Centos7安装hadoop + zookeeper + hbase HA集群
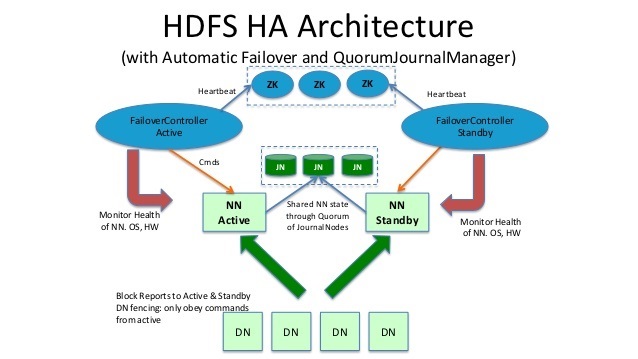
hadoop HA架构
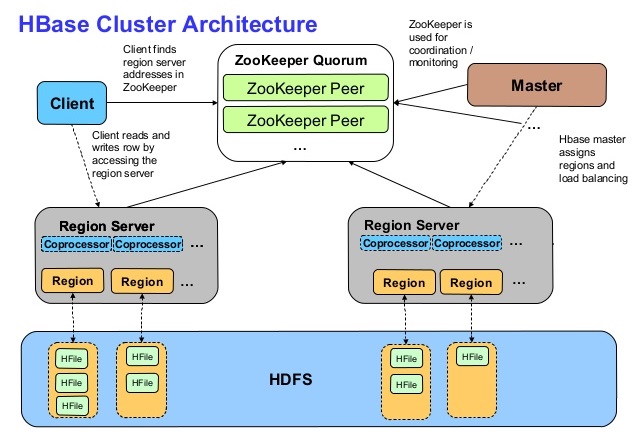
hbase HA架构
官网下载安装包
hadoop下载 https://hadoop.apache.org/releases.html
JDK下载 http://jdk.java.net/java-se-ri/8-MR3
zookeeper下载 https://archive.apache.org/dist/zookeeper/
Hbase与jdk版本兼容情况
| Java Version | HBase 1.4+ | HBase 2.3+ |
| JDK7 | 支持 | 不支持 |
| JDK8 | 支持 | 支持 |
| JDK11 | 不支持 | 初步支持 |
Hbase与hadoop版本兼容情况
| HBase-1.7.x | HBase-2.3.x | HBase-2.4.x | |
| Hadoop-2.10.x | 支持 | 支持 | 支持 |
| Hadoop-3.1.0 | 不支持 | 不支持 | 不支持 |
| Hadoop-3.1.1+ | 不支持 | 支持 | 支持 |
| Hadoop-3.2.x | 不支持 | 支持 | 支持 |
| Hadoop-3.3.x | 不支持 | 支持 | 支持 |
主机规划
| 主机名 | iP | 服务 |
| hbase1 | 192.168.139.31 | NameNode/DataNode/zookeeper/zkfc/journalnode/NodeManager/HMaster/HRegionServer |
| hbase2 | 192.168.139.32 | NameNode/DataNode/zookeeper/zkfc/journalnode/ResourceManager/NodeManager/HRegionServer |
| hbase3 | 192.168.139.33 | DataNode/zookeeper/journalnode/ResourceManager/JobHistoryServer/NodeManager/HMaster/HRegionServer |
关闭防火墙和selinux
配置主机名和hosts文件
配置主机时间同步
配置服务器间免密ssh登录
调整系统参数
在所有主机上进行操作
cat >>/etc/security/limits.conf <<EOF * soft nofile 65535 * hard nofile 65535 * soft nproc 32000 * hard nproc 32000 EOF
解压安装组件
在所有主机上进行操作
tar -zxvf hadoop-3.3.1.tar.gz -C /opt/ tar -zxvf jdk-8u231-linux-x64.tar.gz -C /opt/ tar -zxvf apache-zookeeper-3.6.3-bin.tar.gz -C /opt/ tar -zxvf hbase-2.4.9-bin.tar.gz -C /opt/
添加环境变量
在所有主机上进行操作
新建 /etc/profile.d/java_env.sh
#java export JAVA_HOME=/opt/jdk1.8.0_231 export PATH=$PATH:$JAVA_HOME/bin
新建 /etc/profile.d/hadoop_env.sh
#Hadoop export HADOOP_HOME=/opt/hadoop-3.3.1 export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin
新建 /etc/profile.d/zk_env.sh
#zookeeper export ZOOKEEPER_HOME=/opt/apache-zookeeper-3.6.3-bin export PATH=$PATH:$ZOOKEEPER_HOME/bin
新建 /etc/profile.d/hbase_env.sh
#Hbase export HBASE_HOME=/opt/module/hbase-2.4.9 export PATH=$PATH:$HBASE_HOME/bin
source /etc/profile
修改zookeeper配置文件
在所有主机上进行操作
cp /opt/apache-zookeeper-3.6.3-bin/conf/zoo_sample.cfg /opt/apache-zookeeper-3.6.3-bin/conf/zoo.cfg
修改配置文件 /opt/apache-zookeeper-3.6.3-bin/conf/zoo.cfg
# The number of milliseconds of each tick tickTime=2000 # The number of ticks that the initial # synchronization phase can take initLimit=10 # The number of ticks that can pass between # sending a request and getting an acknowledgement syncLimit=5 # the directory where the snapshot is stored. # do not use /tmp for storage, /tmp here is just # example sakes. dataDir=/opt/apache-zookeeper-3.6.3-bin/zkdata # the port at which the clients will connect clientPort=2181 # the cluster server list server.1=hbase1:2888:3888 server.2=hbase2:2888:3888 server.3=hbase3:2888:3888
创建目录生产myid文件,本脚本在所有主机单独执行
for host in hbase1 hbase2 hbase3; do ssh $host "source /etc/profile; mkdir -p $ZOOKEEPER_HOME/zkdata; echo ${host: -1} > $ZOOKEEPER_HOME/zkdata1/myid"; done
创建zookeeper维护脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 zookeeper 集群 ==================="
for host in hbase1 hbase2 hbase3
do
ssh $host "source /etc/profile; nohup /opt/apache-zookeeper-3.6.3-bin/bin/zkServer.sh start >/dev/null 2>&1 &"
