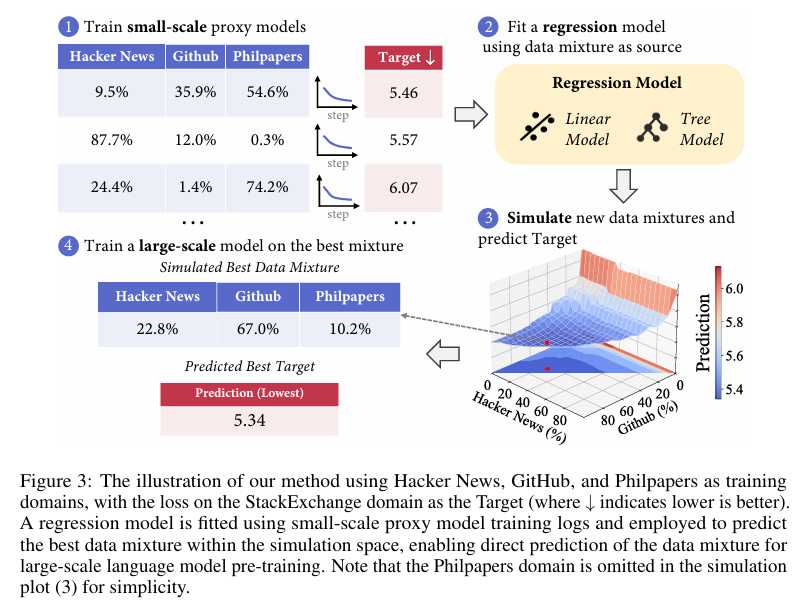
如图 3 所示,我们的方法包含四个关键步骤:(1)生成随机数据混合方案,并在这些混合方案上训练小型代理模型;(2)使用数据混合方案作为特征,目标值作为标签来拟合线性回归模型;(3)在更大规模上模拟数据混合空间,并利用回归模型识别出针对目标值的最佳混合方案;(4)使用模拟出的最佳数据混合方案来训练大规模模型。
(数据混合方案是特征,目标值是什么?是模型在评测集上的表现指标吗?)
3.1 训练小型代理模型
第一步是在多种不同的数据混合方案上训练一组小型代理模型。为了减少所需的运行次数,我们旨在选择一系列多样化的数据混合方案,涵盖从 0% 到 100% 的极端权重。我们通过基于 token 分布的狄利克雷分布来实现这一点,从而能够采样出一系列广泛的值,并使回归模型接触到各种极端情况。同时,基于 token 分布构建分布确保了整体数据混合在统计上反映了数据的可用性。例如,这可以防止任何 token 数量低于 1% 的单一领域被过度强调,因为对于大规模训练来说,该领域没有足够的可用 token。在实践中,我们将 token 分布乘以一个介于 0.1 到 5.0 之间的值,以构建各种稀疏和近乎均匀的分布,然后使用这些分布向量作为狄利克雷分布的超参数 α。
(数据混合是在领域之间进行的,包括哪些领域?如何基于token分布进行混合方案的生成?)
在训练小型代理模型几个步骤后,我们可以获得一些训练良好的小型模型。例如,在我们的主要实验中,每个代理模型包含 100 万参数,并在 10 亿 tokens 上进行训练。然后,我们可以选择在领域或基准测试上评估这些训练有素的模型,以获得我们想要优化的目标值。通常,目标值可以是一个领域的损失值,如图 3 中针对 StackExchange 领域的损失值。一旦我们获得了这些目标值,我们就可以使用数据混合方案作为特征,目标值作为标签来拟合回归模型。
(作者把一个领域评测基准的预测损失值当作目标,应该比直接算评测结果的对与错能获得更多的差值空间。评估集的结果只有对错,损失值可是体现和正确答案更明确的预测差值。)
补充(数据混合方案生成)
(让Kimi来解释一下数据混合方案生成的过程,实际上就是利用了狄利克雷分布这个生成分布的工具,可以调整各种数据域的比例)
狄利克雷分布可以通俗地理解为一种“随机分配比例的工具”。想象一下,你有一个装满不同颜色球的袋子,比如红球、蓝球和绿球。你希望随机决定每次从袋子里抓取每种颜色球的比例,但要求所有比例加起来必须是100%。狄利克雷分布就是用来生成这些随机比例的。
例如,假设你有三种颜色的球(红、蓝、绿),狄利克雷分布会随机生成类似这样的比例组合:
- 红球占 60%,蓝球占 30%,绿球占 10%
- 红球占 20%,蓝球占 50%,绿球占 30%
- 红球占 40%,蓝球占 40%,绿球占 20%
这些比例组合都是随机的,但它们都有一个共同点:所有比例加起来一定是100%。狄利克雷分布的参数可以控制生成的比例是更倾向于均匀分布(比如每种颜色都接近33%),还是更倾向于某些颜色占主导地位(比如一种颜色占80%,其他两种各占10%)。
简单来说,狄利克雷分布就是用来生成“多个部分占整体的比例”的随机组合,而且这些比例的总和一定是1。
假设我们有三个数据域:
- Pile-CC:基础权重50%
- GitHub:基础权重30%
- Wikipedia:基础权重20%
