

102302105汪晓红数据采集作业2
第二次作业
作业①:
作业代码和图片:
核心代码:
点击查看代码
# 主程序
url = "http://www.weather.com.cn/weather/101010100.shtml"
city = "北京"
# 初始化数据库
conn = setup_database()
try:
headers = {"User-Agent": "Mozilla/5.0 (Windows; U; Windows NT 6.0 x64; en-US; rv:1.9pre) Gecko/2008072421 Minefield/3.0.2pre"}
req = urllib.request.Request(url, headers=headers)
data = urllib.request.urlopen(req)
data = data.read()
dammit = UnicodeDammit(data, ["utf-8", "gbk"])
data = dammit.unicode_markup
soup = BeautifulSoup(data, "lxml")
lis = soup.select("ul[class='t clearfix'] li")
print(f"正在获取{city}的天气预报并保存到数据库...")
for li in lis:
try:
date = li.select('h1')[0].text
weather = li.select('p[class="wea"]')[0].text
temp = li.select('p[class="tem"] span')[0].text + "/" + li.select('p[class="tem"] i')[0].text
# 打印到控制台
print(date, weather, temp)
# 保存到数据库
save_weather_to_db(conn, city, date, weather, temp)
except Exception as err:
print(f"解析错误: {err}")
# 显示已保存的数据
display_saved_data(conn)
print(f"\n数据库文件: weather_data.db")
结果图片:

Gitee文件夹链接:https://gitee.com/xiaofennnn/2025-data-collection?source=header_my_projects
作业心得:
在保存到数据库的地方出了点问题,把报错给ai,找到了解决方法
作业②:
作业代码和图片:
核心代码:
点击查看代码
class StockFetcher:
"""股票数据获取与处理类"""
def __init__(self):
self.base_url = "https://push2.eastmoney.com/api/qt/clist/get"
self.params = {
"np": "1",
"fltt": "1",
"invt": "2",
"cb": "jQuery37103071409561710594_1762478212220",
"fs": "m:0+t:6+f:!2,m:0+t:80+f:!2,m:1+t:2+f:!2,m:1+t:23+f:!2,m:0+t:81+s:262144+f:!2",
"fields": "f12,f13,f14,f1,f2,f4,f3,f152,f5,f6,f7,f15,f18,f16,f17,f10,f8,f9,f23",
"fid": "f3",
"pn": "1",
"pz": "20",
"po": "1",
"dect": "1",
"ut": "fa5fd1943c7b386f172d6893dbfba10b",
"wbp2u": "|0|0|0|web",
"_": "1762478212229"
}
self.headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/114.0.0.0 Safari/537.36"
}
self.db_path = "stock.db"
self.table_name = "stocks"
def _parse_jsonp(self, jsonp_str: str) -> Optional[Dict[str, Any]]:
"""解析JSONP格式响应为JSON对象"""
try:
# 提取JSON部分
json_start = jsonp_str.find('(') + 1
json_end = jsonp_str.rfind(')')
json_str = jsonp_str[json_start:json_end]
return json.loads(json_str)
except (ValueError, IndexError) as e:
print(f"解析JSONP失败: {e}")
return None
def fetch_data(self) -> Optional[List[StockInfo]]:
"""从API获取并解析股票数据"""
try:
print("正在获取股票数据...")
