MongoDB的一些高级语法
MongoDB的一些高级语法
在前面的博客中,我们了解一些Mongodb中最基础的用法,只介绍了简单的增删查改,在这篇博客中,我将介绍一下稍微复杂一点的语法。
AND 和 OR操作
AND操作
在前面的博客中,我们介绍了查找命令,其中可以指令多个查询条件,当所有条件都符合时,就可以查询到数据。那么,如果我们只想只要有一个条件符合,就返回想要的数据,那么我们应该怎么做呢?
db.getCollection('test_data_1').find({"字段1":"固定值1","字段2":"固定值2"})在上面的命令中,实际上是一个隐式的AND,因为需要同时满足。但是又没有出现AND这个关键词,所以被称为“隐式AND操作”。下面,就让我们来将隐式转为显式,只需要使用“$and”即可。
db.getCollection('test_data_1').find(
{
"$and":[
{"字段1":"固定值1"},
{"字段2":"固定值2"}
]
}
)OR操作
or操作就是为了查询只符合其中任一条件的数据。命令语法和显式的AND操作一样。
db.getCollection('test_data_1').find(
{
"$or":[
{"字段1":"固定值1"},
{"字段2":"固定值2"}
]
}
)其中,我们需要知道,尽管存在隐式的AND操作,但是,对于OR操作来说,不存在隐式的OR操作。 同时or操作时会遵循一个"短路原则":只要前面的条件满足了,那后面的条件直接跳过(类似编程中的||)。
嵌入式文档
下面便是一个嵌入式文档的例子:
我们可以看到在studyInfo中,还有着score和project。其中,studyInfo被称为嵌入式文档,studyInfo下面的字段被称为嵌套字段

插入
下面是一个插入语句的示例。
db.getCollection('test_data_1').insertOne(
{
"age":18,
"adress":"Hunan",
"studyInfo":{
"score":59,
"project":"LOL"
}
}
)查询
查询语句
如果我们需要根据嵌入式文档中的嵌套字段的条件去查询,那么下面这样使用就行了。如果嵌套字段里面还有嵌入式文档,一路点点点过去就行了。
db.getCollection('test_data_1').find(
{
"studyInfo.score":59
},
// 不返回studyInfo.score
{
"studyInfo.score":0
}
)数组(Array)字段
插入
在下面中,like字段保存的就是一个数组,所以我们使用**[]**将"apple","orange","fruit"括起来。
db.getCollection('test_data_1').insertOne(
{
"name":"Array",
"like":["apple","orange","fruit"]
}
) 使用Robo3T可视化工具查看,显示如下:

查询
其中,like的类型为Array。但是如果我们查询的时候需要根据like中某个值作为筛选目标的时候,我们怎么办呢?我们无需进行其他任何操作(和以前的查询一模一样)。例如查询所有喜欢orange的人:
db.getCollection('test_data_1').find({"like":"orange"})也就是说它的查询与以前没有任何区别。但是,既然是数组,总有一定其他的操作,例如查询字段数组为长度的记录:
db.getCollection('test_data_1').find({"like":{"$size":3}})上面是查询like字段的数组长度为3的记录。
注意:“$size”只能查询某一个具体长度的数组,而不能查询范围,如果进行范围查询的话,会报错:

当然,既然有数组,那么必然会有索引,在mongodb中,数组的第一个元素的索引为0,和大部分的编程的情况是一样的。
我们可以通过“字段名.索引”来定位元素。例如查询:
db.getCollection('test_data_1').find(
{
"like.0":"apple"
}
)聚合(Aggregation)
聚合的功能很简单,就是让Mongodb来处理数据,然后返回被处理好的数据。
聚合的操作命令是“aggregation”,基本格式是:
db.getCollection('test_data_1').aggregation([阶段1,阶段2,阶段3……])集中,阶段可以为零个(那么就相当于findi命令),也可以为任意数量。其中,阶段中间有点类似linux或者unix中的管道