我们用这些基础权重构造一个狄利克雷分布,然后从这个分布中随机采样,得到不同的数据混合方案,比如:
- 方案1:Pile-CC占60%,GitHub占30%,Wikipedia占10%
- 方案2:Pile-CC占40%,GitHub占40%,Wikipedia占20%
- 方案3:Pile-CC占70%,GitHub占20%,Wikipedia占10%
这些方案都满足权重非负且总和为1的条件,可用于后续的模型训练和性能评估。
3.2 拟合回归模型
第二步是使用数据混合方案作为特征,目标值作为标签来拟合回归模型。回归任务是一个传统的监督学习任务,涉及基于输入特征 X=(x1,x2,…,xn) 预测连续目标变量 y。目标是找到一个函数 f,使其能够最好地将输入特征映射到目标变量,即 y=f(X)+ϵ,其中 ϵ 表示数据中的误差或噪声。在本文的上下文中,输入特征 X 对应于数据混合方案的领域权重,目标变量 y 是我们想要优化的值。利用这些数据,我们训练回归模型,使其能够基于任意数据混合方案预测目标值,而无需进一步训练。
线性回归
线性回归模型在回归中被广泛使用。它假设输入特征与目标变量之间存在线性关系,可以表示为:
y=ω0+ω1x1+⋯+ωnxn+ϵ
其中,ω0 是截距,ω=(ω1,…,ωn) 是与各自输入特征 x1,…,xn 相关联的系数。通常使用普通最小二乘法等技术来估计系数 ω,旨在最小化预测值与实际目标值之间的平方残差之和。在实践中,我们采用带有 L2 正则化的线性回归(也称为岭回归),通过惩罚 ω 的大小来防止过拟合。
LightGBM 回归
LightGBM(Ke et al., 2017)是一种强大的基于梯度提升的算法,可用于回归和分类任务。在回归的上下文中,LightGBM 学习一组决策树来预测目标变量。该过程由基于梯度的优化算法引导,旨在最小化指定的损失函数(例如,均方误差)。此外,LightGBM 被设计为高效且可扩展的,使其适合处理大型数据集。
(经典的机器学习算法,有Python库可以用,速度也很快。)
3.3 模拟和预测
一旦我们训练好了回归模型,就可以高效地探索所有可能的数据混合方案空间。通过使用训练好的模型对每种潜在的数据混合方案进行目标值预测,我们可以快速识别出产生最佳目标值的输入。这种基于模拟的优化相对成本较低,因为无论是模拟过程还是回归预测在计算上都非常快速。例如,对 100 万个数据混合方案进行预测,CPU 时间不到 10 秒。
3.4 大规模模型训练
在通过模拟确定了最佳数据混合方案后,我们将这种排名最高的数据混合方案推广到大规模模型训练中,使用更多的 tokens 进行训练。如图 3 所示,我们直接使用最佳数据混合方案来训练更大的模型。在实践中,为了提高回归预测的鲁棒性,我们选择排名前 100 的混合方案,并将它们平均作为大规模训练的数据混合方案。
(所以数据混合预测器的训练需要保证和最终训练大模型的数据同源同分布,同样的数据领域。)
(直接把每个领域在不同分布的比例做平均,最终每个领域的均值相加能确保为1。)
4 回归预测评估
本节评估 REGMIX 方法预测未见数据混合方案效果的能力。首先,我们基于小型(即 100 万参数)模型的训练结果拟合回归模型,并评估其对小型模型损失预测的性能。随后,为了验证我们的排名不变性假设,我们测试所学回归模型在不同模型大小和训练 token 数量下的排名预测能力。
(验证数据混合排名不变性假设很重要。)
4.1 实验设置