response = requests.get(
self.base_url,
params=self.params,
headers=self.headers,
timeout=10
)
response.raise_for_status() # 检查HTTP错误状态
# 解析JSONP响应
json_data = self._parse_jsonp(response.text)
if not json_data or "data" not in json_data or "diff" not in json_data["data"]:
print("获取的数据格式不正确")
return None
# 转换为StockInfo对象列表
stocks = []
for idx, item in enumerate(json_data["data"]["diff"], 1):
# 数据验证
required_fields = ["f12", "f14", "f2", "f3", "f4", "f5", "f6", "f7"]
if not all(field in item for field in required_fields):
print(f"跳过不完整的股票数据: {item}")
continue
# 创建股票信息对象
stock = StockInfo(
rank=idx,
code=str(item["f12"]),
name=str(item["f14"]),
price=float(item["f2"]) / 100,
change_percent=f"{float(item['f3']) / 100:.2f}%",
change_amount=float(item["f4"]) / 100,
volume=f"{round(float(item['f5']) / 10000, 2):.2f}万",
turnover=f"{round(float(item['f6']) / 100000000, 2):.2f}亿",
other=f"{float(item['f7']) / 100:.2f}%"
)
stocks.append(stock)
# 限制最多20条数据
if len(stocks) >= 20:
break
return stocks
except requests.exceptions.RequestException as e:
print(f"网络请求错误: {e}")
return None
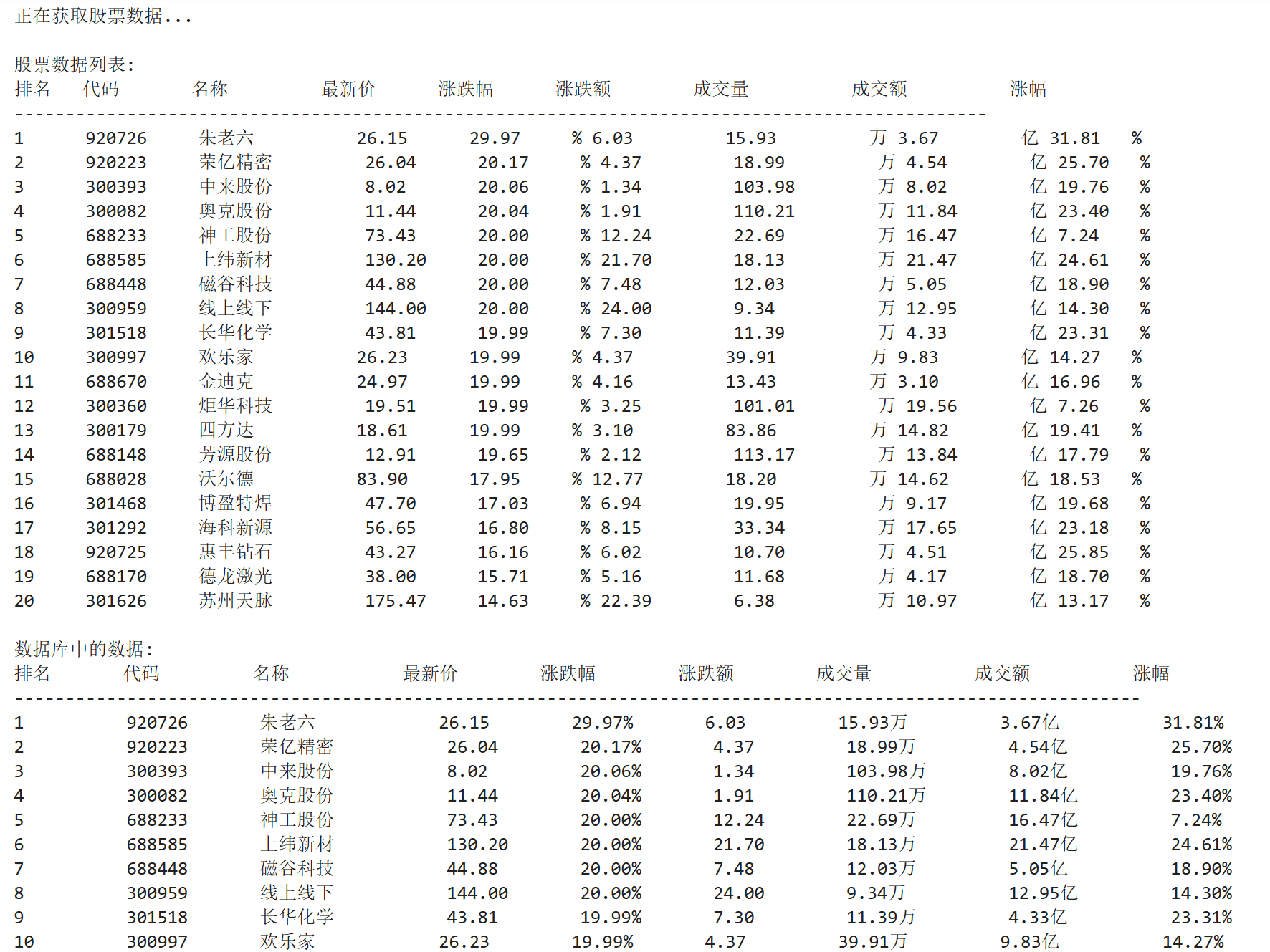
Gitee文件夹链接:https://gitee.com/xiaofennnn/2025-data-collection?source=header_my_projects
作业心得:
这个任务在抓包的时候出现了很多问题,找了很久才找到正确的,所以要一层层看,有耐心一点
作业③:
抓包过程:
核心代码:
点击查看代码
def fetch_ranking_data(self):
"""爬取并处理大学排名数据"""
try:
response = requests.get(self.url, headers=self.headers)
response.raise_for_status()
response.encoding = response.apparent_encoding
# 编译正则表达式模式
pattern = re.compile(
r'univNameCn:"(?P<university_name>[^"]+)",'
r'.*?'
r'univCategory:(?P<category_code>[^,]+),'
r'.*?'
r'province:(?P<province_code>[^,]+),'
r'.*?'
r'score:(?P<score>[^,]+),',
re.S
)
universities_data = []
for match in pattern.finditer(response.text):
