
python网络爬虫——对股票数据并分析
Python网络爬虫课程设计
一:选题的背景
根据数据挖掘和数据量化分析方法,知道股票数据的跨度和周期,就可以知道应该选择什么股票了。因此,我们需要通过数据挖掘和数据量化分析的方法,找到其周期和规律,从而实现最大获益。分析股票规律、掌握股票投资可以促进中国社会经济发展,激发全民、全社会对股票的热情,提升中国股市规模与技术水平。
本次实验通过爬虫爬取东方财务网深圳A股的数据(该数据公开且允许爬虫获取),其网页中的数据如图所示。通过怕去到的股票数据通过后续的数据清洗与数据分析对深圳A股的评估去理解股票市场的一些规则和规律。
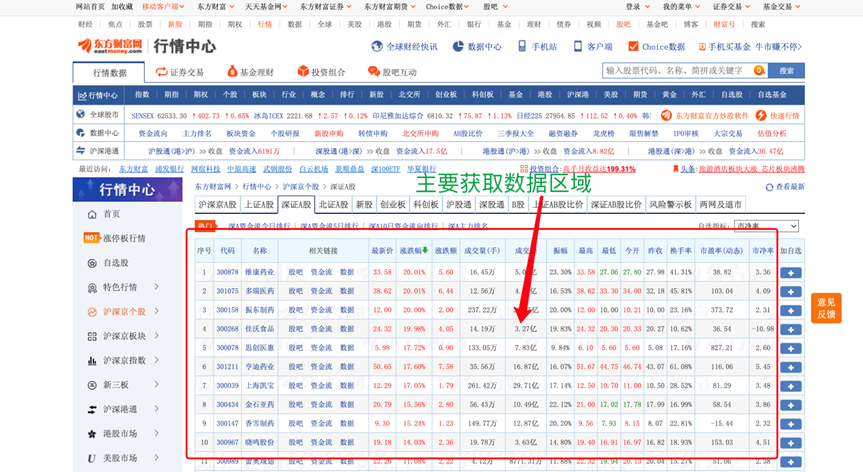
二:网络爬虫的设计方案
爬虫可分为:通用爬虫,主题爬虫,增量爬虫。其中通用网络爬虫所爬取的目标数据是巨大的,并且爬行的范围也是非常大的,正是由于其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是非常高的。主要应用于大型搜索引擎中,有非常高的应用价值,但是通用爬虫需要遵守robots协议。
主题爬虫(也叫聚焦爬虫):是面向特定需求的一种网络爬虫程序。聚焦爬虫拥有一个控制中心,负责对整个爬虫系统进行管理和监控,主要包括控制用户交互,初始化爬行器,确定主题,协调各模块之间的工作,爬行过程等。它是有选择的进行网页爬取,通用爬虫的目标是全网的资源,但是聚焦爬虫爬取的是一开始就选择好的主题内容,可以很好的节省了网络资源,由于保存的页面数量少所以更新速度很快,可以为某一类特殊人群提供服务,它主要是用于特定信息的爬取。本文就是实现对东方财富网中深圳A股总共244页的内容进行爬取。
增量式爬虫:它爬取的是网页上已经更新过的内容,没有更新或者是没有改变的内容就不爬取。通用的商业搜索引擎就是属于这类的。
总的来说。通用爬虫是搜索引擎的爬虫,是搜索引擎的重要组成部分,采用的是优先爬取有深度优先爬行策略;聚焦爬虫针对特定网站的爬虫,如本文就是实现对东方财富网中深圳A股总共244页的内容进行爬取;增量式爬虫,主要商用。
主题爬虫,又称聚焦爬虫,作为“面向特定主题”的一种网络爬虫程序。它的难点主要有以下两点:
(一)主题相关度计算:即计算当前已经抓下来的页面的主题相关程度。对主题相关度超过某一规定阈值的,即与主题相关的网页,将其保存到网页库;不相关的,则抛弃不管。
(二)主题相关度预测:主题相关度预测是针对待抓URL的。也就是我们在分析当前已下载网页时所分离出来的哪些URLS。我们要通过计算它们的主题预测值来决定接下来是否对该URL所对应的网页进行抓取。
在本文的实现中我们的技术方案总的来说就是实现对获取页面中的数据进行分析与解析,然后通过整个数据中选出自己需要的股票的代码,名称,最新价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收,量比,换手率,市盈率(动态),市净率这些参数,对最终爬取的数据做本地化保存与后续分析。
三:主题页面的结构特征分析
在本次实验中我们选择Chrome浏览器对页面进行分析,首先打开待爬取页面的地址(http://quote.eastmoney.com/center/gridlist.html?st=ChangePercent&sr=-1#sz_a_board)然后打开Chrome浏览器的检查功能如图所示:

对这些数据进行精细定位的结果如图所示:可以发现所有数据都被规律的存放在<tbody>节点中。
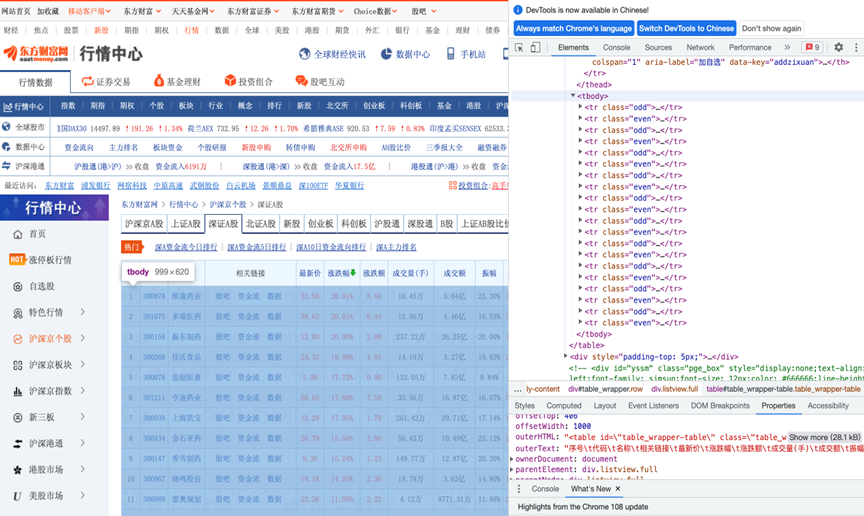
而在<tbody>节点中,股票的代码,名称,最新价,涨跌幅,涨跌额,成交量,成交额,振幅,最高,最低,今开,昨收,量比,换手率,市盈率(动态),市净率均被十分规范的存放在<td>节点中。

四:爬虫程序设计
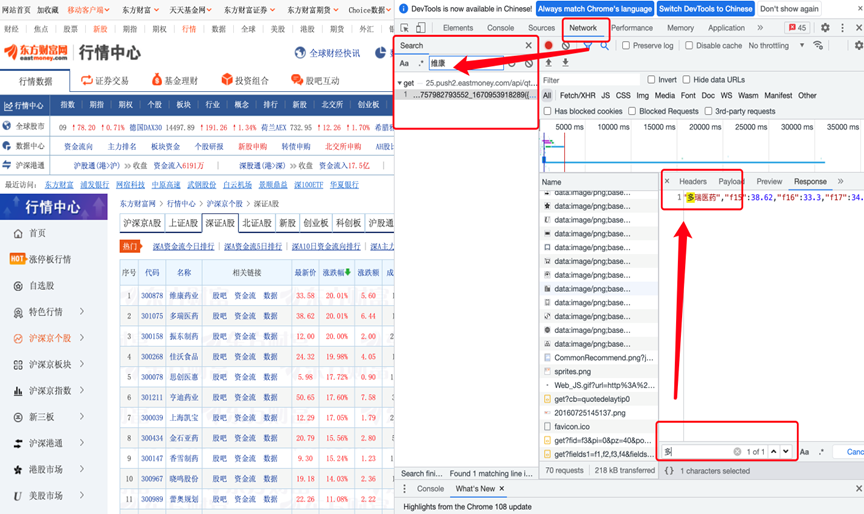
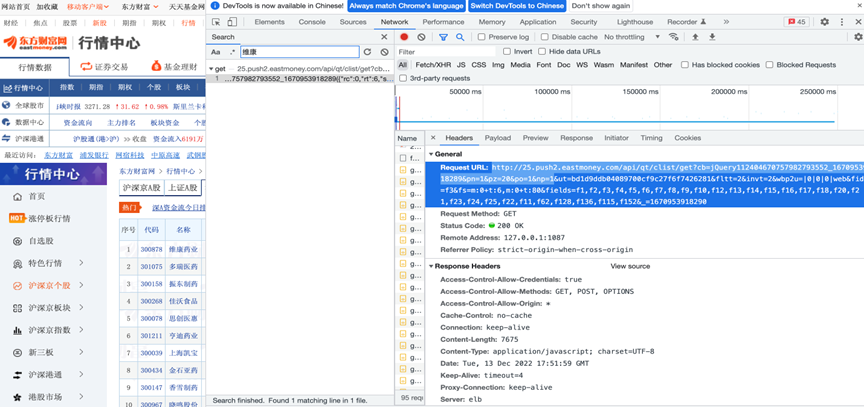
我们利用Network按下crtl+R,抓包同时搜索关键词得到的结果如图,最终定位到存储所有数据的数据位置。
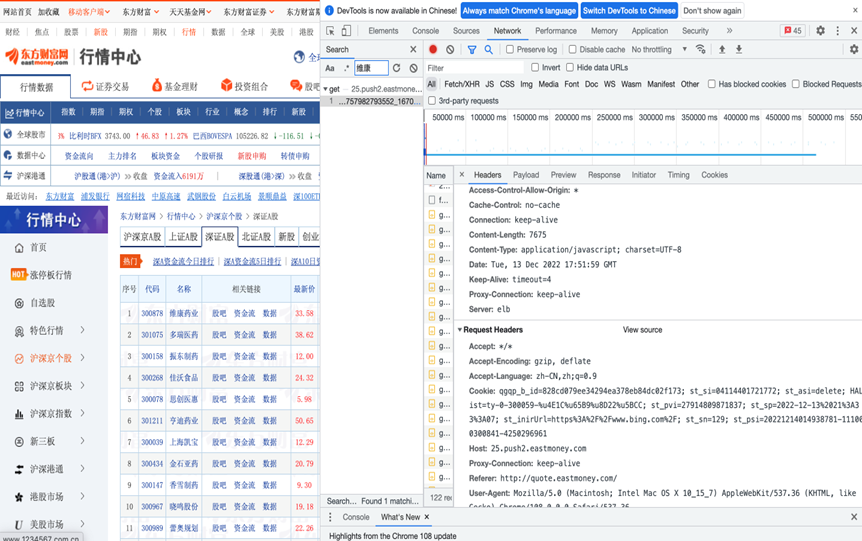
获取对应的Headers,Cookies如图所示:这些数据最终要放入程序中。
同时根据这个文件,我们得到了一行URL,其地址为http://25.push2.eastmoney.com/api/qt/clist/get?cb=jQuery112404670757982793552_1670953918289&pn=1&pz=20&po=1&np=1&ut=bd1d9ddb04089700cf9c27f6f7426281&fltt=2&invt=2&wbp2u=|0|0|0|web&fid=f3&fs=m:0+t:6,m:0+t:80&fields=f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152&_=1670953918290。
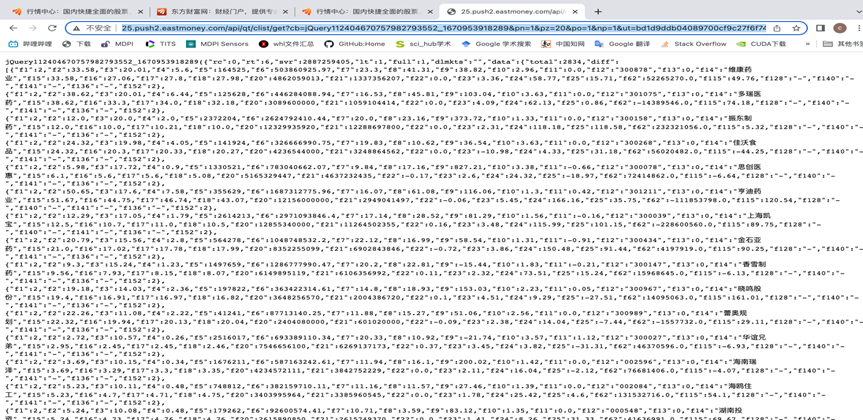
访问该URL最后得到的界面如图所示,可以发现数据均存放在该页面中,从而完成数据解析,准备利用爬虫对其进行爬取。
首先我们导入相关库:本实验主要用到requests、re、pandas、matplotlib四个库实现爬虫与数据分析。
# 导入requests库 import requests # 导入正则表达式所需要用到的库re import re # 导入数据分析所用到的库pandas import pandas as pd
配置cookie信息和头文件相关程序如下:
# 写入cookie信息
cookies = {
# 即为页面中分析时'qgqp_b_id'对应的值
'qgqp_b_id': '02d480cce140d4a420a0df6b307a945c',
# 即为页面中分析时'cowCookie'对应的值
'cowCookie': 'true',
# 即为页面中分析时'em_hq_fls'对应的值
'em_hq_fls': 'js',
# 即为页面中分析时'intellpositionL'对应的值
'intellpositionL': '1168.61px',
# 即为页面中分析时'HAList'对应的值
'HAList': 'a-sz-300059-%u4E1C%u65B9%u8D22%u5BCC%2Ca-sz-000001-%u5E73%u5B89%u94F6%u884C',
# 即为页面中分析时'st_si'对应的值
'st_si': '07441051579204',
# 即为页面中分析时'st_asi'对应的值
'st_asi': 'delete',