echo "$host zk is running"
done
;;
"stop")
echo " =================== 关闭 zookeeper 集群 ==================="
for host in hbase1 hbase2 hbase3
do
ssh $host "source /etc/profile; nohup /opt/apache-zookeeper-3.6.3-bin/bin/zkServer.sh stop"
echo "$host zk is stopping"
done
;;
"kill")
echo " =================== 关闭 zookeeper 集群 ==================="
for host in hbase1 hbase2 hbase3
do
ssh $host "source /etc/profile;jps | grep QuorumPeerMain| cut -d ' ' -f 1 |xargs kill -s 9"
echo "$host zk is stopping"
done
;;
"status")
echo " =================== 查看 zookeeper 集群 ==================="
for host in hbase1 hbase2 hbase3
do
echo =============== $host ===============
ssh $host "source /etc/profile; nohup /opt/apache-zookeeper-3.6.3-bin/bin/zkServer.sh status"
done
;;
*)
echo "Input Args Error..."
;;
esac
修改hadoop环境文件文件
在所有主机上进行操作
修改 /opt/hadoop-3.3.1/etc/hadoop/hadoop-env.sh ,添加:
export HDFS_NAMENODE_USER=root export HDFS_DATANODE_USER=root export HDFS_JOURNALNODE_USER=root export HDFS_ZKFC_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export YARN_RESOURCEMANAGER_USER=root export YARN_NODEMANAGER_USER=root export JAVA_HOME=/opt/jdk1.8.0_231
修改 /opt/hadoop-3.3.1/etc/hadoop/mapred-env.sh ,添加:
export JAVA_HOME=/opt/jdk1.8.0_231
修改 /opt/hadoop-3.3.1/etc/hadoop/yarn-env.sh ,添加:
export JAVA_HOME=/opt/jdk1.8.0_231
修改hadoop配置文件
在所有主机上进行操作
修改 /opt/hadoop-3.3.1/etc/hadoop/core-site.xml ,在 <configuration> </configuration> 中添加内容
<configuration>
<!-- 指定hdfs的nameservice -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://mycluster</value>
</property>
<!-- 指定hadoop临时目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/opt/hadoop-3.3.1/data/tmp</value>
</property>
<!-- 修改访问垃圾回收站用户名称,默认是dr.who,修改为当前用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>root</value>
</property>
<!-- 指定zookeeper地址 -->
<property>
<name>ha.zookeeper.quorum</name>
<value>hbase1:2181,hbase2:2181,hbase3:2181</value>
</property>
</configuration>
修改 /opt/hadoop-3.3.1/etc/hadoop/hdfs-site.xml ,在 <configuration> </configuration> 中添加内容
<configuration>
<property>
<name>dfs.replication</name>
<value>2</value>
</property>
<property>
<name>dfs.permissions.enabled</name>
<value>false</value>
</property>
<!--指定hdfs的nameservice为mycluster,需要和core-site.xml中的保持一致 -->
<property>
<name>dfs.nameservices</name>
<value>mycluster</value>
</property>
<!-- mycluster下面有两个NameNode,分别是nn1,nn2 -->
<property>
<name>dfs.ha.namenodes.mycluster</name>
<value>nn1,nn2</value>
</property>
<!-- RPC通信地址 -->
<property>
<name>dfs.namenode.rpc-address.mycluster.nn1</name>
<value>hbase1:8020</value>
</property>
<property>
<name>dfs.namenode.rpc-address.mycluster.nn2</name>
<value>hbase2:8020</value>
</property>
<!-- http通信地址 -->
<property>
<name>dfs.namenode.http-address.mycluster.nn1</name>
<value>hbase1:9870</value>
</property>
<property>
<name>dfs.namenode.http-address.mycluster.nn2</name>
<value>hbase2:9870</value>
</property>
<!-- 指定NameNode的edits元数据在JournalNode上的存放位置 -->
<property>
<name>dfs.namenode.shared.edits.dir</name>
<value>qjournal://hbase1:8485;hbase2:8485;hbase3:8485/mycluster</value>
</property>
<!-- 指定JournalNode在本地磁盘存放数据的位置 -->
<property>
