读a paper of ICCV 2017 : Areas of Attention for Image Captioning
前言废话,作者说把代码公布在gitub上,但是迟迟没有公布,我发邮件询问代码情况,邮件也迟迟不回,表示很尴尬。。虽然种种这些,但是工作还是好工作,这个没的黑,那我们今天就来详细的介绍这篇文章。
导论:不了解caption的童鞋可以去看下这两篇知乎专栏:
一:摘要
作者提出了一个新的attention模型,这个模型与以往的区别在于,不仅考虑了状态与预测单词之间的关系,同时也考虑了图像区域与单词,状态之间的两两关系,好处嘛,就是信息考虑的更加全面,考虑的全面总归不是坏事啦~~。
二:baseline
这个图像生成文本的baseline,现在基本就是建立在谷歌的NIC模型上,思路是这样:用预训练好的卷积神经网络参数抽取图像特征,这个是编码部分,然后这个特征作为图像的初始状态,用RNN生成单词,这个是解码部分。示意图如下:(画的有点丑,请轻喷~~)
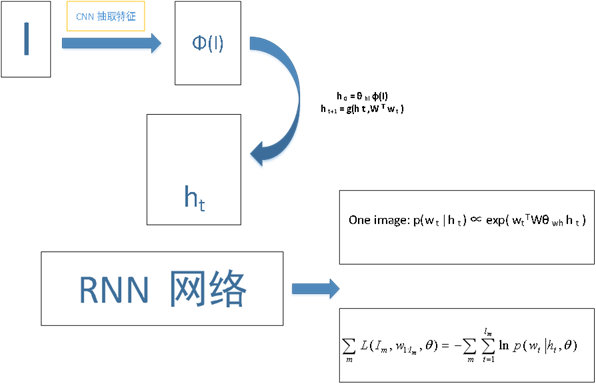
一张照片的损失函数其实就是一个logistic 回归,所有batch 那就是这些损失函数之和。 跟新状态的g 函数,一般就是用一个MLP 模型。当然RNN网络也可以换成和他功能相近的网络比如LSTM ,BLSTM 问题不大。
三:本文的损失函数
3.1 建立了一个联合概率分布: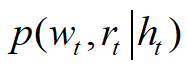
其中已经生成的单词: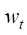
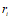 为在时刻t观察到的图像区域。
为在时刻t观察到的图像区域。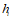 为RNN的内部状态。
为RNN的内部状态。
下面是这篇文章的精华部分,我就不妄加翻译了:

大家可以看,baseline中的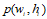 换成了
换成了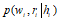 ,这就表示和图像区域扯上了关系,但是具体怎么扯上的呢,这就需要这两两之间的关系了。第一个得分是状态与生成单词之间的关系,第二个是图像区域与生成单词之间的关系,第三个是状态与图像之间的关系,这个第三个关系也就是attention所要解决的问题。后面两个我们不管他,就是个bias.
,这就表示和图像区域扯上了关系,但是具体怎么扯上的呢,这就需要这两两之间的关系了。第一个得分是状态与生成单词之间的关系,第二个是图像区域与生成单词之间的关系,第三个是状态与图像之间的关系,这个第三个关系也就是attention所要解决的问题。后面两个我们不管他,就是个bias.
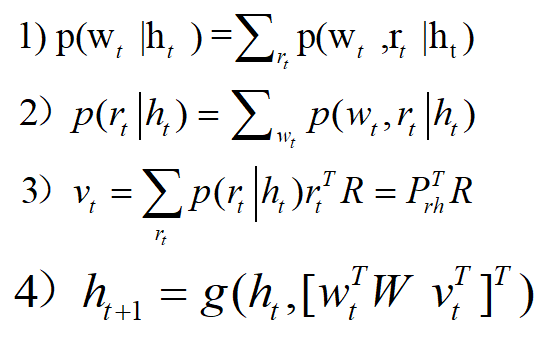
公式1,我是这样理解的,所有区域生成单词的可能性加起来就形成了在状态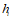 下生成单词的可能性。
下生成单词的可能性。
公式2,生成某一个单词的所有区域加起来,就是我们需要的attention 感兴趣的概率。
公式3,这就是attention的模型,状态ht下对图像某一区域感兴趣的概率。
公式4,状态更新机制,生成单词与感兴趣图像区域反馈RNN状态。
整个流程图如下:
四:Areas of attention的获取
4.1 Activiation grid:
类似于这样:

强制划分图像区域。当然这样显得有点粗糙。
4.1 object proposals
用目标检测的方法把每一个目标的给标出来,我们人为它是目标实例。

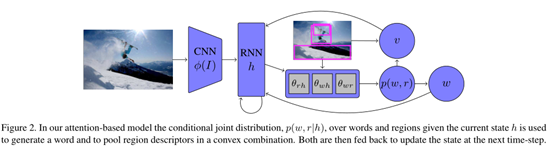
4.3 Spatial transformers 这一块说实话我认为是作者故意加篇幅的,本质上没有什么创新,简单来时是研究卷积神经网络的旋转,平移不变性,以前主要的都是通过数据增强的方法,强制去学习特征,而这个方式是加了一层trick,这样就有效的解决了这个问题。
具体的大家可以参考这篇博文:Spatial transformers
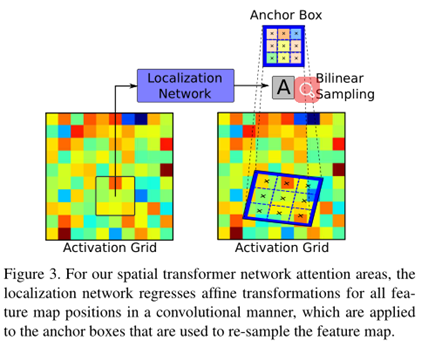
4.4 关注区域选择总结
5 总结
工作是个好工作,没代码,不开心。。。哈哈,祝大家周末愉快~~~!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号