# 即为页面中分析时'st_pvi'对应的值
'st_pvi': '34234318767565',
# 即为页面中分析时'st_sp'对应的值
'st_sp': '2021-09-28%2010%3A43%3A13',
# 即为页面中分析时'st_inirUrls'对应的值
'st_inirUrl': 'http%3A%2F%2Fdata.eastmoney.com%2F',
# 即为页面中分析时'st_sn'对应的值
'st_sn': '31',
# 即为页面中分析时'st_psi'对应的值
'st_psi': '20211020210419860-113300300813-5631892871',
# 即为页面中分析时'intellpositionT'对应的值
'intellposit
# 对当前页数发送请求
response = requests.get('http://67.push2.eastmoney.com/api/qt/clist/get', headers=headers, params=params,
cookies=cookies, verify=False)
对该URL发送请求与获得的结果如下图所示,由于Pycharm无法显示全部信息,本文只截取的一部分,但仍然可以打印信息与发现即本文所解析页面的内容完全一致。
# 配置头文件
headers = {
# 即为页面中分析时'Connection'对应的值
'Connection': 'keep-alive',
# 即为页面中分析时'User-Agent'对应的值
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50',
# 即为页面中分析时'DNT'对应的值
'DNT': '1',
# 即为页面中分析时'Accept'对应的值
'Accept': '*/*',
# 即为页面中分析时'Referer'对应的值
'Referer': 'http://quote.eastmoney.com/',
# 即为页面中分析时'Accept-Language'对应的值
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
# 解析到的URL中对应的cb参数
('cb', 'jQuery1124031167968836399784_1615878909521'),
# 解析到的URL中对应的pn参数
('pn', str(page)),
# 解析到的URL中对应的pz参数
('pz', '20'),
# 解析到的URL中对应的po参数
('po', '1'),
# 解析到的URL中对应的np参数
('np', '1'),
# 解析到的URL中对应的ut参数
('ut', 'bd1d9ddb04089700cf9c27f6f7426281'),
# 解析到的URL中对应的fltt参数
('fltt', '2'),
# 解析到的URL中对应的invt参数
('invt', '2'),
# 解析到的URL中对应的fid参数
('fid', 'f3'),
# 解析到的URL中对应的fs参数
('fs', 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048'),
# 解析到的URL中对应的fields参数
('fields', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'),
