
102302105汪晓红作业1
作业1
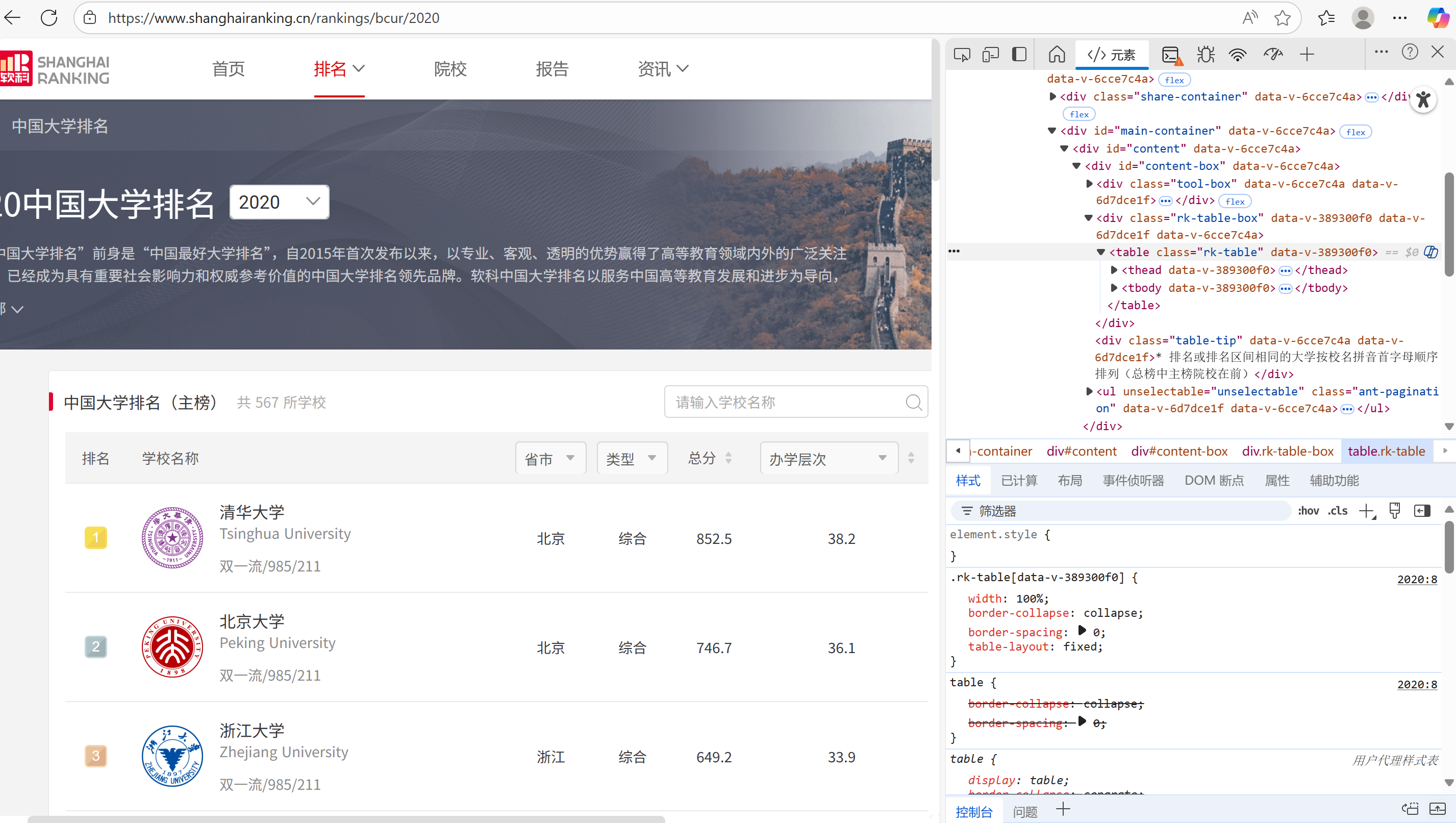
作业①:用requests和BeautifulSoup库方法定向爬取给定网址 http://www.shanghairanking.cn/rankings/bcur/2020 的数据,屏幕打印爬取的大学排名信息。
代码与结果
核心代码:
点击查看代码
#设置headers,模拟浏览器访问,防止被反爬
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
#设置真实网址,爬取指定页面
url = "https://www.shanghairanking.cn/rankings/bcur/2020"
try:
response = requests.get(url, headers=headers)
response.raise_for_status()
#将编码设置为utf-8防止乱码
response.encoding = 'utf-8'
#用bs4解析网页的HTML文件
soup = BeautifulSoup(response.text, 'html.parser')
#检查可知,大学排名数据保存在rk-table表格中,搜索该表格
table = soup.find('table', class_='rk-table')
print("2020年中国大学排名")
#设置打印表格的结构
print("=" * 50)
print(f"{'排名':<4} {'学校名称':<15} {'省份':<6} {'类型':<4} {'总分':<6}")
print("-" * 50)
#处理表格数据
rows = table.find('tbody').find_all('tr')
for row in rows:
cells = row.find_all('td')
# 提取前5列数据
ranking = cells[0].get_text(strip=True)