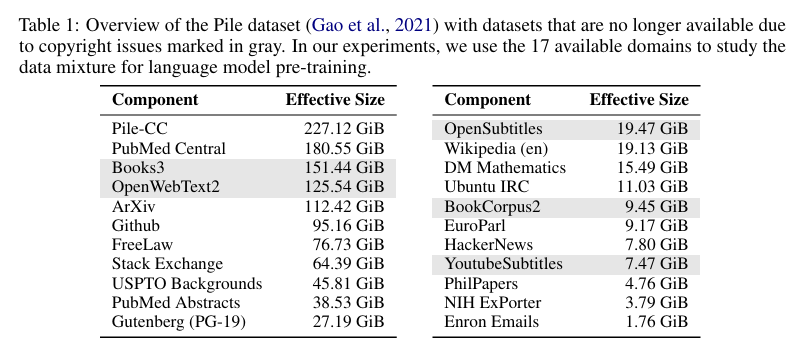
数据集和模型:我们使用 Pile 数据集(Gao et al., 2021)的领域进行实验,如表 1 所示。由于版权问题,我们使用 HuggingFace 上可用的 17 个子集,这些子集不涉及版权问题。我们考虑线性回归和 LightGBM 回归模型,目标 ( y ) 设置为 Pile-CC 领域的验证损失。
(最新的实验可能要基于DCLM这些新数据集完成了,这些子集不是按照领域重新划分的,而是按照数据来源进行的划分,虽然不同来源的数据面向不同领域。)
训练和评估:回归模型是基于 512 个 100 万参数模型的训练结果进行拟合的,这些模型均在 10 亿 tokens 上进行训练。我们对 100 万参数模型(每种模型均在 10 亿 tokens 上训练)的 256 种未见数据混合方案,以及 10 亿参数模型(每种模型均在 250 亿 tokens 上训练)的 64 种未见数据混合方案进行评估。
(注意模型和数据的规模。)
评估指标:我们使用两个指标来评估我们的回归模型:(1)斯皮尔曼秩相关系数(( \rho ))是一种非参数统计量,用于衡量两个排序变量之间的关联强度和方向;(2)均方误差(MSE)是评估模型的常用指标,通过衡量预测值与实际值之间的平均平方差来衡量。
4.2 实验结果
模型大小之间的高相关性:如表 2 所示,LightGBM 模型在所有三个指标上的表现均优于线性回归模型,且随着模型大小和训练 token 数量的增加,其优势愈发明显。此外,100 万参数模型在 10 亿 tokens 上训练的结果与 10 亿参数模型在 250 亿 tokens 上训练的结果之间,斯皮尔曼秩相关系数高达 97.12%,这直接验证了我们的排名不变性假设。
(LightGBM的预测性能高于线性回归,这是可以预见的。)
具体计算时的数据集大小
- 对于1B参数模型,作者评估了64个不同的数据混合方案。
- 对于每个方案,都有一个预测的验证损失值和一个实际的验证损失值。
- 因此,在计算斯皮尔曼系数和均方误差时,是基于这64个数据点进行的。
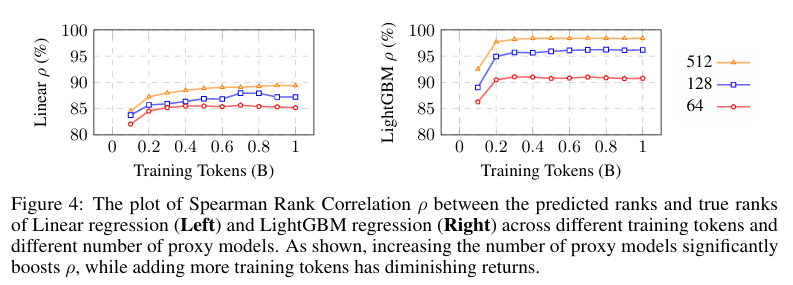
代理模型数量优于训练 token 数量:在给定相同 FLOPs 预算用于小规模训练的情况下,我们可以选择增加训练 token 的数量(即增加训练 token 的数量),或者增加代理模型的数量。因此,我们研究了哪种方法能带来更好的性能。如图 4 所示,随着代理模型数量的增加,性能持续提升,尤其是在 LightGBM 模型中。值得注意的是,512 个模型在 0.2 亿 tokens 上训练的性能超过了 128 个模型在 0.8 亿 tokens 上训练的性能,这表明增加代理模型的数量比在一定 token 阈值以上增加训练 token 的数量更有效。
(说明本文使用的1M模型对于0.2亿token训练就能达到用于获取数据混合规律的有效样本,所以相同的计算资源不如用于训练更多模型,收集更多数据混合的特征样本用于训练预测器。)
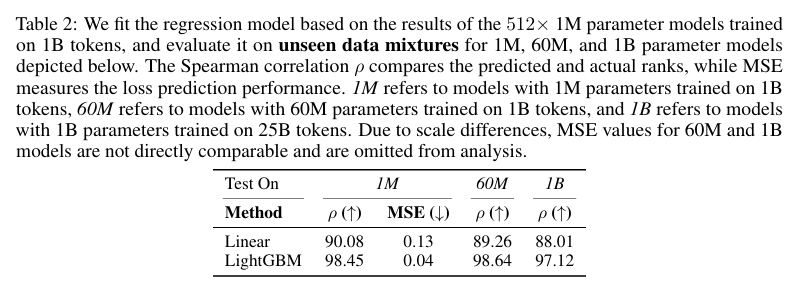
补充(关于表格2的理解)
所以意思是作者对256个数据混合都训练了1M、60M和1B模型(1B模型用的是64个数据混合),但是数据混合的预测器是用512个1M模型训练的。前者为了评估预测器,后者为了训练预测器。
