手写汉字识别
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import torchvision.transforms as transforms
from torch.utils.data import DataLoader, Dataset, random_split
from torch.optim.lr_scheduler import CosineAnnealingLR, ReduceLROnPlateau
from torch.optim import AdamW, SGD
import torchvision.models as models
from PIL import Image
import numpy as np
import warnings
warnings.filterwarnings("ignore", message=".weights_only.")
设置随机种子以保证可重复性
def set_seed(seed=42):
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = False
set_seed(42)
定义生成图像集路径文档的函数
def classes_txt(root, out_path, num_class=None):
dirs = os.listdir(root)
if not num_class:
num_class = len(dirs)
if not os.path.exists(out_path):
with open(out_path, 'w') as f:
pass
with open(out_path, 'r+') as f:
try:
end = int(f.readlines()[-1].split(' ')[-1]) + 1
except:
end = 0
if end < num_class - 1:
dirs.sort()
dirs = dirs[end:num_class]
for dir in dirs:
files = os.listdir(os.path.join(root, dir))
for file in files:
f.write(os.path.join(root, dir, file) + '\n')
class MyDataset(Dataset):
def init(self, txt_path, num_class, transforms=None):
super().init()
images = []
labels = []
with open(txt_path, 'r') as f:
for line in f:
if int(line.split('\')[-2]) >= num_class:
break
line = line.strip('\n')
images.append(line)
labels.append(int(line.split('\')[-2]))
self.images = images
self.labels = labels
self.transforms = transforms
def getitem(self, index):
image = Image.open(self.images[index]).convert('RGB')
label = self.labels[index]
if self.transforms is not None:
image = self.transforms(image)
return image, label
def len(self):
return len(self.labels)
========== 高级数据增强 ==========
train_transform = transforms.Compose([
transforms.Resize((128, 128)), # 更大的图像尺寸
transforms.RandomRotation(15), # 更大的旋转角度
transforms.RandomAffine(degrees=0, translate=(0.15, 0.15), scale=(0.85, 1.15)), # 平移和缩放
transforms.RandomHorizontalFlip(p=0.5),
transforms.RandomVerticalFlip(p=0.05), # 垂直翻转(少量)
transforms.ColorJitter(brightness=0.3, contrast=0.3, saturation=0.2, hue=0.1),
transforms.RandomGrayscale(p=0.1), # 随机灰度化
transforms.RandomApply([transforms.GaussianBlur(3, sigma=(0.1, 2.0))], p=0.2), # 高斯模糊
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
val_test_transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
========== 高级模型架构 ==========
class AdvancedNet(nn.Module):
def init(self, num_classes=10, dropout_rate=0.5):
super(AdvancedNet, self).init()
第一个卷积块
self.conv1 = nn.Conv2d(1, 64, 3, padding=1)
self.bn1 = nn.BatchNorm2d(64)
self.conv2 = nn.Conv2d(64, 64, 3, padding=1)
self.bn2 = nn.BatchNorm2d(64)
self.pool1 = nn.MaxPool2d(2, 2)
self.dropout1 = nn.Dropout2d(dropout_rate/2)
第二个卷积块
self.conv3 = nn.Conv2d(64, 128, 3, padding=1)
self.bn3 = nn.BatchNorm2d(128)
self.conv4 = nn.Conv2d(128, 128, 3, padding=1)
self.bn4 = nn.BatchNorm2d(128)
self.pool2 = nn.MaxPool2d(2, 2)
self.dropout2 = nn.Dropout2d(dropout_rate/2)
第三个卷积块
self.conv5 = nn.Conv2d(128, 256, 3, padding=1)
self.bn5 = nn.BatchNorm2d(256)
self.conv6 = nn.Conv2d(256, 256, 3, padding=1)
self.bn6 = nn.BatchNorm2d(256)
self.pool3 = nn.MaxPool2d(2, 2)
self.dropout3 = nn.Dropout2d(dropout_rate/2)
第四个卷积块
self.conv7 = nn.Conv2d(256, 512, 3, padding=1)
self.bn7 = nn.BatchNorm2d(512)
self.conv8 = nn.Conv2d(512, 512, 3, padding=1)
self.bn8 = nn.BatchNorm2d(512)
self.pool4 = nn.AdaptiveAvgPool2d((4, 4)) # 自适应池化
self.dropout4 = nn.Dropout2d(dropout_rate/2)
全连接层
self.fc1 = nn.Linear(512 * 4 * 4, 1024)
self.bn9 = nn.BatchNorm1d(1024)
self.dropout5 = nn.Dropout(dropout_rate)
self.fc2 = nn.Linear(1024, 512)
self.bn10 = nn.BatchNorm1d(512)
self.dropout6 = nn.Dropout(dropout_rate)
self.fc3 = nn.Linear(512, num_classes)
def forward(self, x):
# 第一个卷积块
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool1(x)