# 提取学校名称
name_cn = cells[1].find('span', class_='name-cn')
university_name = name_cn.get_text(strip=True) if name_cn else cells[1].get_text(strip=True)
# 提取省市、类型和总分数据
province = cells[2].get_text(strip=True)
uni_type = cells[3].get_text(strip=True)
total_score = cells[4].get_text(strip=True)
print(f"{ranking:>2} {university_name:<15} {province:<6} {uni_type:<4} {total_score:>6}")
输出结果:

作业心得:
打开该网站后,检查页面,筛选html文件,可以找到排名数据保存在rk-table表格中,解析该表格后打印出来即可
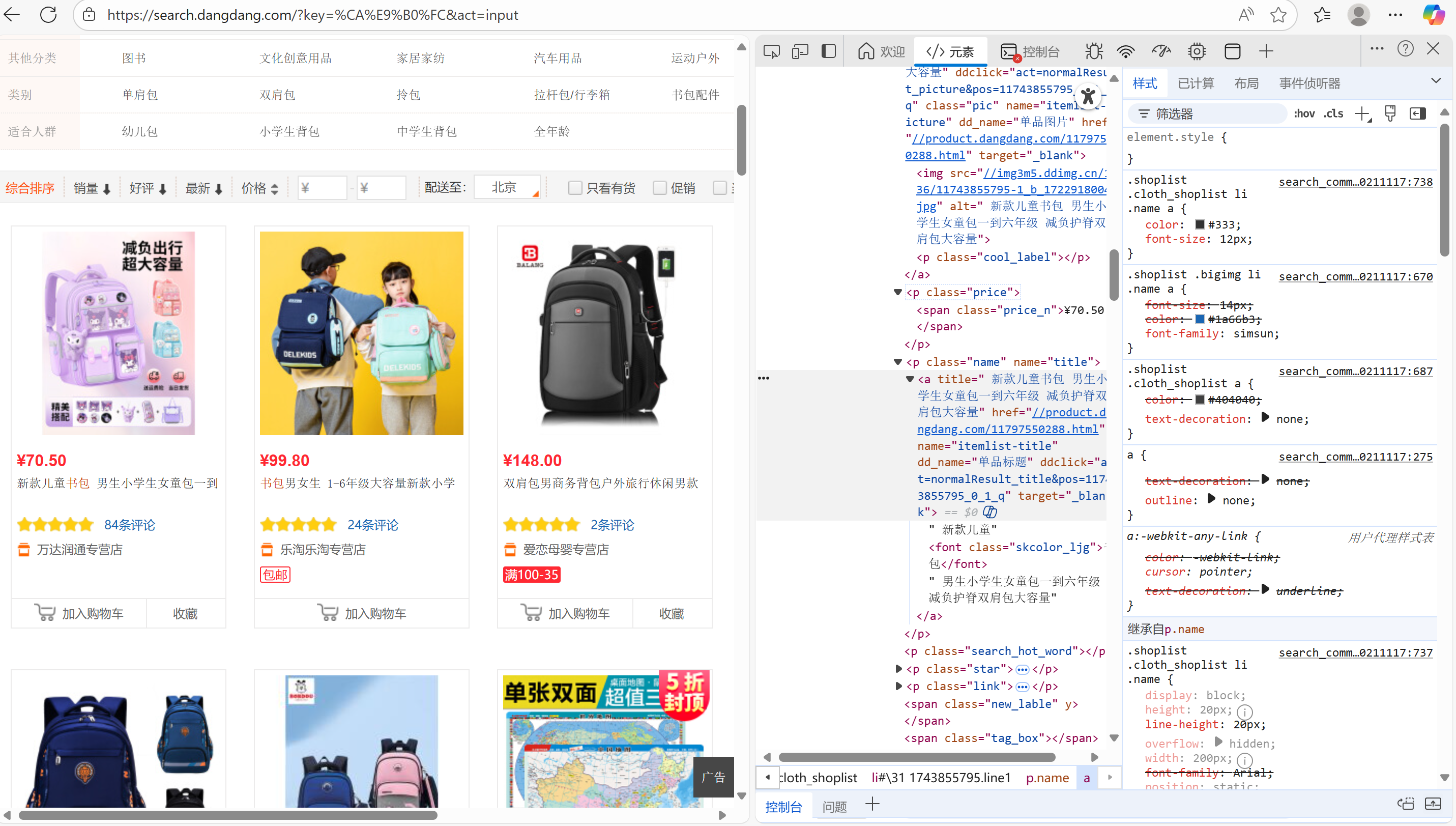
作业②:用requests和re库方法设计当当网“书包”商品比价
代码与结果
核心代码:
点击查看代码
try:
#爬取当当网的书包商品信息
url = "https://search.dangdang.com"
# 获取页面,书包的第一页
params = {'key': '书包', 'page': 1, 'pagesize': 10}
response = requests.get(url, params=params, headers=headers, timeout=10)
response.encoding = 'gb2312' #utf-8不可用,用gb2312
html = response.text