是的,你的理解是正确的。让我进一步梳理和确认一下:
关于 Table 2 和实验设计
-
512 个 1M 模型的作用(训练预测器) :
- 作者训练了 512 个 1M 参数的小模型,每个模型都使用了不同的数据混合方案,并且每个模型都训练了 1B tokens。
- 这些模型的训练日志(即不同数据混合方案下的训练结果)被用来训练回归模型(如 LightGBM),从而生成一个数据混合方案的预测器。这个预测器的目标是能够预测任意给定数据混合方案在大规模模型训练中的表现。
-
256 个1M、60M 和 64 个 1B 模型的作用(评估预测器) :
- 作者又训练了 256 个 1M 参数模型、 60M 参数模型以及 64 个 1B 参数模型。这些模型同样使用了不同的数据混合方案,但与那 512 个 1M 模型的数据混合方案可能不同。
- 其中,1B 参数模型训练了 25B tokens,规模更大,更接近实际应用场景中的大规模模型。
- 通过将回归模型(预测器)预测的性能与这些实际训练得到的模型性能(无论是 1M、60M 还是 1B 参数模型)进行对比,作者能够评估预测器的准确性。
Table 2 的重点
- Table 2 呈现的是不同回归模型(线性回归和 LightGBM)在不同目标模型规模(1M、60M 和 1B 参数模型)下的预测效果。
- 对于每个目标模型规模,作者计算了斯皮尔曼秩相关系数(ρ)和均方误差(MSE),以量化预测值和实际值之间的一致性和差异。
这个实验设计的关键在于验证:通过小规模模型(如 1M 参数模型)训练出来的预测器,是否能够准确预测更大规模模型(如 1B 参数模型)在不同数据混合方案下的性能。实验结果显示,LightGBM 回归模型在所有模型规模下都表现出了较高的预测准确性,证明了这种方法的有效性。
5 在下游任务上的评估
在本节中,我们将我们的方法应用于现实世界的下游任务,以展示其有效性。为了进行评估,我们排除了某些基准测试,这些测试表现出较大的性能差异(例如,RTE),这是根据之前工作(Mehta et al., 2024)中报告的性能轨迹以及我们在预训练期间的观察结果而决定的。最终,我们选择了以下基准测试作为我们的下游任务:Social IQA(Sap et al., 2019)、HellaSwag(Zellers et al., 2019)、PiQA(Bisk et al., 2020)、OpenBookQA(Mihaylov et al., 2018)、Lambada(Paperno et al., 2016)、SciQ(Welbl et al., 2017)、ARC Easy(Clark et al., 2018)、COPA(Sarlin et al., 2020)、RACE(Lai et al., 2017)、LogiQA(Liu et al., 2020)、QQP(Wang et al., 2018)、WinoGrande(Sakaguchi et al., 2021)和 MultiRC(Khashabi et al., 2018)。这些基准测试涵盖了多种不同的任务,能够全面评估 REGMIX 对现实世界的影响。对于每个基准测试,如果 lm-eval-harness(Gao et al., 2023)提供了标准化的准确率,则使用该指标;否则,我们使用常规的准确率作为评估指标。
(什么意思?为什么说测试表现出较大的性能差异就不采用这些基准测试了?)