university_data = self._parse_university_data(match)
if university_data:
universities_data.append(university_data)
# 按总分降序排序
universities_data.sort(key=lambda x: x[3], reverse=True)
return universities_data
except requests.RequestException as error:
print(f"数据获取失败: {error}")
return []
def _parse_university_data(self, regex_match):
"""解析单条大学数据"""
try:
university_name = regex_match.group('university_name').strip().strip('"')
category_code = regex_match.group('category_code').strip().strip('"')
province_code = regex_match.group('province_code').strip().strip('"')
score_string = regex_match.group('score').strip().strip('"')
# 验证并转换数据
if not university_name or not self._is_valid_score(score_string):
return None
province = self.PROVINCE_MAPPING.get(province_code, '其他')
category = self.UNIVERSITY_CATEGORY_MAPPING.get(category_code, '其他')
total_score = float(score_string)
return (university_name, province, category, total_score)
except (AttributeError, ValueError) as error:
print(f"数据解析错误: {error}")
return None
def _is_valid_score(self, score_str):
"""验证分数字符串是否有效"""
return score_str.replace('.', '').isdigit()
def save_to_database(self, universities_data):
"""将大学排名数据保存到数据库"""
if not universities_data:
print("没有数据需要保存")
return
try:
with sqlite3.connect(self.database_name) as connection:
cursor = connection.cursor()
crawl_timestamp = datetime.now().strftime('%Y-%m-%d %H:%M:%S')
# 准备插入数据
data_to_insert = []
for rank, university_info in enumerate(universities_data, start=1):
name, province, category, score = university_info
data_to_insert.append((
rank, name, province, category, score, crawl_timestamp
))
# 执行批量插入
insert_query = '''
INSERT INTO {}
(ranking, university_name, province, category, total_score, crawl_time)
VALUES (?, ?, ?, ?, ?, ?)