也就是说,前面一个阶段的输出,是后面一个结点的输入。
下面是来自菜鸟教程的一些关键字的用法。
- $project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
- $match:用于过滤数据,只输出符合条件的文档。$match使用MongoDB的标准查询操作。
- $limit:用来限制MongoDB聚合管道返回的文档数。
- $skip:在聚合管道中跳过指定数量的文档,并返回余下的文档。
- $unwind:将文档中的某一个数组类型字段拆分成多条,每条包含数组中的一个值。
- $group:将集合中的文档分组,可用于统计结果。
- $sort:将输入文档排序后输出。
- $geoNear:输出接近某一地理位置的有序文档。
下面我将在一些数据的处理方面来介绍一下其中的一些命令。
筛选数据
筛选数据的功能乍一看和find的功能差不多,然后仔细一看,还真的和find的功能一模一样。筛选数据的关键字是“ $match”
db.getCollection('test_data_1').aggregate([{"$match":{和find完全一样的过滤表达式}}])下面是返回like字段数组的第一个元素为“apple”的记录(和上面数组字段里面查询返回的结果一模一样)。
db.getCollection('test_data_1').aggregate([{"$match":{"like.0":"apple"}}])那么,这样做有什么意义呢?返回的结果和find的命令一样,还比find麻烦,这样做岂不是多此一举。的确,如果我们仅仅这样做,还不如使用find,它的强大之处在于与其他关键字进行组合。因为进行数据处理,一般第一步都是进行筛选。
修改字段
前面我们介绍了$project的介绍,那么修改字段我们将使用$projecto来操作。
$project:修改输入文档的结构。可以用来重命名、增加或删除域,也可以用于创建计算结果以及嵌套文档。
正如上面所介绍的,$project的功能很强大,可以做到很多事情。
-
修改返回的字段
下面返回的字段中不包含_id和like 字段
db.getCollection('test_data_1').aggregate([ {"$project":{"_id":0,"like":0}} ])下面是结合$match的使用,其中前面的$match的返回的输出是$project的输入
db.getCollection('test_data_1').aggregate([ {"$match":{"like":{"$size":3}}}, {"$project":{"_id":0,"like":0}} ])这个的作用也和find中的返回返回部分字段的操作差不多,这个操作没有什么让人新奇的地方,下面将介绍它的其他强大之处。
注意事项
包括现有字段
_id字段默认包含在输出文档中。- 如果指定包含文档中不存在的字段, $project 将忽略该字段包含,并且不会将该字段添加到文档中。
取消_id字段
- 默认情况下,
_id字段包含在输出文档中。要从输出文档中排除_id字段,必须在 $project 中明确指定对_id字段的抑制。
排除字段
-
如果指定排除某个或多个字段,则在输出文档中返回所有其他字段。
-
如果指定排除
_id以外的字段,则不能使用任何其他 $project 规范表单:即,如果排除字段,则不能指定包含字段,重置现有字段的值或添加新字段。
-
添加新的字段
如果我想返回的结果中添加新的字段,怎么办?在project中直接添加就行
db.getCollection('test_data_1').aggregate([ {"$project":{ "name":1, "_id":0, // 添加的新的字段 "add":"GG" } } ])不过值得注意的是:
如果指定排除
_id以外的字段,则不能使用任何其他 $project 规范表单:即,如果排除字段,则不能指定包含字段,重置现有字段的值或添加新字段。也就是说,如果排除了除“_id”以外的字段,那么,就GG了。就没办法添加字段了。

并且值得注意的是,添加新的字段的时候,如果旧的字段不设置为1,则不会返回。(也就是说,如果添加了新的字段,想要返回本来存在字段,必须将字段设置为1)

