


隐式排序
在Mysql8.0之前,可以使用Group by 是进行先分组后排序,Group by id是进行的隐式排序
显示转换
Group by id desc 是Mysql8.0之前的显示排序
在MYSQL8.0之后不再支持当前的显示排序,需要Group by id后手动Order by id desc;
窗口函数
CREATE TABLE student_grade (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(50) NOT NULL,
class CHAR(1) NOT NULL,
subject VARCHAR(20) NOT NULL,
grade INT NOT NULL
);
INSERT INTO student_grade
(name, class, subject, grade)
VALUES
('Tim', 'A', 'Math', 9),
('Tom', 'A', 'Math', 7),
('Jim', 'A', 'Math', 8),
('Tim', 'A', 'English', 7),
('Tom', 'A', 'English', 8),
('Jim', 'A', 'English', 7),
('Lucy', 'B', 'Math', 8),
('Jody', 'B', 'Math', 6),
('Susy', 'B', 'Math', 9),
('Lucy', 'B', 'English', 6),
('Jody', 'B', 'English', 7),
('Susy', 'B', 'English', 8);
current row
select *,sum(grade) over(partition by id order by grade asc range current row ) as wf_result from student_grade;
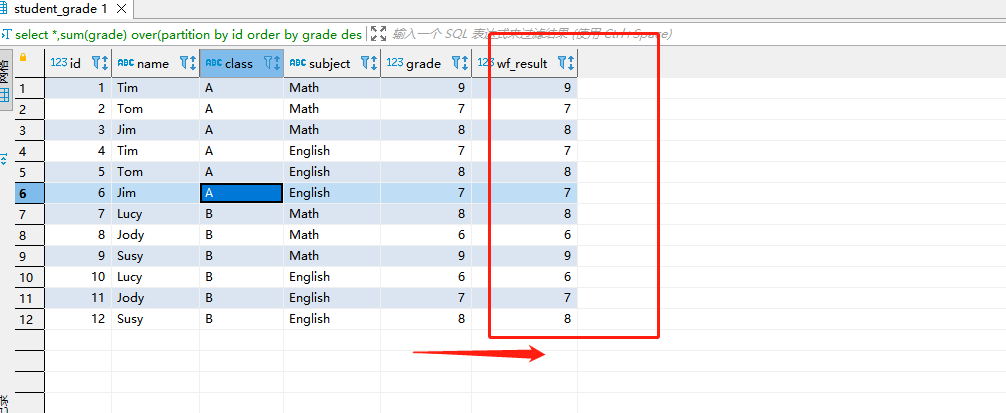
- 获取当前行记录,也就是边界是当前行,等职关系
- 其中 OVER 子句用来定义分区以及相关条件,这里表示只获取分组内排序字段的当前行记录,也就是字段 r1 对应的记录,这是最简单的场景。
UNBOUNDED PRECEDING
select *,sum(grade) over(partition by grade order by grade desc rowS UNBOUNDED PRECEDING ) as wf_result from student_grade;
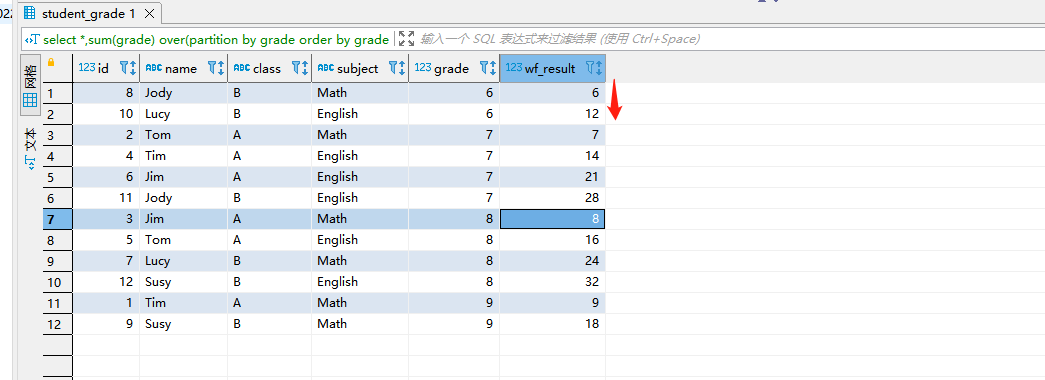
- 解释:指定分区内根据指定行排序,进行指定分区之前累加的结果
unbounded following
unbounded preceding and current row 无边界并并且当前行
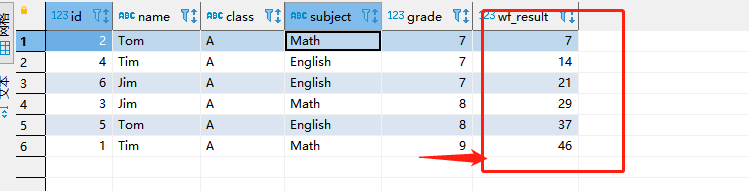
select *, sum(grade) over(partition by class order by grade ASC rowS between unbounded preceding and current row) as wf_result from student_grade where class = 'A'