<name>dfs.journalnode.edits.dir</name>
<value>/opt/hadoop-3.3.1/journaldata</value>
</property>
<!-- 开启NameNode失败自动切换 -->
<property>
<name>dfs.ha.automatic-failover.enabled</name>
<value>true</value>
</property>
<!-- 配置失败自动切换实现方式 -->
<property>
<name>dfs.client.failover.proxy.provider.mycluster</name>
<value>org.apache.hadoop.hdfs.server.namenode.ha.ConfiguredFailoverProxyProvider</value>
</property>
<!-- 配置隔离机制方法,多个机制用换行分割,即每个机制暂用一行-->
<property>
<name>dfs.ha.fencing.methods</name>
<value>
sshfence
</value>
</property>
<!-- 使用sshfence隔离机制时需要ssh免登陆 -->
<property>
<name>dfs.ha.fencing.ssh.private-key-files</name>
<value>/root/.ssh/id_rsa</value>
</property>
<!-- 配置sshfence隔离机制超时时间 -->
<property>
<name>dfs.ha.fencing.ssh.connect-timeout</name>
<value>30000</value>
</property>
</configuration>
修改 /opt/hadoop-3.3.1/etc/hadoop/yarn-site.xml ,在 <configuration> </configuration> 中添加内容
<configuration>
<!-- 开启RM高可用 -->
<property>
<name>yarn.resourcemanager.ha.enabled</name>
<value>true</value>
</property>
<!-- 指定RM的cluster id -->
<property>
<name>yarn.resourcemanager.cluster-id</name>
<value>yrc</value>
</property>
<!-- 指定RM的名字 -->
<property>
<name>yarn.resourcemanager.ha.rm-ids</name>
<value>rm1,rm2</value>
</property>
<!-- 分别指定RM的地址 -->
<property>
<name>yarn.resourcemanager.hostname.rm1</name>
<value>hbase3</value>
</property>
<property>
<name>yarn.resourcemanager.hostname.rm2</name>
<value>hbase2</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm1</name>
<value>hbase3:8088</value>
</property>
<property>
<name>yarn.resourcemanager.webapp.address.rm2</name>
<value>hbase2:8088</value>
</property>
<!-- 指定zk集群地址 -->
<property>
<name>yarn.resourcemanager.zk-address</name>
<value>hbase1:2181,hbase2:2181,hbase3:2181</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
<property>
<name>yarn.log-aggregation-enable</name>
<value>true</value>
</property>
<property>
<name>yarn.log-aggregation.retain-seconds</name>
<value>106800</value>
</property>
<!--启用自动恢复,当任务进行一半,rm坏掉,就要启动自动恢复,默认是false-->
<property>
<name>yarn.resourcemanager.recovery.enabled</name>
<value>true</value>
</property>
<!--指定resourcemanager的状态信息存储在zookeeper集群,默认是存放在FileSystem里面。-->
<property>
<name>yarn.resourcemanager.store.class</name>
<value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value>
</property>
</configuration>
修改 /opt/hadoop-3.3.1/etc/hadoop/mapred-site.xml ,在 <configuration> </configuration> 中添加内容
<configuration>
<!-- 指定mr框架为yarn方式 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>hbase3:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>hbase3:19888</value>
</property>
</configuration>
修改 /opt/hadoop-3.3.1/etc/hadoop/workers
hbase1 hbase2 hbase3
启动journalnode
首先确保已启动zookeeper集群,在所有主机执行
hdfs --daemon start journalnode
格式化namenode
仅在hbase1执行
hdfs namenode -format
启动namenode
仅在hbase1执行
hdfs --daemon start namenode
同步元数据到
仅在hbase2执行
hdfs namenode -bootstrapStandby
检查hbase1和hbase2的 /opt/hadoop-3.3.1/data/dfs/name/current/VERSION 的文件内容,若一致则同步成功
格式化ZKFC
仅在hbase1上执行
hdfs zkfc -formatZK
启动启动HDFS
仅在hbase1上执行
start-dfs.sh
访问hbase1:9870,hbase2:9870验证
启动yarn
start-yarn.sh
访问hadoop web页面