-
重命名字段
重命名字段和添加新的字段差不多,简单点来说,我们可以使用“$旧的字段名”来表示字段的数据。示例如下
db.getCollection('test_data_1').aggregate([ {"$project":{ // 添加新的字段,新的字段的数据是name字段的数据 "add":"$name" } } ])结果如下:
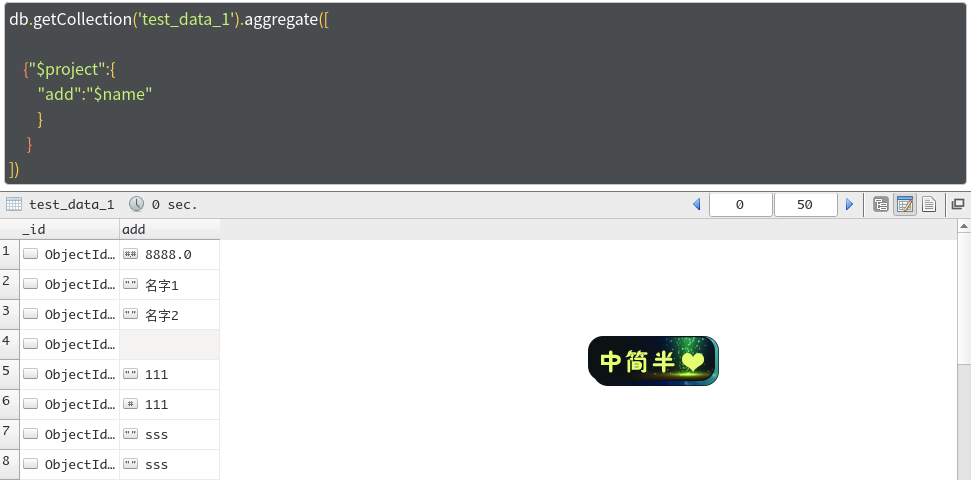
这个对于嵌套文档有着非常好的效果,可以看下面的两个例子
使用find 使用聚合 
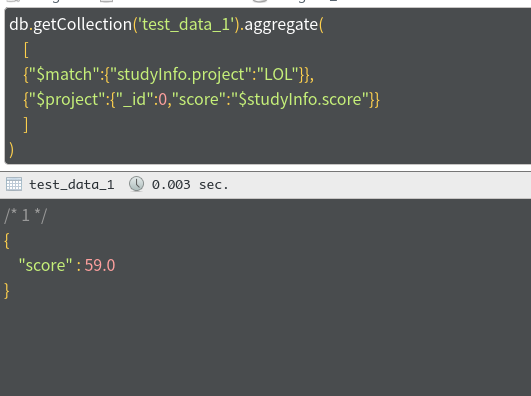
-
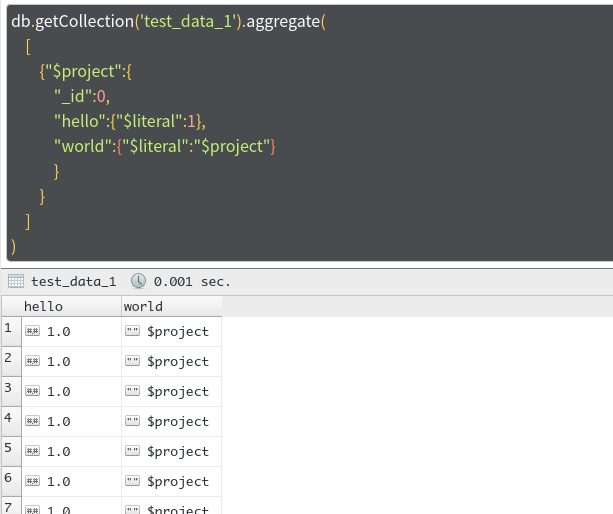
处理特殊字符
这里有说两个问题,如果我需要修改一个字段的数据为1,或者为$project呢?可以知道,这些值与mongodbe自身的语法冲突了(所有以“$”开头的普通字符串和数字都不能添加)。这个时候我们可以使用" $literal"关键字。






分组操作
分组操作所对应的关键字是“$group”,它的作用是根据给出的字段key,它所有的key的值相同的记录放在一起进行运算。
去重
在上一篇博客中使用了去重函数“distinct”,使用该函数后,返回的是一个数组。不过,现在我们可以使用“$group”去重。操作如下所示:
db.getCollection('test_data_1').aggregate(
[
{
"$group":{"_id":"$被g去重的字段名"}
}
]
)其中,“_id”是必不可少的,不能用其他的去替代。而这个返回的也不是一个数组,而是很多条记录。