Kimi:
以下是第五章节中提到的下游评估任务的列表:
- Social IQA:社交IQ问答任务,评估模型对社交互动的理解和推理能力。
- HellaSwag:完形填空任务,评估模型对文本连贯性和常识的理解。
- PiQA:物理常识问答任务,评估模型对物理世界的理解和推理能力。
- OpenBookQA:开放书籍问答任务,评估模型对科学知识的掌握和推理能力。
- Lambada:语言建模任务,评估模型对文本连贯性和上下文理解的能力。
- SciQ:科学问答任务,评估模型对科学知识的理解和推理能力。
- ARC Easy:AI2推理挑战简单部分,评估模型的阅读理解和推理能力。
- COPA:因果关系问答任务,评估模型对因果关系的理解和推理能力。
- RACE:阅读理解任务,评估模型的阅读理解和推理能力。
- LogiQA:逻辑推理问答任务,评估模型的逻辑推理能力。
- QQP:问题相似性任务,评估模型判断两个问题是否相似的能力。
- WinoGrande:代词消解任务,评估模型对代词指代的理解能力。
- MultiRC:多项选择阅读理解任务,评估模型的阅读理解和推理能力。
这些任务涵盖了语言理解、常识推理、逻辑推理等多个方面,用于全面评估REGMIX方法在不同数据混合方案下的模型性能。
5.1 数据混合对下游性能有显著影响
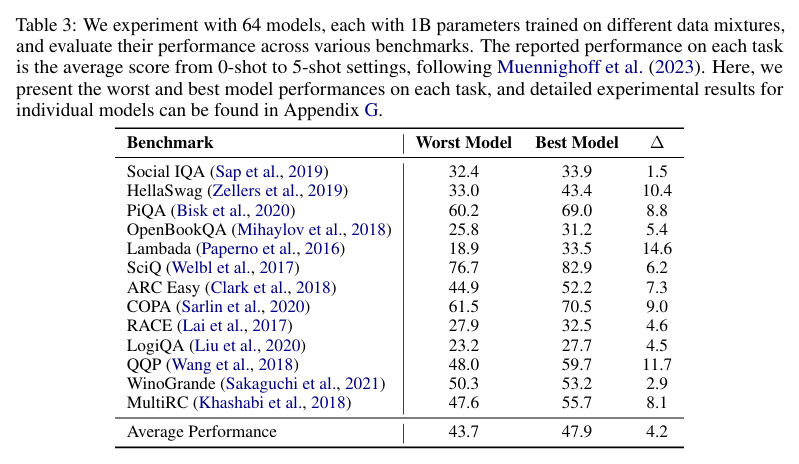
最初,我们训练了 64 个模型,每个模型都有 10 亿参数,使用不同的数据混合方案。每个模型都在 Pile 数据集(Gao et al., 2021)的 250 亿 tokens 上进行训练,tokens 的分配基于相应的领域权重。表 3 展示了每个下游任务上表现最差和最佳的模型性能。报告的性能是从 0-shot 到 5-shot 评估的平均分数,遵循 Muennighoff et al.(2023)的方法。我们发现数据混合方案对下游性能有显著影响,最大的性能差异在 Lambada 任务上达到了 14.6,这强调了研究最佳数据混合方案的重要性。
(作者使如何选择64个数据混合比例的?是否有较大的数据比例差异?)
5.2 网络语料库对下游性能的提升最为显著
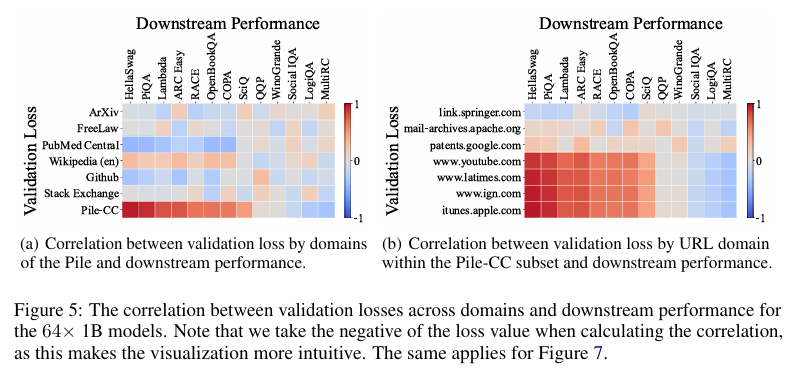
接下来,我们可视化了我们 64 个 10 亿参数模型在不同领域的验证损失与各种下游任务性能之间的相关性,如图 5(a)所示。在可视化之前,我们假设 Wikipedia(en)子集的验证损失将与大多数下游任务表现出强相关性,因为它是一个高质量的数据集,许多下游任务都是从 Wikipedia 文本中衍生出来的。同样,以往的研究通常将 WikiText(Merity et al., 2016)作为衡量语言模型性能的标准基准。
然而,令人惊讶的是,Pile-CC 数据集的验证损失与大多数下游任务的性能表现出最强的相关性。例如,HellaSwag 任务与 Pile-CC 验证损失之间的相关系数非常接近 1.0。这一意外结果挑战了传统的假设,即 WikiText 是评估 LLMs 的最具代表性的数据集。此外,这一结果与先前的研究(Gadre et al., 2024;Huang et al., 2024)一致,这些研究发现网络数据集的验证损失与下游性能密切相关。