创建hadoop维护脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hadoop 集群 ==================="
echo " --------------- 启动 hdfs ---------------"
ssh hbase1 "/opt/hadoop-3.3.1/sbin/start-dfs.sh"
echo " --------------- 启动 yarn ---------------"
ssh hbase1 "/opt/hadoop-3.3.1/sbin/start-yarn.sh"
echo " --------------- 启动 historyserver ---------------"
ssh hbase3 "/opt/hadoop-3.3.1/bin/mapred --daemon start historyserver"
;;
"stop")
echo " =================== 关闭 hadoop 集群 ==================="
echo " --------------- 关闭 historyserver ---------------"
ssh hbase3 "/opt/hadoop-3.3.1/bin/mapred --daemon stop historyserver"
echo " --------------- 关闭 yarn ---------------"
ssh hbase1 "/opt/hadoop-3.3.1/sbin/stop-yarn.sh"
echo " --------------- 关闭 hdfs ---------------"
ssh hbase1 "/opt/hadoop-3.3.1/sbin/stop-dfs.sh"
;;
"status")
echo " =================== 查看 hadoop 集群 ==================="
for host in hbase1 hbase2 hbase3
do
echo =============== $host ===============
ssh $host jps | grep -v Jps
done
;;
*)
echo "Input Args Error..."
;;
esac
修改hbase环境文件
在所有主机上进行操作
修改 /opt/hbase-2.4.9/conf/hbase-env.sh ,添加:
export JAVA_HOME="/opt/jdk1.8.0_231" export HBASE_PID_DIR="/opt/hbase-2.4.9/" export HBASE_MANAGES_ZK=false
修改hbase配置文件
在所有主机上进行操作
修改 /opt/hbase-2.4.9/conf/hbase-site.xml ,在 <configuration> </configuration> 中添加内容
<configuration>
<property>
<name>hbase.cluster.distributed</name>
<value>true</value>
</property>
<!-- 设置HRegionServers共享目录 -->
<property>
<name>hbase.rootdir</name>
<value>hdfs://mycluster/hbase</value>
</property>
<!-- 指定Zookeeper集群位置 -->
<property>
<name>hbase.zookeeper.quorum</name>
<value>hbase1:2181,hbase2:2181,hbase3:2181</value>
</property>
<!-- 指定独立Zookeeper安装路径 -->
<property>
<name>hbase.zookeeper.property.dataDir</name>
<value>/opt/apache-zookeeper-3.6.3-bin</value>
</property>
<!-- 指定ZooKeeper集群端口 -->
<property>
<name>hbase.zookeeper.property.clientPort</name>
<value>2181</value>
</property>
<property>
<name>hbase.tmp.dir</name>
<value>/opt/hbase-2.4.9/tmp/</value>
</property>
<property>
<name>hbase.unsafe.stream.capability.enforce</name>
<value>false</value>
</property>
<property>
<name>dfs.datanode.max.transfer.threads</name>
<value>4096</value>
</property>
<!-- 文件异步读写配置 -->
<property>
<name>hbase.wal.provider</name>
<value>filesystem</value>
</property>
</configuration>
修改 /opt/hbase-2.4.9/conf/regionservers
hbase1 hbase2 hbase3
新建 /opt/hbase-2.4.9/conf/backup-masters
hbase3
将hadoop两个配置文件复制到hbase目录
cp /opt/hadoop-3.3.1/etc/hadoop/{core-site.xml,hdfs-site.xml} /opt/hbase-2.4.9/conf/
启动hbase
start-hbase.sh
访问hbase的web界面
创建hbase维护脚本
#!/bin/bash
if [ $# -lt 1 ]
then
echo "No Args Input..."
exit ;
fi
case $1 in
"start")
echo " =================== 启动 hbase 集群 ==================="
ssh hbase1 "/opt/hbase-2.4.9/bin/start-hbase.sh"
;;
"stop")
echo " =================== 关闭 hbase 集群 ==================="
ssh hbase1 "/opt/hbase-2.4.9/bin/stop-hbase.sh"
;;
"status")
echo " =================== 查看 hbase 集群 ==================="
for host in hbase1 hbase2 hbase3
do
echo =============== $host ===============
ssh $host jps | grep -v Jps
done
;;
*)
echo "Input Args Error..."
;;
esac

 浙公网安备 33010602011771号
浙公网安备 33010602011771号