'''.format(self.table_name)
cursor.executemany(insert_query, data_to_insert)
print(f"成功保存 {len(data_to_insert)} 条大学排名数据")
except sqlite3.Error as error:
print(f"数据保存失败: {error}")
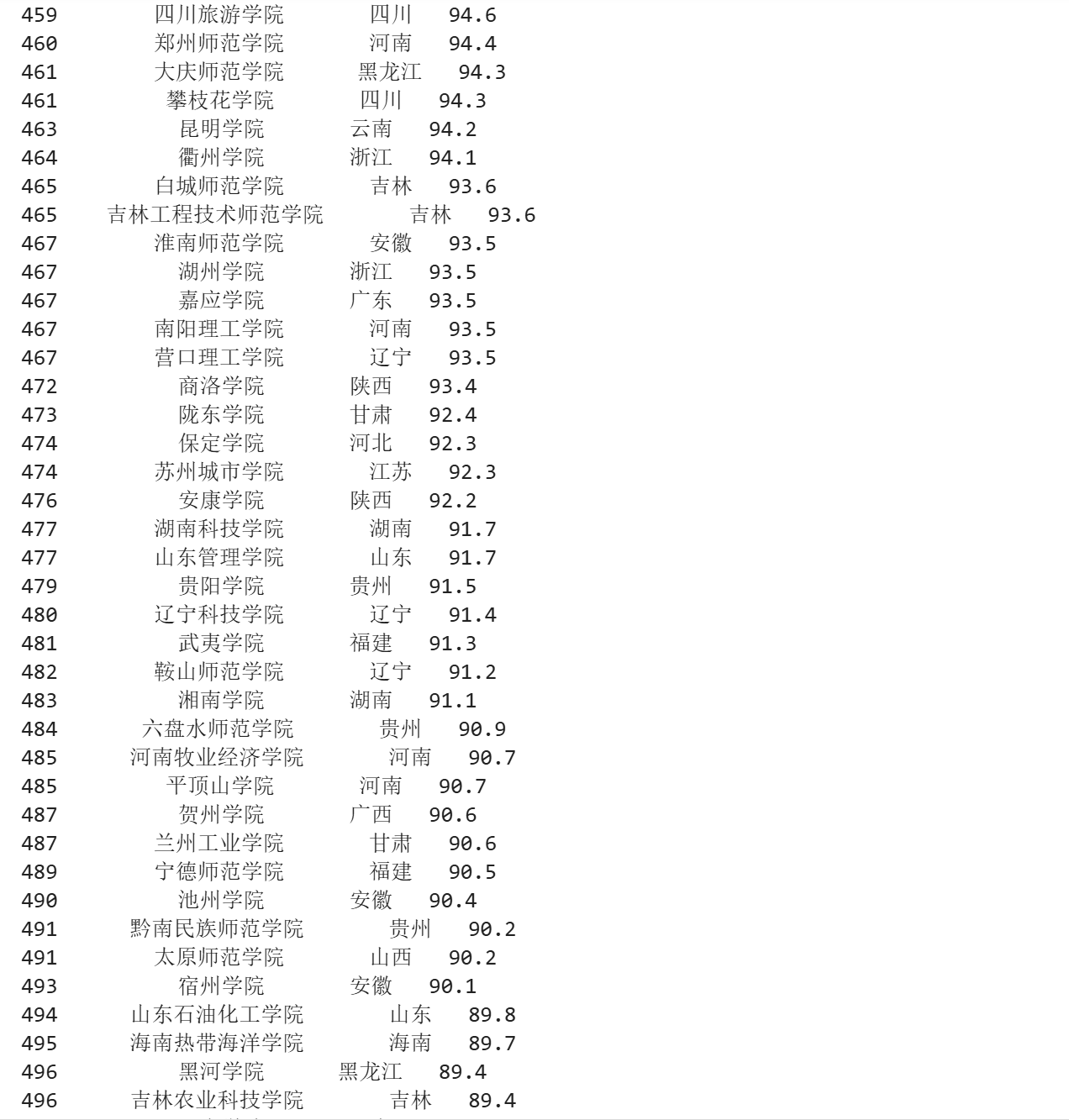