此外,我们分析了在 C4100Domain 验证集(Magnusson et al., 2023)上模型的损失与下游任务性能之间的相关性,该验证集取自 C4 数据集(Raffel et al., 2019),其分布被认为与 Pile-CC 类似,因为它们都源自 CommonCrawl 语料库。由于 CommonCrawl 是一个涵盖各种主题的多样化领域集合,我们预期每个领域的损失与下游任务的相关性会有所不同。然而,令人惊讶的是,超过 85% 的领域与 Pile-CC 表现出非常强的相关性(完整的相关性图见附录 D)。这可以通过图 5(b)中的 www.ign.com 领域得到例证,它与 Pile-CC 的整体相关性图非常接近。这也表明,Pile-CC 与下游任务性能之间的高相关性可能归因于其在各种主题和领域上的广泛覆盖。
(感觉作者大惊小怪,不同类型的下游任务当然呈现巨大差异,怎能说WikiText就是衡量性能的标准,比如社交内容的评估,和百科内容肯定差很多,百科内容应该在知识性上要求更高吧。当然,领域覆盖全面的语料当然是最好的。)
5.3 REGMIX 数据混合方案提升下游性能
以往的研究表明,数据混合方法可以通过在更少的训练 tokens 下实现更小的验证损失(或困惑度)来加速 LLM 预训练(Xie et al., 2023a)。然而,一个关键的挑战是如何确定要优化的验证损失。虽然直观的方法是尽量减少所有领域的损失,但我们对 100 万训练日志的分析揭示了实际应用中的重大挑战。因此,我们没有追求广泛的优化策略,而是战略性地专注于最小化 Pile-CC 的验证损失,这允许我们通过利用 Pile-CC(它最一致地预测了模型在下游任务上的整体性能)来取得有意义的进展。
(意思是数据混合能加速训练,但是太难。选择优化Pile-CC是对的,因为作者的评估也是用了各种领域数据,对Pile-CC这种综合性的数据集中优化损失比较合理。)
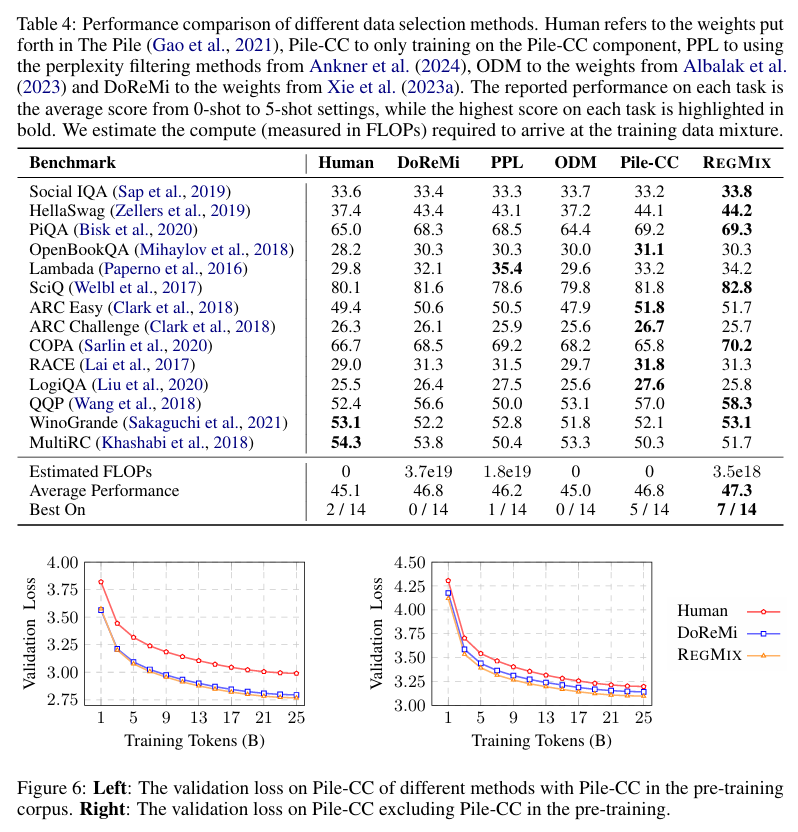
我们采用两种方法来确定数据混合方案。第一种方法依赖于人类的直觉。由于 Pile-CC 及其自身的分布应该是最接近的匹配,我们假设仅在 Pile-CC 上进行预训练可能会比基线方法获得更好的性能。第二种方法利用 REGMIX,以 Pile-CC 验证损失作为目标变量。我们使用 LightGBM 来预测可以最小化 Pile-CC 验证损失的数据混合方案。
我们在强大的基准测试中评估了我们提出的方法,包括 Pile 数据集(Gao et al., 2021)中人类策划的选择、基于困惑度的样本级过滤方法(PPL)(Ankner et al., 2024)、在线组级方法 Online Data Mixing(ODM)(Albalak et al., 2023)以及旗舰组级方法 DoReMi(Xie et al., 2023a)。