机器学习实战-----八大分类器识别树叶带源码
今天我想送给大家两句话:1:在这个浮躁的社会中,每个人都想找到捷径,那么我想认真踏实地做好一件事也便是最大的捷径了。2:不要管别人做什么,有自己的目标,可能你现在的环境牛人多多,让你压力巨大,也可能你身处的环境废物多多,让你感慨你本可以让自己更加强大。不要管这些,只要相信自己选择的,走下去。
以上献给迷茫的人们,同时也自勉。不多说,进入八大分类器。
引言:树叶有好多种,如下图:

目标:写一个系统,让系统区分各种树叶属于哪个品种。
我的思路如下图:



特征提取:也就是我们前几张说的xi,抽取能代表这个物体的特征。比如让你去识别另外一个人,一般从脸型,肤色,身高,体重…..这些特征去标记,现在计算机识别树叶可能就从叶子啊,形状啊,宽度啊,有无锯齿啊,这些去识别。这个详细我们暂时不说,下次再说。
训练分类器:就是找到一个有某些特征的样本,我们只需要对新来的特征和前面出现类似的特征进行比对,那么找出最可能的类别,我们就说这个新的样本是属于这个类别的。
测试数据:当这个模型找出来了,我们是不是得测试一下这个人可不可信对吧,就好像我们生活中的,有的人酷爱吹牛逼,那么我们对他说的话,是不是就抱着怀疑的态度?而有的人几乎很少说谎话,那么他说的话是不是可信度就大,这个测试数据就是这个道理,测试效果越好,那么这个模型分类器可能效果就越好。
下面是代码讲解部分,为了方便我先以截图的形式,呈上代码,最后用百度云上传我的数据集和源代码,希望大家学得愉快。
一 代码讲解
这一段代码没什么好说的,就是导入matplotlib,pandas,sklearn的这些包.python这个语言最强大的地方就是可以直接引用别的语言写的代码包,其实python作为一门脚本语言它本身的执行速度是很慢的,但是它就像胶水一样把其他语言实现的功能粘合起来,那么就很厉害了,类似于刘邦,驭人于千里之外。所以它又叫胶水语言。
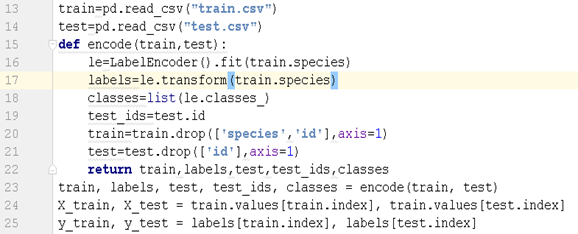
这一段代码是读取train.csv和test.csv数据。然后把train.csv中的species项作为标签项,除了id项,其他项作为特征项。y_test作为数据的原始标签,留着和以后的预测值作比较。

这一段代码就是把k近邻,svc,随机森林这些分类器的名称写在classifiers这个列表里,等着我们之后调用它。Svc我们这里用的是rbf核,也就是高斯核。

这里for 循环就是调用列表里的分类器,然后fit(),也就是训练一下,输入的参数是特征集和标签集,44行,分别用刚刚训练出来的参数,对x_text进行预测,得到预测值。接着再用预测值与原本的样本标签就行比较,求出正确率和损失值。

这一段就是画出结果图没什么好说的。
二 结果分析


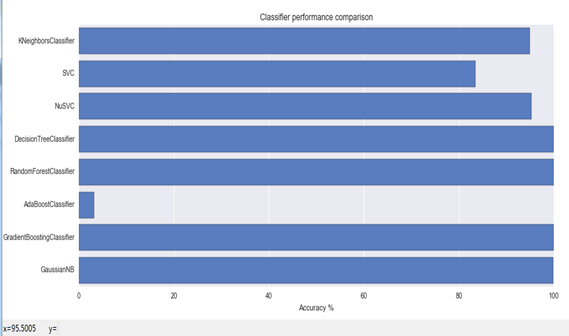
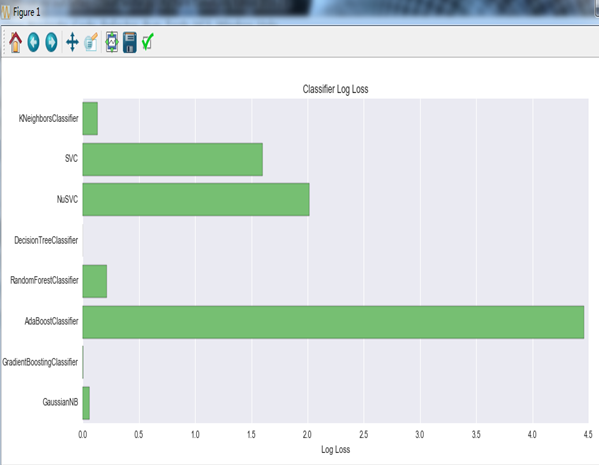
可以看出随机森林和gridentboosting表现最好,这个gridentboosting用梯度下降算法保证最后的结果最好,这个算法就是三个臭皮匠赛过一个诸葛亮。。。。但是Adaboost算法瞬间打我脸有木有,这个的结果差的离谱,我现在还没有想出来是为什么原因。。。。。。等我下次继续做实验验证吧。。
给大家看看ACC和loss图吧,这些都是说明这个模型的靠谱程度,不是那种吹牛逼模式。
三 源码链接
本文的源码百度云链接为:链接:http://pan.baidu.com/s/1kV9ClIR 密码:mv2n
谢谢大家观看。哈哈。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号