x = self.dropout1(x)
第二个卷积块
x = F.relu(self.bn3(self.conv3(x)))
x = F.relu(self.bn4(self.conv4(x)))
x = self.pool2(x)
x = self.dropout2(x)
第三个卷积块
x = F.relu(self.bn5(self.conv5(x)))
x = F.relu(self.bn6(self.conv6(x)))
x = self.pool3(x)
x = self.dropout3(x)
第四个卷积块
x = F.relu(self.bn7(self.conv7(x)))
x = F.relu(self.bn8(self.conv8(x)))
x = self.pool4(x)
x = self.dropout4(x)
全连接层
x = x.view(-1, 512 * 4 * 4)
x = F.relu(self.bn9(self.fc1(x)))
x = self.dropout5(x)
x = F.relu(self.bn10(self.fc2(x)))
x = self.dropout6(x)
x = self.fc3(x)
return x
========== 高级训练策略 ==========
def train_advanced_model(model, train_loader, val_loader, num_epochs=50):
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = model.to(device)
使用AdamW优化器
optimizer = AdamW(model.parameters(), lr=0.001, weight_decay=1e-4)
组合学习率调度器
scheduler1 = CosineAnnealingLR(optimizer, T_max=10, eta_min=1e-6)
scheduler2 = ReduceLROnPlateau(optimizer, mode='min', factor=0.5, patience=5, verbose=True)
标签平滑的损失函数
class LabelSmoothingCrossEntropy(nn.Module):
def init(self, smoothing=0.1):
super(LabelSmoothingCrossEntropy, self).init()
self.smoothing = smoothing
def forward(self, x, target):
confidence = 1. - self.smoothing
logprobs = F.log_softmax(x, dim=-1)
nll_loss = -logprobs.gather(dim=-1, index=target.unsqueeze(1))
nll_loss = nll_loss.squeeze(1)
smooth_loss = -logprobs.mean(dim=-1)
loss = confidence * nll_loss + self.smoothing * smooth_loss
return loss.mean()
criterion = LabelSmoothingCrossEntropy(smoothing=0.1)
best_acc = 0.0
patience_counter = 0
patience = 10 # 早停耐心值
for epoch in range(num_epochs):
# 训练阶段
model.train()
running_loss = 0.0
correct_train = 0
total_train = 0
for i, (images, labels) in enumerate(train_loader):
images, labels = images.to(device), labels.to(device)
optimizer.zero_grad()
outputs = model(images)
loss = criterion(outputs, labels)
loss.backward()
梯度裁剪
torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)
optimizer.step()
running_loss += loss.item()
计算训练准确率
_, predicted = torch.max(outputs.data, 1)
total_train += labels.size(0)
correct_train += (predicted == labels).sum().item()
if i % 50 == 49:
print(f'Epoch [{epoch+1}/{num_epochs}], Step [{i+1}/{len(train_loader)}], Loss: {running_loss/50:.4f}')
running_loss = 0.0
train_accuracy = 100 * correct_train / total_train
验证阶段
model.eval()
correct_val = 0
total_val = 0
val_loss = 0.0
with torch.no_grad():
for images, labels in val_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
loss = criterion(outputs, labels)
val_loss += loss.item()
_, predicted = torch.max(outputs.data, 1)
total_val += labels.size(0)
correct_val += (predicted == labels).sum().item()
val_accuracy = 100 * correct_val / total_val
avg_val_loss = val_loss / len(val_loader)
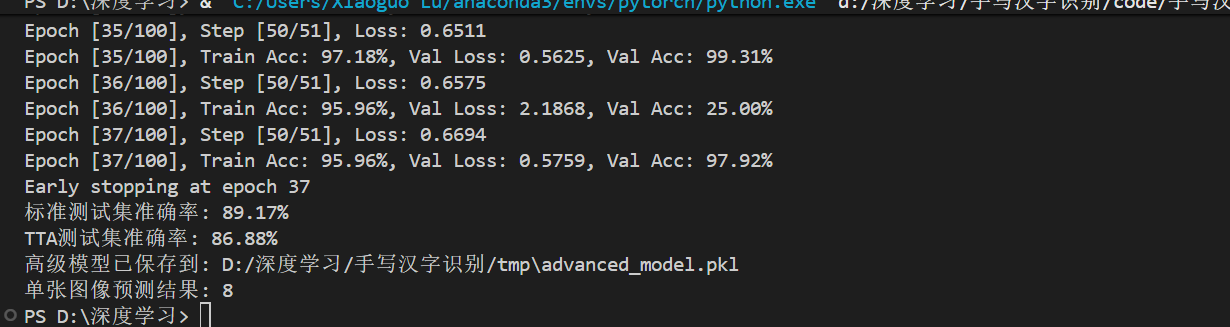
print(f'Epoch [{epoch+1}/{num_epochs}], Train Acc: {train_accuracy:.2f}%, Val Loss: {avg_val_loss:.4f}, Val Acc: {val_accuracy:.2f}%')
学习率调整
scheduler1.step()
scheduler2.step(avg_val_loss)
保存最佳模型
if val_accuracy > best_acc:
best_acc = val_accuracy
torch.save(model.state_dict(), 'best_model.pkl')
print(f'New best model saved with validation accuracy: {best_acc:.2f}%')
patience_counter = 0
else:
patience_counter += 1
早停
if patience_counter >= patience:
print(f'Early stopping at epoch {epoch+1}')
break
return best_acc
创建验证集
def create_datasets(train_txt_path, test_txt_path, num_classes=10):
# 加载完整训练集
full_train_set = MyDataset(train_txt_path, num_classes, transforms=train_transform)
划分训练集和验证集 (85% 训练, 15% 验证)
train_size = int(0.85 * len(full_train_set))
val_size = len(full_train_set) - train_size
train_set, val_set = random_split(full_train_set, [train_size, val_size])
测试集
test_set = MyDataset(test_txt_path, num_classes, transforms=val_test_transform)