通过正则表达式实现对其正确检测,并获取对应内容:
# 获取股票代码
daimas = re.findall('"f12":(.*?),', response.text)
# 获取股票名称
names = re.findall('"f14":"(.*?)"', response.text)
# 获取最新价
zuixinjias = re.findall('"f2":(.*?),', response.text)
# 获取涨跌幅
zhangdiefus = re.findall('"f3":(.*?),', response.text)
# 获取涨跌额
zhangdiees = re.findall('"f4":(.*?),', response.text)
# 获取成交量
chengjiaoliangs = re.findall('"f5":(.*?),', response.text)
# 获取成交额
chengjiaoes = re.findall('"f6":(.*?),', response.text)
# 获取振幅
zhenfus = re.findall('"f7":(.*?),', response.text)
# 获取今日最高点
zuigaos = re.findall('"f15":(.*?),', response.text)
# 获取今日最低点
zuidis = re.findall('"f16":(.*?),', response.text)
# 获取今日开盘价格
jinkais = re.findall('"f17":(.*?),', response.text)
# 获取昨日收盘价格
zuoshous = re.findall('"f18":(.*?),', response.text)
# 获取量比
liangbis = re.findall('"f10":(.*?),', response.text)
# 获取换手率
huanshoulvs = re.findall('"f8":(.*?),', response.text)
# 获取市盈率
shiyinglvs = re.findall('"f9":(.*?),', response.text)
# 获取市净率
shijinglvs = re.findall('"f23":(.*?),', response.text)
将所有数据写入字典,为后续本地化存储,最终打印出字典中的信息如图所示:
# 将不同股票信息写入字典
for i in range(len(daimas)):
dict = {
# 获取对应股票代码
"代码": daimas[i],
# 获取对应股票名称
"名称": names[i],
# 获取对应股票最新价
"最新价":zuixinjias[i],
# 获取对应股票涨跌幅
"涨跌幅":zhangdiefus[i],
# 获取对应股票涨跌额
"涨跌额":zhangdiees[i],
# 获取对应股票成交量
"成交量":chengjiaoliangs[i],
# 获取对应股票成交额
"成交额":chengjiaoes[i],
# # 获取对应股票振幅
"振幅":zhenfus[i],
# 获取对应股票最高点
"最高":zuigaos[i],
# 获取对应股票最低点
"最低":zuidis[i],
# 获取对应股票开盘价格
"今开":jinkais[i],