分组操作运算
首先先说一下运算的关键字,关键字包括(来自菜鸟教程):
| 表达式 | 描述 | 实例 |
|---|---|---|
| $sum | 计算总和。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$sum : "$likes"}}}]) |
| $avg | 计算平均值 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$avg : "$likes"}}}]) |
| $min | 获取集合中所有文档对应值得最小值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$min : "$likes"}}}]) |
| $max | 获取集合中所有文档对应值得最大值。 | db.mycol.aggregate([{$group : {_id : "$by_user", num_tutorial : {$max : "$likes"}}}]) |
| $push | 在结果文档中插入值到一个数组中。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$push: "$url"}}}]) |
| $addToSet | 在结果文档中插入值到一个数组中,但不创建副本。 | db.mycol.aggregate([{$group : {_id : "$by_user", url : {$addToSet : "$url"}}}]) |
| $first | 根据资源文档的排序获取第一个文档数据。 | db.mycol.aggregate([{$group : {_id : "$by_user", first_url : {$first : "$url"}}}]) |
| $last | 根据资源文档的排序获取最后一个文档数据 | db.mycol.aggregate([{$group : {_id : "$by_user", last_url : {$last : "$url"}}}]) |
大家看那个实例估计也明白怎么操作了。首先我们先去重,然后再指定名字,最后进行计算:
计算的方法:{$关键字:$已有的字段名}
下面便是计算age的平均值,然后以“aver_age”返回。

原则上,“$sum”和“$avg”的值对应的值应该是数字,如果使用非数字,则“$sum”会返回0,“$avg”会返回“null”。注意,字符串是可以比较大小的。其中,“$sum”的值还可以使用数字“1”,例如
"count":{"$sum":1},则返回的就是每个分组有多少条记录。
拆分数组
拆分数组使用的关键字是“$unwind”,它的作用是把一条包含数组的记录拆分为很对条记录,其中,每一条记录拥有数组中的一个元素。
下面是数组like和infos进行拆分,其中拆分的结果数量是like数组的长度乘以infos数组的长度。
db.getCollection('test_data_1').aggregate(
[
{"$unwind":"$like"},
{"$unwind":"$infos"},
]
)

联集合查询
Mongodb中的联集合查询类似SQL中的联表查询,在联集合查询中,有两个概念,主集合和被查集合。简单点来说,就是主集合提供字段key,然后被查集合通过字段key查出需要的字段。
db.getCollection('主集合名').aggregate([
"$lookup":{
"from":"被查集合名",
"localField":"主集合提供的字段key",
"foreginField":"被查集合接受的字段",
"as":"为查出来的字段命名",
}
]
)下面是两个文档,一个为user,一个为login


现在我们通过login中的id从user中拿出字段:
db.getCollection('login').aggregate([
{ "$lookup":{
"from":"user",
"localField":"loginId",
"foreignField":"id",
"as":"login_name",
}
}
]
)返回结果如下:

其中,login_name为联结合查出来的数据,为一个数组。
当然,对于这个结果的样式我们是不太满意的,因为我我们只想拿出name,这个时候我们就需要使用前面的知识来解决这个问题了。
db.getCollection('login').aggregate([
{ "$lookup":{
"from":"user",
"localField":"loginId",
"foreignField":"id",
"as":"login_name",
}
}, {
"$unwind":"$login_name"
},
{
"$project":{
"_id":0,
"loginId":1,
"name":"$login_name.name"
}
}
])返回的结果如图所示:

参考资料
参考书籍:《左手Mongodb,右手Redis》
菜鸟教程:https://www.runoob.com/mongodb/mongodb-tutorial.html
docs4dev:https://www.docs4dev.com/docs/zh/mongodb/v3.6/reference

 浙公网安备 33010602011771号
浙公网安备 33010602011771号