select *, sum(grade) over() as wf_result from student_grade where class = 'A'
- 解释:指定分区内根据指定行排序,边界为永远第一行到当前行
- 相同于第二条SQL,只是没有排序
unbounded preceding and unbounded following
select *, sum(grade) over(partition by class order by grade desc rowS between unbounded preceding and unbounded following) as wf_result from student_grade where class = 'B'
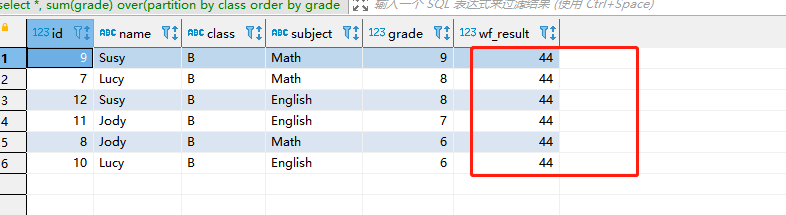
- 解释:指定分区内根据指定行排序,边界为永远第一行到最后一行
expr preceding
select *, sum(grade) over(partition by class order by grade ASC rowS 1 preceding a) as wf_result from student_grade where class = 'A'
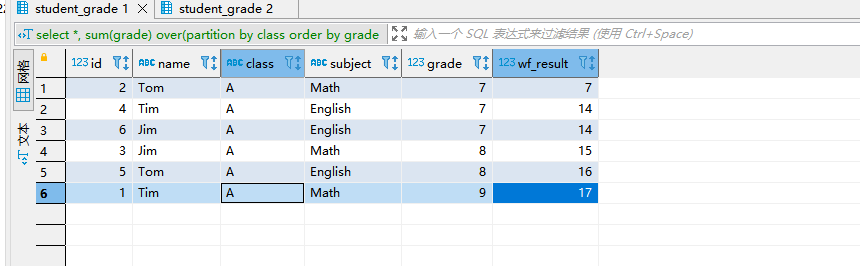
- 解释:获取的当前行和上一行值。
BETWEEN expr preceding and expr following
select *, sum(grade) over(partition by class order by grade ASC rowS BETWEEN 1 preceding and 2 following) as wf_result from student_grade where class = 'A'
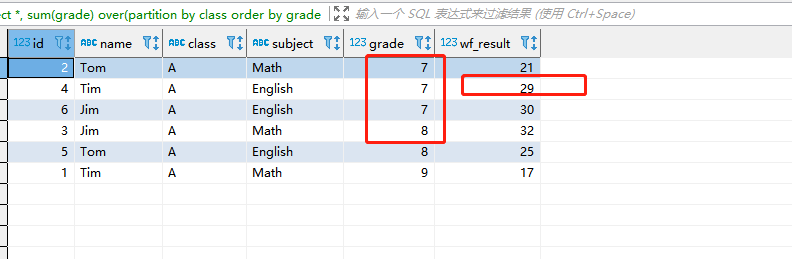
- 解释:获取当前行的前一行+ 后两行
range 1 preceding 对应的是行号,range 对应的行值
select *, sum(grade) over(partition by class order by grade ASC range 1 preceding) as wf_result from student_grade where class = 'A'
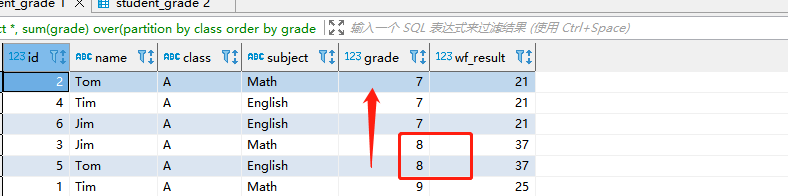
- 解释:获取当前行减1,然后再加上当前行的值
BETWEEN 1 preceding and 1 following
select *, sum(grade) over(partition by class order by grade ASC range BETWEEN 1 preceding and 1 following) as wf_result from student_grade where class = 'A'
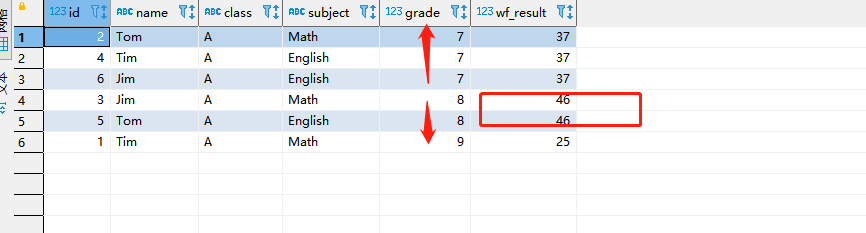
- 解释:获取当前行减1,然后再加上当前行+1的值然后进行相加
函数索引
函数索引的实现
函数索引是基于虚拟列去实现,创建函数索引的时候会去创建隐藏虚拟列,隐藏虚拟列不占用空间,但是函数索引占用空间
#使用该语句可以查看所有的虚拟列
show extended columns from student_grade;