# 使用正则表达式提取商品信息
all_pattern = re.compile(r'<span class="price_n">¥(\d+(?:\.\d+)?)</span>.+?<a title="(.+?)"', re.S)
result = list(all_pattern.finditer(html))
# 显示结果
print("\n序号| 价格 | 商品名")
print("-" * 80)
products = []
for i, r in enumerate(result, 1):
price, title = r.groups()
title = title.strip()
print(f" {i} | {price} | \"{title}\"")
products.append([title, price])
输出结果:

作业心得:
爬取当当网的商品信息,跳转到书包商品页面,检查,找到html文件中的价格和商品名称段,解析,使用正则表达式筛选,然后将商品名称和价格对应保存下来
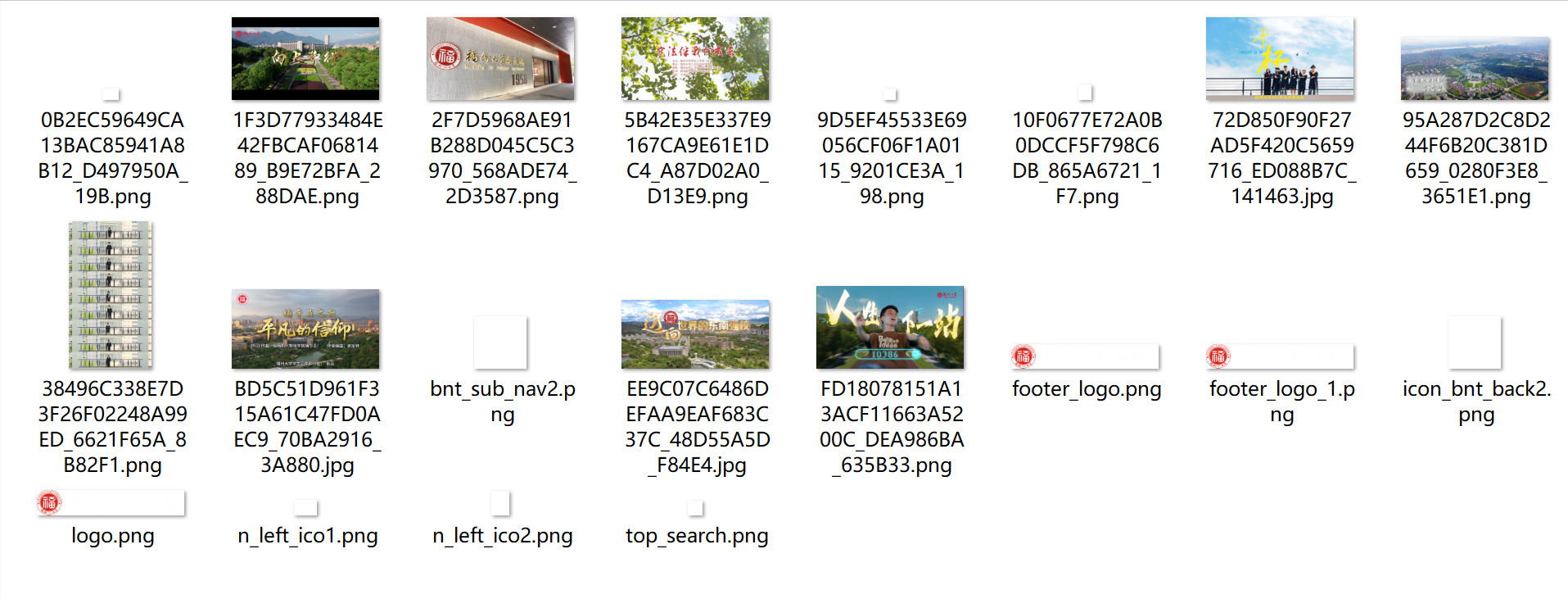
作业③:爬取一个给定网页 https://news.fzu.edu.cn/yxfd.htm 的所有JPEG、JPG或PNG格式图片文件
代码与结果:
核心代码:
点击查看代码
# 步骤1: 设置请求头
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36'
}
# 创建保存文件夹
if not os.path.exists(folder):
os.makedirs(folder)
try:
# 步骤2: 使用BeautifulSoup获取HTML
response = requests.get(url, headers=headers)
response.raise_for_status()
soup = BeautifulSoup(response.text, 'html.parser')
html_content = str(soup)
# 步骤3: 使用正则表达式查找图片
img_urls = re.findall(r'<img[^>]+src="([^"]+\.(?:jpg|jpeg|png))"', html_content, re.I)
print(f"找到 {len(img_urls)} 个图片链接")
# 步骤4: 下载并保存
count = 0
for img_src in img_urls:
# 拼接完整URL
img_url = urljoin(url, img_src)
try:
# 下载图片
img_response = requests.get(img_url, headers=headers)
img_response.raise_for_status()
# 生成文件名
filename = os.path.basename(img_src)
if not filename:
filename = f"image_{count+1}.jpg"
filepath = os.path.join(folder, filename)
# 保存图片
with open(filepath, 'wb') as f:
f.write(img_response.content)
print(f"下载: {filename}")
count += 1
except Exception as e:
print(f"下载失败: {img_url}")
print(f"\n共下载 {count} 张图片到 '{folder}' 文件夹")
except Exception as e:
print(f"错误: {e}")
输出结果:
作业心得:
打开该网站后,检查页面,筛选html文件,可以找到第一个图片路径保存在img src中:

通过这个格式可以直接将图片筛选出来,同时用正则表达式筛选我们需要的图片格式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号