# 获取对应股票昨日收盘价格
"昨收":zuoshous[i],
# 获取对应股票量比
"量比":liangbis[i],
# 获取对应股票最换手率
"换手率":huanshoulvs[i],
# 获取对应股票市盈率(动态)
"市盈率(动态)":shiyinglvs[i],
# 获取对应股票市净率
"市净率":shijinglvs[i]
}
# 打印字典信息
# print(dict)
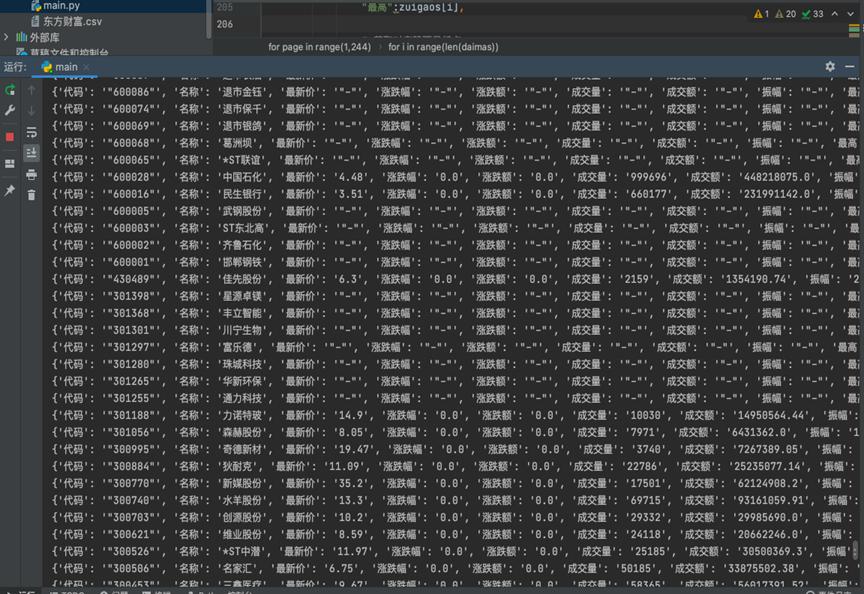
最后利用pandas将所有的数据做本地化保存结果如图所示:
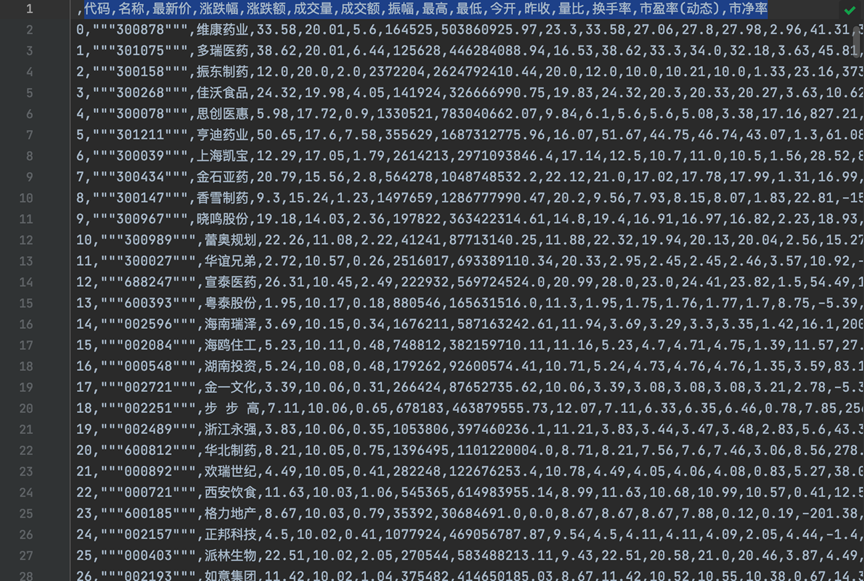
股票行业中最有用的值通常是股票的最新价和涨跌幅,为此,我们在数据清洗和处理的过程中选择涨幅最高的100支股票进行后续的分析。
对于涨幅最高的100支股票,我们按顺序做出了其最新价的折线变化,发现涨幅越高的股票价格越高。


最终利用numpy采用多项式曲线拟合拟合出来的换手率和涨幅的关系,从趋势可以看出,随着涨幅升高,换手率略微下降。

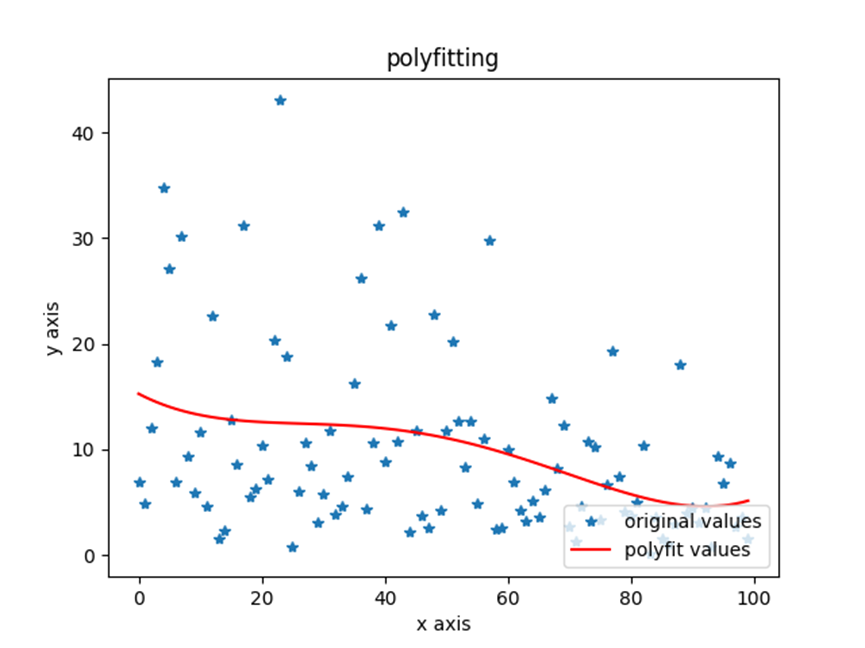
五:总结
通过本次图标的可视化结果我明白了在股票行业中随着涨幅升高,换手率略微下降同时涨幅越高的股票价格越高,该结论是合理且符合市场客观规律的,通过本次试验最终完成了既定目标,收获满满,同时也发现了自己的一些不足,后续会更加努力的学习编程和数据分析。
源码附上:
# 导入requests库
import requests
# 导入正则表达式所需要用到的库re
import re
# 导入数据分析所用到的库pandas
import pandas as pd
# 导入matplotlib
import matplotlib.pyplot as plt
# 利用time实现暂停打印信息
import time
# numpy
import numpy as np
# 写入cookie信息
cookies = {
# 即为页面中分析时'qgqp_b_id'对应的值
'qgqp_b_id': '02d480cce140d4a420a0df6b307a945c',
# 即为页面中分析时'cowCookie'对应的值
'cowCookie': 'true',
# 即为页面中分析时'em_hq_fls'对应的值
'em_hq_fls': 'js',
# 即为页面中分析时'intellpositionL'对应的值
'intellpositionL': '1168.61px',
# 即为页面中分析时'HAList'对应的值
'HAList': 'a-sz-300059-%u4E1C%u65B9%u8D22%u5BCC%2Ca-sz-000001-%u5E73%u5B89%u94F6%u884C',
# 即为页面中分析时'st_si'对应的值
'st_si': '07441051579204',
# 即为页面中分析时'st_asi'对应的值
'st_asi': 'delete',
# 即为页面中分析时'st_pvi'对应的值
'st_pvi': '34234318767565',
# 即为页面中分析时'st_sp'对应的值
'st_sp': '2021-09-28%2010%3A43%3A13',
# 即为页面中分析时'st_inirUrls'对应的值
'st_inirUrl': 'http%3A%2F%2Fdata.eastmoney.com%2F',