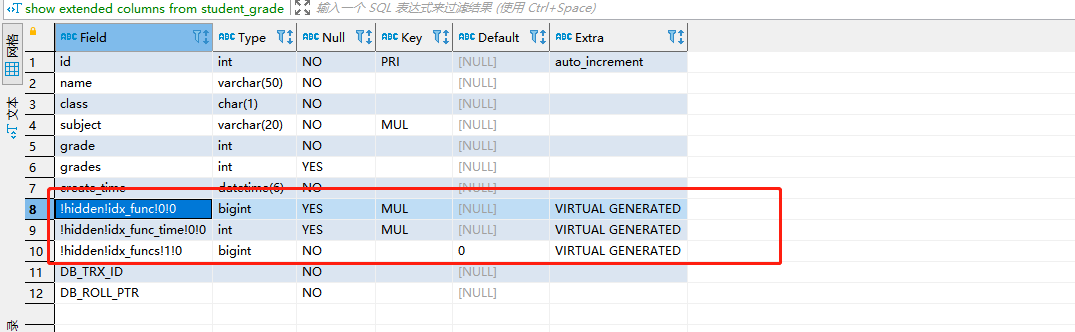
虚拟列的特点,再创建函数索引的时候也有
- 每次增加一个函数索引都会创建一个虚拟列
- 函数索引不能用作外键约束
- 函数索引不能用于主键索引
- 函数索引不能用于空间和全文索引
alter table student_grade add index idx_func((grades + grade)); explain select * from student_grade where (grades + grade) = 10

alter table student_grade add index idx_funcs(subject desc, (grade*10) asc); explain select * from student_grade where subject ='Math' and (grade*10)=70 order by subject desc,(grade*10) asc

alter table student_grade add index `idx_func_time`((month(create_time))); explain select name from student_grade where month(create_time) = 4;

HashJoin
IN-MEMORY HashJoin(CHJ-classic Hash join)
-
MYSQL默认的join_buffer_size为256K
- join_buffer_size 的值需要根据你的Mysql机器的连接数和内存大小进行适当配置。推荐配置再8~16 。40G =40,960M 2M*10000 =20000 也不到总体内存的50%(官方说tatal加起来的使用内存不超过50%)
-
再MySQL8.0之前,只支持NestLoopJoin算法,时间复杂度为n*m,要先遍历外表的数据然后再遍历内表的数据,之后才支持HashJoin。
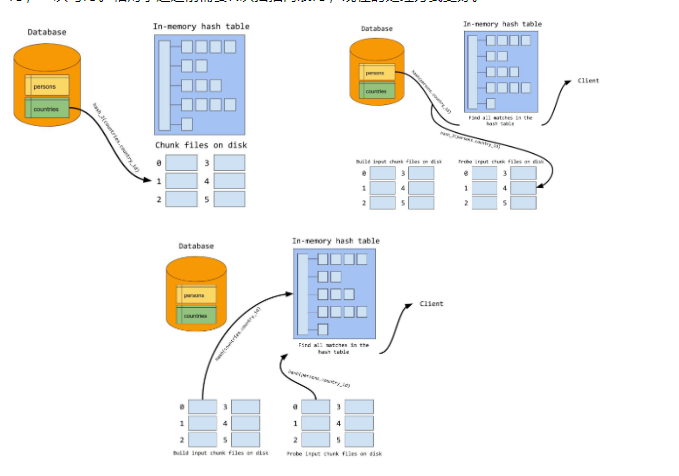
HashJoin的创建步骤
- 创建Hash表的build过程和Hash表探测的probe过程
- build过程:HashJoin会根据表的大小进行判断,大表和小表会选择小表,这样有限的内存可以放下Hash表
- probe过程:build过程之后,就会将内表查询处理根绝关联关系进行hash,知道遍历完内表
IN-DISK HashJoin
CHJ的条件必须是内存放得下整个外表,如果没办法的话,Mysql并不会将外表切换成N段,之后进行循环n段进行查询。 而是根据Mysql的Hash进行分区,然后将分区后的片段存进磁盘里面,然后再probe阶段的话,使用相同的hash然后进行内表的查询,进行 分片,因为用了相同的hash,所以外边的分片和内表的分片,hash后的范围是相同的。然后再去走CHJ整个join过程就结束了 。这种算法的代价是,对外表和内表分别进行了两次读IO,一次写IO。相对于之之前需要N次扫描内表IO
不可见索引
在Mysql8.0中,索引可以被“隐藏” 和“显示”。
- 当索引进行隐藏的时候,优化器不会使用被隐藏的索引,
- 运用场景:可以用作sql的优化了,可以作为性能调试,优点:可以不用删除索引
- INVISIBLE关键字 进行索引的处理,隐藏索引之后即使force index也不可以让优化器使用到该索引
不可见索引
