读:Instance-aware Image and Sentence Matching with Selective Multimodal LSTM
摘要:有效图像和句子匹配取决于如何很好地度量其全局视觉 - 语义相似度。基于观察到这样的全局相似性是由图像(对象)和句子(词)的成对实例之间的多个局部相似性的复合聚集,我们提出了一个实例感知图像和句子匹配的选择性多模态长期短期记忆网络(sm-LSTM)。 sm-LSTM在每个时间步包含一个多模式的上下文调制的注意方案,通过预测图像和句子的成对实例显着图,可以选择性地关注一对图像和句子的实例。对于选定的成对实例,它们的表示是基于预测的显着图获得的,然后进行比较以测量它们的局部相似性。通过在几个时间步长内类似地测量多个局部相似性,sm-LSTM依次将它们与隐藏状态聚合,以获得作为期望的全局相似性的最终匹配分数。大量的实验表明,我们的模型能够很好的匹配图像和句子,并且可以在两个公开的基准数据集上得到最新的结果。
介绍:
图像与文本匹配在很多应用中有着重要的作用,在图像文本跨模态检索任务中,当给定查询文本,需要依据图像文本的相似性去检索内容相似的图像;在图像描述生成任务中,给定一幅图像,需要依据图像内容检索相似的文本,并以此作为(或者进一步生成)图像的文本描述;在图像问答任务中,需要基于给定的文本问题查找图像中包含相应答案的内容,同时查找的视觉内容反过来也需要检索相似文本预料作为预测答案。
研究现状:
现在这方面的研究主要包含两个类:(1)一对一的匹配 (2)多到多的匹配。
(1)一对一的匹配
通常就是抽取全局图像和文本的全局特征,然后使用一个结构化的框架使他们联系起来,或者或者用典型相关的目标公式,寻找最大相关性。但是这种匹配方式只是粗略度量的图像文本的全局相似度,并没有具体的考虑图像文本具体是哪些局部内容在语义上是相似的,因此在一些要求精准相似性度量的任务中,例如细粒度的跨模态检索等,其实验精度往往较低。
(2)多对多的匹配
对多对多的匹配通常是找到一些局部的相似性,然后聚合成一个全局的相似性。但是这些方法所提取的实例并不都刻画了语义概念,事实上,大部分实例都是语义上毫无意义且与匹配任务无关的(冗余的信息),只有少部分显著的语义实例决定了匹配程度的好坏。那些冗余的实例也可认为是一些噪声干扰了少部分语义实例的匹配过程,并增加了模型计算量。此外,现有方法的在实例提取过程中通常需要显式的使用额外目标检测算法或者昂贵的人工标注。
Se-LSTM:
Se-LSTM 主要来自三个方面:
- 图像和句子的实例候选提取
- 实例感知图像和句子匹配的选择性多模态长期短期记忆网络(sm-LSTM)。 sm-LSTM在每个时间步包含一个多模式的上下文调制的注意方案。
- 局部相似性度量和多模式LSTM的聚合。
实例候选提取:
- 句子实例候选:
简单地将句子进行标记化和分解为单词,然后通过双向LSTM(BLSTM)顺序处理它们来获得它们的表示,其中学习具有不同方向(前向和后向)的两个隐藏状态序列。 我们在相同的时间步将两个方向隐藏状态的向量连接成相应输入字的表示。
- 图像实例候选
对于一个图像,直接找到实例是非常困难的,因为视觉内容是没有组织的,每一个实例可能出现在任何一个位置,而且大小也是不确定的,为了避免使用额外的目标检测器,最终文章把图像分成了很多的块。(一直感觉这里不太严谨)如下图,然后通过他们抽取的CNN特征(最后卷积层输出的特征),然后把同一位置的卷积特征映射连接起来作为这一区域的图像特征。
![]()
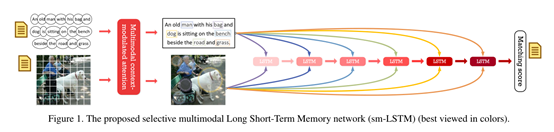
这是整个算法的框架图。首先把对文本取词,找出实例,然后对图像取词,不同的LSTM 颜色代表不同的时候,然后总和称为一个匹配分数。下面给出一个单层的LSTM实例图:
![]()
他这里主要有一个attention机制。就是说我前面选择的实例不在选择,其中的
![]() 就是上一个时刻的相似度。
就是上一个时刻的相似度。
其中文本那一行亮色的dog表示这一时刻选择他的可能性最大,图像中的文本狗头也表示这一时刻的可能性最大。。。。
![]()
这张图解释了,假设全局卷积中有狗和人,但是上一个阶段匹配了人,那么这一个阶段就要去掉人。。。以此类推,我感觉也可以用图论的观点去分析它。。。。
![]()
图像与文本的,t时刻时候,第i 个图像实例,或者第j个文本实例被关注的可能性。其中m是图像的全局特征维数,n 是文本的全局特征维数。下面是参数的介绍。
![]()
总结下:亮点是这个attention机制。。。以后文章可以用到这个思想。

 就是上一个时刻的相似度。
就是上一个时刻的相似度。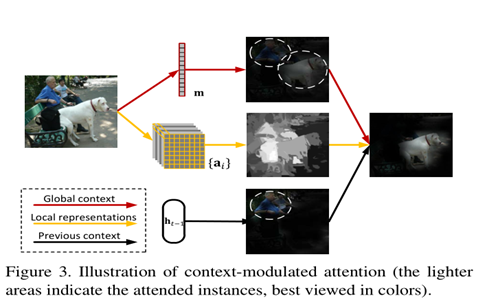



 浙公网安备 33010602011771号
浙公网安备 33010602011771号