FaceNet---深度学习与人脸识别的二次结合
今天我给大家带来一篇来自谷歌的文章,众所周知,谷歌是全世界最有情怀,最讲究技术的公司,比我们天朝的莆田广告商良心多了。还有就是前段时间的最强大脑,莆田广告商的那个小机器,也就忽悠忽悠行外人了,懂的人深深知道。感觉自己就是黑子,当然,最强大脑节目组本身就是演员。
传统的进行人脸识别的模型一般都是这样:



但是现在我们要换个思路了,facenet直接学习图像到欧式空间上的映射,那么如果两张图片在欧式空间的距离很近,是不是说明就是很相似?如果离得远就不相似,也就不是同一个人?
下面的图详细的说明了,具体过程。

你看如果是一个人的照片,他们的距离就会低于这个阀值,此处应该是1.05左右。这个有点类似于LDA的思想了。类内的距离就小,类间的距离就大,其实本质上并没有什么差别。
Facenet的结构如下图:

前面就是一个传统的卷积神经网络,然后在求L2范数之前进行归一化,就建立了这个嵌入空间,最后的损失函数,就是本文的最大亮点。
Triplet loss三重损失函数:以前我们的损失函数一般都是一个的,或者是两个的。这里弄三个,结构图如下:
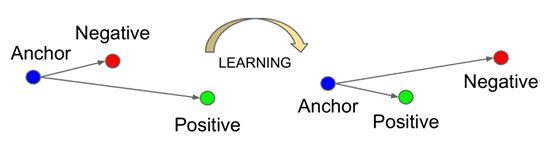
我来带大家理解这个结构图。现在我们有一个样本名字叫anchor,还有两个样本名字叫positive,另外一个叫Negative。一开始啊,我们都以为这个三个人是亲兄弟,但是呢Negative一个是隔壁老王的,而且这个人和我们的Anchor关系很好,这不行,这是仇人的孩子,我们得让这两个人远离,于是我们就让神经网络学习,让positive和anchor近一点,让Negative滚蛋。(当然例子可能取的不恰当,还请见谅,哈哈)
课外补充:在高维或者无穷维中,距离的度量没有意义的,因为他们都在一个超球面上,你又如何度量他们的远近呢(这就是为什么不能直接用KNN分类的原因,他在处理高维数据就玩不转了),所以我们才要用深度卷积神经网络进行训练啊,至于其中的原理,神经网络就是一个黑匣子,我不懂啊,鬼知道他是怎么玩的。
记住下面的所有数据都是经过归一化的,没有经过归一化求距离就是胡扯!
 ,
,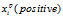 和
和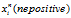 分别代表三个不同的样本,我们一定想要:
分别代表三个不同的样本,我们一定想要:
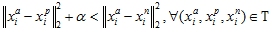
这个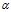 是我们前面所说的参数。
是我们前面所说的参数。
那么我们的优化函数就出来了:
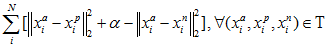
优化问题解决:
但是呢,知道这些还不够,为什么呢,一个算法的优劣,还要通过他的时间复杂度来判断,这里一定要确保他的收敛速度。
那么我们怎做呢,其实也很简单,假设给你一个anchor,我们找一个positive就要在这一类中找到一个最难分类的,什么样叫最难分类呢,就是在欧式空间距离最远的那个,但是属于一类,这叫hard_positive,另外找nepositive那就找最近的,这样不就完美解决了么。当然在找nepositive很容易产生局部最优,所以我们要满足: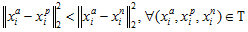 。这叫semi-hard,防止找到他一类里了。
。这叫semi-hard,防止找到他一类里了。
本文的CNN结构:
一种是来自M. D. Zeiler and R. Fergus. Visualizing and understanding convolutional networks. CoRR, abs/1311.2901, 2013. 2, 4, 6。
结构:
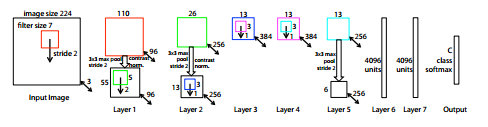
另一种来自:C. Szegedy, W. Liu, Y. Jia, P. Sermanet, S. Reed,D. Anguelov, D. Erhan, V. Vanhoucke,and A. Rabinovich.Going deeper with convolutions. CoRR, abs/1409.4842,2014. 2, 4, 5, 6, 9
结构:

结果在LFW上正确率很高,在这里我就不说了。
论文:FaceNet: A Unified Embedding for Face Recognition and Clustering

 浙公网安备 33010602011771号
浙公网安备 33010602011771号