return train_set, val_set, test_set
测试时间增强 (TTA)
def test_time_augmentation(model, dataloader, device, num_augmentations=5):
model.eval()
all_predictions = []
all_labels = []
with torch.no_grad():
for images, labels in dataloader:
images, labels = images.to(device), labels.to(device)
batch_predictions = []
原始图像预测
outputs = model(images)
batch_predictions.append(F.softmax(outputs, dim=1))
数据增强预测
augmentations = [
transforms.Compose([
transforms.RandomRotation(10),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
]),
transforms.Compose([
transforms.RandomAffine(degrees=0, translate=(0.1, 0.1)),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
]),
transforms.Compose([
transforms.ColorJitter(brightness=0.2, contrast=0.2),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
]
for aug in augmentations[:num_augmentations-1]:
augmented_images = torch.stack([aug(transforms.ToPILImage()(img)) for img in images.cpu()])
augmented_images = augmented_images.to(device)
outputs = model(augmented_images)
batch_predictions.append(F.softmax(outputs, dim=1))
平均所有预测
avg_predictions = torch.stack(batch_predictions).mean(dim=0)
_, predicted = torch.max(avg_predictions, 1)
all_predictions.extend(predicted.cpu().numpy())
all_labels.extend(labels.cpu().numpy())
accuracy = 100 * np.sum(np.array(all_predictions) == np.array(all_labels)) / len(all_labels)
return accuracy
主函数
def main():
# 使用英文路径避免编码问题
root = 'D:/深度学习/手写汉字识别/data'
model_save_dir = 'D:/深度学习/手写汉字识别/tmp'
首先生成TXT文件
classes_txt(root + '/train', root + '/train.txt', num_class=10)
classes_txt(root + '/test', root + '/test.txt', num_class=10)
创建数据集
train_set, val_set, test_set = create_datasets(
root + '/train.txt',
root + '/test.txt',
num_classes=10
)
创建数据加载器 - 使用较小的批量大小
train_loader = DataLoader(train_set, batch_size=16, shuffle=True, num_workers=0)
val_loader = DataLoader(val_set, batch_size=16, shuffle=False, num_workers=0)
test_loader = DataLoader(test_set, batch_size=16, shuffle=False, num_workers=0)
print(f"训练集大小: {len(train_set)}")
print(f"验证集大小: {len(val_set)}")
print(f"测试集大小: {len(test_set)}")
创建高级模型
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
model = AdvancedNet(num_classes=10, dropout_rate=0.5).to(device)
print("高级模型已创建,开始训练...")
训练模型
best_val_acc = train_advanced_model(
model, train_loader, val_loader, num_epochs=100
)
加载最佳模型
model.load_state_dict(torch.load('best_model.pkl', weights_only=True))
在测试集上评估(不使用TTA)
model.eval()
correct = 0
total = 0
with torch.no_grad():
for images, labels in test_loader:
images, labels = images.to(device), labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
test_accuracy = 100 * correct / total
print(f'标准测试集准确率: {test_accuracy:.2f}%')
使用测试时间增强(TTA)进行评估
tta_accuracy = test_time_augmentation(model, test_loader, device)
print(f'TTA测试集准确率: {tta_accuracy:.2f}%')
保存模型权重
os.makedirs(model_save_dir, exist_ok=True)
model_save_path = os.path.join(model_save_dir, 'advanced_model.pkl')
torch.save(model.state_dict(), model_save_path)
print(f'高级模型已保存到: {model_save_path}')
单张图像预测示例
test_img_path = 'D:/深度学习/手写汉字识别/data/test/00008/12313.png'
try:
img = Image.open(test_img_path).convert('RGB')
img_transform = transforms.Compose([
transforms.Resize((128, 128)),
transforms.Grayscale(num_output_channels=1),
transforms.ToTensor(),
transforms.Normalize(mean=[0.5], std=[0.5])
])
img_tensor = img_transform(img)
img_tensor = img_tensor.unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
output = model(img_tensor)
_, prediction = torch.max(output, 1)
prediction = prediction.cpu().numpy()[0]
print(f'单张图像预测结果: {prediction}')
except Exception as e:
print(f'预测时出错: {e}')
if name == 'main':
main()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号