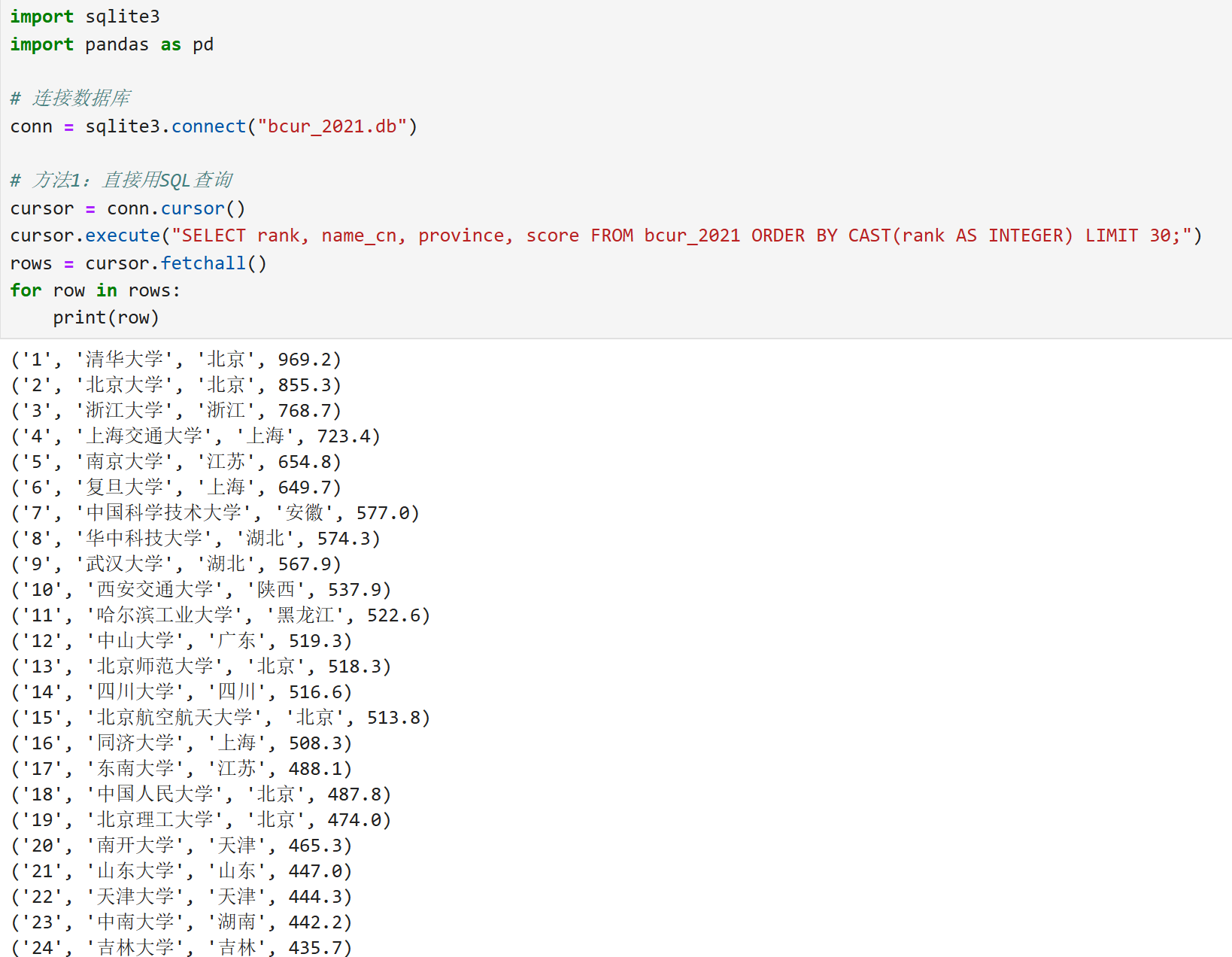
Gitee文件夹链接:https://gitee.com/xiaofennnn/2025-data-collection?source=header_my_projects
作业心得:
这次抓包过程明显轻松了很多,而且解析json也更加得心应手了

 浙公网安备 33010602011771号
浙公网安备 33010602011771号