# 即为页面中分析时'st_sn'对应的值
'st_sn': '31',
# 即为页面中分析时'st_psi'对应的值
'st_psi': '20211020210419860-113300300813-5631892871',
# 即为页面中分析时'intellpositionT'对应的值
'intellpositionT': '1007.88px',
}
# 配置头文件
headers = {
# 即为页面中分析时'Connection'对应的值
'Connection': 'keep-alive',
# 即为页面中分析时'User-Agent'对应的值
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36 Edg/94.0.992.50',
# 即为页面中分析时'DNT'对应的值
'DNT': '1',
# 即为页面中分析时'Accept'对应的值
'Accept': '*/*',
# 即为页面中分析时'Referer'对应的值
'Referer': 'http://quote.eastmoney.com/',
# 即为页面中分析时'Accept-Language'对应的值
'Accept-Language': 'zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6',
}
# 所有信息等待存入放入列表
all_message = []
# 总共爬取网页上244页的内容
for page in range(1,244):
params = (
# 解析到的URL中对应的cb参数
('cb', 'jQuery1124031167968836399784_1615878909521'),
# 解析到的URL中对应的pn参数
('pn', str(page)),
# 解析到的URL中对应的pz参数
('pz', '20'),
# 解析到的URL中对应的po参数
('po', '1'),
# 解析到的URL中对应的np参数
('np', '1'),
# 解析到的URL中对应的ut参数
('ut', 'bd1d9ddb04089700cf9c27f6f7426281'),
# 解析到的URL中对应的fltt参数
('fltt', '2'),
# 解析到的URL中对应的invt参数
('invt', '2'),
# 解析到的URL中对应的fid参数
('fid', 'f3'),
# 解析到的URL中对应的fs参数
('fs', 'm:0 t:6,m:0 t:80,m:1 t:2,m:1 t:23,m:0 t:81 s:2048'),
# 解析到的URL中对应的fields参数
('fields', 'f1,f2,f3,f4,f5,f6,f7,f8,f9,f10,f12,f13,f14,f15,f16,f17,f18,f20,f21,f23,f24,f25,f22,f11,f62,f128,f136,f115,f152'),
)
# 对当前页数发送请求
response = requests.get('http://67.push2.eastmoney.com/api/qt/clist/get', headers=headers, params=params,
cookies=cookies, verify=False)