在Mysql8.0中,索引可以被“隐藏” 和“显示”。
-
当索引进行隐藏的时候,优化器不会使用被隐藏的索引,
-
运用场景:可以用作sql的优化了,可以作为性能调试,优点:可以不用删除索引
-
INVISIBLE关键字 进行索引的处理,隐藏索引之后即使force index也不可以让优化器使用到该索引
Descending Indexes
- MYSQL8.0之前的索引是双向链表,有后退指针,如果order by grade desc,grades asc 会进行文件排序
- 8.0之后创建索引后 alter table student_grade add index idx_funcs2(grade desc,grades asc); 进行grade desc,grades asc的话优化器就会走索引进行排序。
Anti join
select * from patients where not exists(
select 1 from exams where
exams.type='check-up' and
exams.date>=date_sub(now(), interval 3 year) and
exams.patient_id=patients.patient_id
);
适用场景:
- not exist,not in等语句中
- 要查询某个a集合中,b并且不存在b集合中的数据
anti join 内部优化策略
1.First match 从patinets表中取出一条数据,然后再从表中查询数据,如果数据不存在的话,就返回。如果不存在就不返回。
2.Matertialication 策略
- exams.type='check-up'
- exams.date>=date_sub(now(), interval 3 year)
- exams.patient_id=patients.patient_id
会直接创建一个中间表,然后优化器会给临时表创建一个patients的索引,然后查询的时候直接查询索引,如果不存在就直接返回
create trable tmp select * from exams where exams.type='check-up' and exams.date>=date_sub(now(), interval 3 year)
优势:
- tmp的表比 exams数据量小,访问速度更快
- exmas只用查询一个,创建tmp表的时候
- 创建tmp索引,查询速度更快一点
但是创建临时表的时候,如果数据过大会比较占用内存。如果临时表比较大的话, 会保存在磁盘上。这两种方法根据临时表的大小进行方式的选择。
MYSQL为什么取消了查询缓存
Query Cache能在一定程度上提高查询的效率,但是也会出现查询性能的瓶颈
- SQL语句的不同,需要缓存不同的数据,会造成内存资源的浪费
- 如果表的更新频率比较高的时候, mysql的缓存失效率会比较高,如果一直需要失效缓存的话,性能上的效率不是很高
事务对缓存失效的影响
- 事务中进行表更新的时候,会让查询缓存失效,Innodb的多版本控制会对事务进行隔离。在这个事务提交之前,其他的事务查询数据的时候,会禁止缓存数据。如果有个长事务运行的时候,这会大大的降低缓存的命中率
参考文章
HashJoin:
窗口函数:
Descending Indexes
函数索引:
anti-join:
查询缓存

 浙公网安备 33010602011771号
浙公网安备 33010602011771号