Python机器学习笔记(5)—K均值聚类—KMeans
一、内容目录
1,算法原理
2,数据模型
二、算法原理
2.1 聚类
聚类是数据挖掘中的概念,属于无监督学习,本质是分类,就是按照某个特定标准把一个数据集分割成不同的类或者簇,使得同一个簇内的数据对象的相似性
尽可能大,同时不在同一个簇中的数据对象差异性也尽可能的大,即同一类的数据尽可能聚集到一起,不同类数据尽量分离。
2.2 K值
将数据分为K类,即选择K个点作为质心,将每个点指派到最近的质心,形成K个簇,重新计算每个簇的质心,直到簇不发生变化或者达到最大迭代次数。
2.3 局限性
1,需要指定K值,常规下我们并不知道要区分多少类;
2,对于部分场景的分类并不是最优
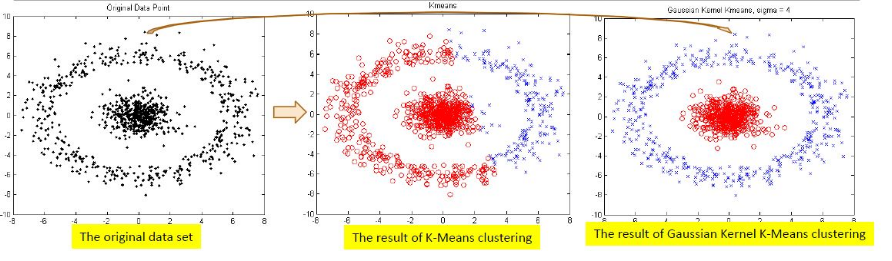
3,对于异常值的处理不够精细
三、数据模型
3.1 示范数据
%matplotlib inline
import matplotlib as mpl
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
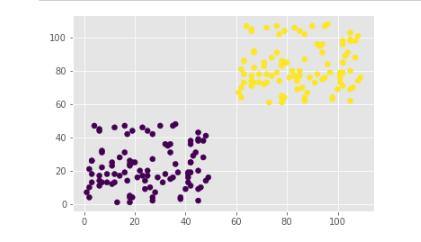
创建随机数据集
data1 = pd.DataFrame({'X':np.random.randint(1,50,100),'Y':np.random.randint(1,50,100)})
data = pd.concat([data1 + 60, data1])
进行数据训练(训练过程就是预测过程)
from sklearn.cluster import KMeans
y_pred = KMeans(n_clusters=2).fit_predict(data)
视图展示
plt.style.use('ggplot')
plt.scatter(data.X, data.Y, c = y_pred) # 按预测值区分颜色
plt.show()
对分类效果进行评估
from sklearn import metrics
metrics.calinski_harabasz_score(data, y_pred)
>>>`931.1524579263571`
3.2 小麦数据集分类
导入数据集,该处使用的是经典的小麦数据集,可以百度下载,自行设置保存路径
data = pd.read_csv('datasets/seeds_dataset.txt',header=None, delim_whitespace=True, names=['x1','x2','x3','x4','x5','x6','x7','y'])
数据预处理
#选择前7个特征,分3类
y_pred = KMeans(n_clusters=3).fit_predict(data[['x1', 'x2', 'x3', 'x4', 'x5', 'x6', 'x7']])
# 转换成Series方便与原数据分类对比
y_pre = pd.Series(y_pred)
# 转换成和原数据相同的分类
y_pre = y_pre.map({0:1,1:1,2:3})
# 将预测数据和元数据合并成df
data_p = pd.DataFrame({'y_pre':y_pre, 'y':data.y})
# 对比预测数据和原数据
data_p['acc'] = data_p.y_pre == data_p.y
计算预测准确率
data_p.acc.sum()/len(data_p)
>>>`0.61428571428571432`

 浙公网安备 33010602011771号
浙公网安备 33010602011771号