# 打印请求结果
# print(response.text)
# time.sleep(100)
# 获取股票代码
daimas = re.findall('"f12":(.*?),', response.text)
# 获取股票名称
names = re.findall('"f14":"(.*?)"', response.text)
# 获取最新价
zuixinjias = re.findall('"f2":(.*?),', response.text)
# 获取涨跌幅
zhangdiefus = re.findall('"f3":(.*?),', response.text)
# 获取涨跌额
zhangdiees = re.findall('"f4":(.*?),', response.text)
# 获取成交量
chengjiaoliangs = re.findall('"f5":(.*?),', response.text)
# 获取成交额
chengjiaoes = re.findall('"f6":(.*?),', response.text)
# 获取振幅
zhenfus = re.findall('"f7":(.*?),', response.text)
# 获取今日最高点
zuigaos = re.findall('"f15":(.*?),', response.text)
# 获取今日最低点
zuidis = re.findall('"f16":(.*?),', response.text)
# 获取今日开盘价格
jinkais = re.findall('"f17":(.*?),', response.text)
# 获取昨日收盘价格
zuoshous = re.findall('"f18":(.*?),', response.text)
# 获取量比
liangbis = re.findall('"f10":(.*?),', response.text)
# 获取换手率
huanshoulvs = re.findall('"f8":(.*?),', response.text)
# 获取市盈率
shiyinglvs = re.findall('"f9":(.*?),', response.text)
# 获取市净率
shijinglvs = re.findall('"f23":(.*?),', response.text)
# 将不同股票信息写入字典
for i in range(len(daimas)):
dict = {
# 获取对应股票代码
"代码": daimas[i],
# 获取对应股票名称
"名称": names[i],
# 获取对应股票最新价
"最新价":zuixinjias[i],
# 获取对应股票涨跌幅
"涨跌幅":zhangdiefus[i],
# 获取对应股票涨跌额
"涨跌额":zhangdiees[i],
# 获取对应股票成交量
"成交量":chengjiaoliangs[i],
# 获取对应股票成交额
"成交额":chengjiaoes[i],
# # 获取对应股票振幅
"振幅":zhenfus[i],
# 获取对应股票最高点
"最高":zuigaos[i],
# 获取对应股票最低点
"最低":zuidis[i],
# 获取对应股票开盘价格
"今开":jinkais[i],
# 获取对应股票昨日收盘价格
"昨收":zuoshous[i],