对于 ODM 和 DoReMi,我们直接从他们报告的最佳领域权重中获取数据混合方案,并在可用的 17 个领域中重新归一化。这可能导致它们的性能与最初报告的结果相比有所下降。如表 4 所示,Pile-CC Only 和 REGMIX 与基线方法相比均表现出强大的性能。在广泛使用的 HellaSwag 基准测试中,REGMIX 比人类选择提高了 6.8。此外,REGMIX 在 7 个任务中的表现超过了其他三种方法,并且在平均分数上取得了最高分。Pile-CC Only 在 HellaSwag 任务上的出色表现进一步强化了我们之前部分的结论:网络语料库对下游性能的提升最为显著。最后,REGMIX 超越了表 3 中的最佳模型,表明我们的自动化数据混合方法比随机搜索更有效。
尽管Pile-CC验证损失是下游性能的一个有信息量的指标,但它可能并不适用于每个感兴趣的任务。有时我们可能无法假设验证集来自与训练集相似的数据分布,而是可能面临分布外的情况。为了验证我们的方法在分布外场景中的有效性,我们完全排除了预训练语料库中的Pile-CC领域,并使用剩余的领域来找到最小化Pile-CC验证损失的最优数据混合。正如图6(右)所示,我们提出的方法仍然优于基线方法。这表明REGMIX无论目标领域是在分布内还是分布外都是稳健的。我们还在图6中提供了在此设置下的回归评估结果。
(看起来REGMIX方法没有提升太多,也许用来兜底是不错的。)
5.4 人类难以理解的领域交互
为了理解不同领域对彼此的影响,我们使用线性回归模型可视化了不同目标领域验证损失与训练领域权重之间的相关性。可视化提供了领域之间如何相互贡献的见解,揭示了它们之间复杂的交互。我们还展示了每个1M代码模型在The Stack数据集上训练的相关性图。令人惊讶的是,无论是领域交互可视化还是代码相关性图,都显示出复杂的关系,这些关系对于人类专家来说很难完全理解。例如,Pile数据集中的PhilPapers领域在线性回归建模中似乎为所有其他领域提供了增益,这是一个非直观的发现,挑战了人类的直觉理解。这些可视化突出了确定最优数据混合的固有复杂性,强调了我们自动化的REGMIX方法在有效识别高性能混合方面的价值,而不是完全依赖于人类直觉。
(启发式的局限)
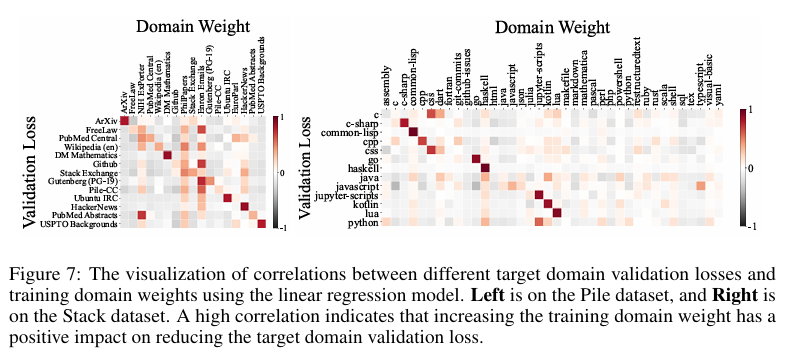
5.5 数据混合效应超越缩放定律
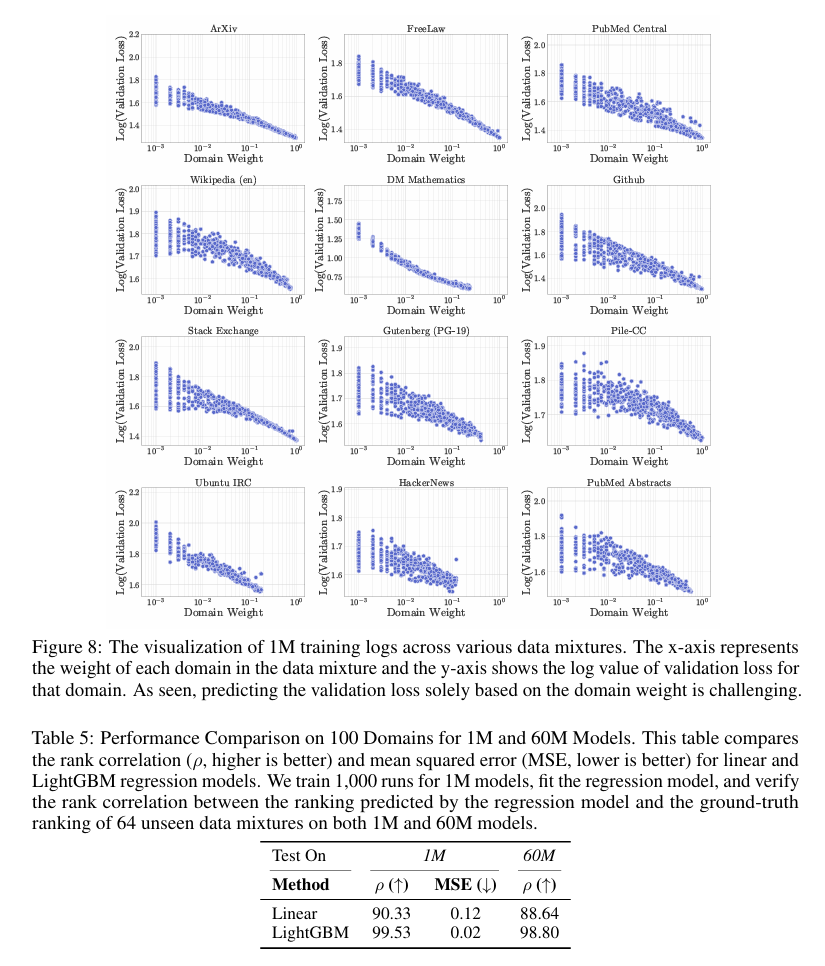
最近的研究(Ye et al., 2024; Ge et al., 2024)已经证明了数据混合的缩放定律的可行性。然而,我们在第5.4节中的发现表明,领域权重与验证损失之间的关系比缩放定律可能暗示的要复杂。为了可视化这种复杂性,我们在图8中绘制了我们1M训练日志的所有实验点。如果数据混合的缩放定律成立,我们期望看到所有领域之间存在清晰的对数-对数线性关系。然而,我们的结果揭示了一个更微妙的图景。例如,DM Mathematics领域可能由于其与其他领域相比的独特分布,显示出损失与领域权重之间的几乎对数-对数线性关系。相比之下,对于大多数领域,如Pile-CC,显示出更复杂的模式,其中预测验证损失并非易事。如图所示,领域交互似乎很复杂,仅基于领域的权重预测验证损失是具有挑战性的。这些发现表明,虽然缩放定律提供了宝贵的见解,但可能无法完全捕捉数据混合动态的复杂性。我们的方法通过将整个数据混合作为回归模型的输入来解决这一挑战,提供了一个更全面的框架,用于预测验证损失,同时考虑所有领域权重。