# 获取对应股票量比
"量比":liangbis[i],
# 获取对应股票最换手率
"换手率":huanshoulvs[i],
# 获取对应股票市盈率(动态)
"市盈率(动态)":shiyinglvs[i],
# 获取对应股票市净率
"市净率":shijinglvs[i]
}
# 打印字典信息
# print(dict)
# 把一支股票的所有信息以字典的形式存入列表
all_message.append(dict)
# 打印所有股票构成的列表
# print(all_message)
# 将其存储为pandas格式
result_pd = pd.DataFrame(all_message)
# 做本地化保存
result_pd.to_csv("东方财富.csv")
# 数据清洗和处理时我们选择涨幅最高的100支股票进行后续分析
# 读取本地CSV
df = pd.read_csv("东方财富_photo.csv")
# 根据涨幅进行排序
df_sort = df.sort_values(by='涨跌幅', ascending=False)
# # 打印排序结果
# print(df_sort)
#
# # 打印排序后原始数据长度
# print(len(df_sort))
# 对排序后的数据取前100行
new_df = df_sort.head(100)
# # 打印原始数据清洗与筛选后的
# print(df_sort)
#
# # 打印筛选后的长度
# print(len(new_df))
# 画图
# 主要利用matplotlib和pandas自带的画图功能
# 绘制涨幅最高的100支股票最新价折线图
pd_cje = new_df['最新价'].tolist()
# 打印结果
# print(pd_cje)
# 打印是否转换成列表
# print(type(pd_cje))
# 设置x刻度
my_x_ticks = np.arange(0, 101, 5)
# 设置y刻度
my_y_ticks = np.arange(0, 101, 5)
# 配置x刻度
plt.xticks(my_x_ticks)
# 配置y刻度
plt.yticks(my_y_ticks)
# 画图
plt.plot(range(len(pd_cje)), pd_cje)
# 展示
plt.show()
# 绘制散点图并拟合
my_y = new_df['换手率'].tolist()
my_x = [i for i in range(len(my_y))]
# 用4次多项式拟合
z1 = np.polyfit(my_x, my_y, 4)
p1 = np.poly1d(z1)
# 也可以使用yvals=np.polyval(z1,x)
yvals=p1(my_x)
# 绘制散点和曲线
plot1=plt.plot(my_x, my_y, '*',label='original values')
plot2=plt.plot(my_x, yvals, 'r',label='polyfit values')
# 图标
plt.xlabel('x axis')
plt.ylabel('y axis')
# 标题
plt.title('polyfitting')
# 展示
plt.show()

 浙公网安备 33010602011771号
浙公网安备 33010602011771号