Kimi:
论文5.5章节提到的数据混合缩放定律(Data Mixing Scaling Law)是关于如何通过小规模实验来预测在不同数据混合比例下,大规模模型训练的性能。
具体来说,该定律旨在通过在小规模模型上进行少量训练数据的实验,利用训练步骤、模型大小和数据混合比例的缩放规律,来预测大规模模型在不同混合比例下的性能。这种方法允许在不进行昂贵的完整训练运行的情况下,预测和选择理想的数据混合比例。
通过实验验证,作者发现这种方法可以有效优化在大规模数据和大型模型上的训练混合比例。例如,在RedPajama数据集上对1B模型进行了100B tokens的训练,实验结果表明优化后的数据混合比例能够达到与默认混合比例训练更多步骤的模型相当的性能。
5.6 将REGMIX扩展到100个领域
为了展示REGMIX的可扩展性,我们进行了初步实验,涉及100个更细粒度的领域。一个关键挑战在于将网络内容聚类为有意义的领域表示。直观地说,我们根据FineWeb数据集(Penedo et al., 2024a)中的基础URL定义领域,这些URL是根据令牌可用性选择的。示例领域包括articles.latimes.com、blogs.wsj.com、en.wikipedia.org、everything2.com和techcrunch.com。
我们训练了1,000个小型模型(1M参数)在不同的数据混合上,使用这些训练运行来拟合回归模型,然后预测1M和60M参数模型的数据混合。表5显示了线性和LightGBM回归模型的排名相关性(ρ)和均方误差(MSE)的评估结果。结果证明了REGMIX在扩展到100个领域时的有效性。
(细粒度领域的数据混合是有必要尝试的,毕竟按照原始数据源划分有些草率。)
6 结论
在本文中,我们提出了REGMIX,这是一种新的方法,用于自动选择预训练大型语言模型时表现优异的数据混合。通过将数据混合问题表述为回归任务,REGMIX训练小型模型来预测不同混合的影响,从而高效地识别出最优组合。我们通过预测64个1B参数模型中的最佳数据混合来证明REGMIX的有效性。我们的大规模研究提供了关于数据混合影响、损失与下游性能之间的关系以及人类专家在确定最优数据混合时面临的挑战的见解。
伦理声明
优化大型语言模型预训练的数据混合引发了一些伦理问题。首先,优化的数据混合可能偏向于某些领域,这有助于提高性能。然而,某些领域可能被低估或错误表示,导致训练出的模型在这些领域表现不佳或产生偏见结果。其次,尽管我们的方法旨在高效优化数据混合,但寻找最优数据混合仍然需要计算资源,导致高能耗和环境影响。值得探索如何进一步降低计算成本。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号