
前言
本篇主要简单介绍 noSql 概念、mongodb 的基础知识、docker-compose 方式搭建部署以及 springboot2.x 整合 mongodb 进行基础 CRUD。
一、NoSQL 简介
NoSQL,指的是非关系型的数据库。NoSQL 有时也称作 Not Only SQL 的缩写,是对不同于传统的关系型数据库的数据库管理系统的统称。
NoSQL 用于超大规模数据的存储。(例如谷歌或 Facebook 每天为他们的用户收集万亿比特的数据)。这些类型的数据存储不需要固定的模式,无需多余操作就可以横向扩展。
二、NoSQL VS RDBMS
|
RDBMS |
NoSQL |
|
- 高度组织化结构化数据 - 结构化查询语言(SQL) - 数据和关系都存储在单独的表中。 - 数据操纵语言,数据定义语言 - 严格的一致性 - 基础事务 |
- 代表着不仅仅是 SQL - 没有声明性查询语言 - 没有预定义的模式 - 键 - 值对存储,列存储,文档存储,图形数据库 - 最终一致性,而非 ACID 属性 - 非结构化和不可预知的数据 - CAP 定理 - 高性能,高可用性和可伸缩性 |
三、CAP 定理(CAP theorem)
在计算机科学中, CAP 定理(CAP theorem), 又被称作 布鲁尔定理
(Brewer's theorem), 它指出对于一个分布式计算系统来说,不可能同时满足以下三点:
· 一致性(Consistency) (数据一致更新,所有数据变动都是同步的)
· 可用性(Availability) (保证每个请求不管成功或者失败都有响应,也就是好的响应性能)
· 分隔容忍(Partition tolerance) (系统中任意信息的丢失或失败不会影响系统的继续运作,可理解成高可用,一个节点崩了,并不影响我们其它
的节点)
CAP 理论的核心是:一个分布式系统不可能同时很好的满足一致性,可用性和分区容错性这三个需求,最多只能同时较好的满足两个。
因此,根据 CAP 原理将 NoSQL 数据库分成了满足 CA 原则、满足 CP 原则和满足 AP 原则三大类:
· CA - 单点集群,满足一致性,可用性的系统,通常在可扩展性上不太强大。
· CP - 满足一致性,分区容错性的系统,通常性能不是特别高。
· AP - 满足可用性,分区容错性的系统,通常可能对一致性要求低一些。
这里给你们分析一下,为什么 CAP 定理只能满足两个: 首先,看看它们分别的场景啊
1、满足 C,所有的机器上的数据都是一样,场景如下 : 每当一个新数据新增到其中一个服务器上,这个数据要同步到其它服务器,这样的情况下才可以保证 C
2、满足 A,场景如下: 用户随时都在访问,都能在可控的时间内返回正确的数据
3、满足 P,场景如下: 那必须是机器越多越可靠,为啥?我有 1 亿台服务器, 挂了几万台,完全没影响嘛。
然后,了解清楚了,现在分析一下为啥只能满足其中两个满足 C 和 A,那么 P 为啥不能满足
满足 C,是不是我们所有服务器的数据都要一致对吧,比如,你在其中一个节点服务器修改了某个人的 name 为”小明”,其它服务器也要跟着一起同步那个操作吧,那么你同步的时候,是不是需要时间的,然后机器越多,花的时间就越长,你想想,我们还要满足 A,也就是响应时间是不能太长,那么我们就要在很快的时间去完成同步,那这种情况下,机器就不能太多了,那么我集群节点少了, 那么分区容错性 P 就满足不了啦,是吧?
满足 C 和 P,那么 A 为啥不能满足
满足 C,跟上面说的一样,然后还要满足 P,那就是分区容错性要高,那么我的节点数就会多起来,要去耗时做同步操作,那么就不能在很快时间响应请求获取数据,那么 A 就满足不了了,是吧?你可以跟上面那条对比看看
满足 A 和 P,那么 C 为啥不能满足
满足 A,首先你是要满足请求数据响应时间很快,然后你还要满足 P,要有分区容错性,前面也说了,如果你要达到响应时间快,而且还要有符合 P,也就是会有多个集群节点,那么你就不没办法再去满足数据一致性,因为数据同步一致要时间,分区容错要多机器,那么满足 AP 的话,也许会造成各个节点响应的数据是不一样的,有的节点还是修改前,有点节点还是修改后。
四、NoSQL 的优点/缺点
优点:
· - 高可扩展性
· - 分布式计算
· - 低成本
· - 架构的灵活性,半结构化数据
· - 没有复杂的关系缺点:
· - 没有标准化,可能会对 bean 对象封装造成不便
· - 大多数 nosql 都不支持事务
· - 现有大部分产品不够成熟
五、BASE
BASE 是 NoSQL 数据库通常对可用性及一致性的弱要求原则:
· Basically Availble --基本可用
· Soft-state --软状态/柔性事务。 "Soft state" 可以理解为"无连接"的, 而
"Hard state" 是"面向连接"的
· Eventual Consistency --最终一致性 最终一致性, 也是是 ACID 的最终目的
六、ACID vs BASE
相对之下的,关系型数据库要遵循的则是 ACID 规则
|
ACID |
BASE |
|
原子性(Atomicity) |
基本可用(Basically Available) |
|
一致性(Consistency) |
软状态/柔性事务(Soft state) |
|
隔离性(Isolation) |
最终一致性 (Eventual consistency) |
|
持久性 (Durable) |
七、NoSQL数据库分类
|
类型 |
部分代表 |
特点 |
|
列存储 |
Hbase Cassandra Hypertable |
顾名思义,是按列存储数据的。最大的特点是方便存储结构化和半结构化数据,方便做数据压缩,对针对某一列或者某几列的查询有非常大的 IO 优势。 |
|
文档存储 |
MongoDB CouchDB |
文档存储一般用类似 json 的格式存储,存储的内容是文档型的。这样也就有有机会对某些字段建立索引,实现关系数 据库的某些功能。 |
|
key-value 存储 |
TokyoCabinet/Tyrant BerkeleyDB MemcacheDB
Redis |
可以通过 key 快速查询到其value。一般来说,存储不管value 的格式,照单全收。 (Redis 包含了其他功能) |
|
图存储 |
Neo4J FlockDB |
图形关系的最佳存储。使用传统关系数据库来解决的话性能低下,而且设计使用不方 便。 |
|
对象存储 |
db4o Versant |
通过类似面向对象语言的语法操作数据库,通过对象的方 式存取数据。 |
|
xml 数据库 |
BerkeleyDBXML BaseX |
高效的存储 XML 数据,并支持 XML 的内部查询语法,比如XQuery,Xpath。 |
八、MongoDB 是什么
1、简介
MongoDB 是用 C++语言编写的非关系型数据库。特点是高性能、易部署、易使用,存储数据十分方便。
1.1 、主要特性有
· 面向集合存储,易于存储对象类型的数据
· 模式自由
· 支持动态查询
· 支持完全索引,包含内部对象
· 支持复制和故障恢复
· 使用高效的二进制数据存储,包括大型对象
· 文件存储格式为 BSON(一种 JSON 的扩展)
|
对比项 |
MongoDB |
MySQL Oracle |
|
表 |
集合 |
二维表 table |
|
表的一行数据 |
文档 document |
一条记录 record |
|
表字段 |
键 key |
字段 field |
|
字段值 |
值 value |
值 value |
|
主外键 |
无 |
PK,FK |
|
灵活度扩展性 |
极高 |
差 |
1.2 、MongoDB 与关系型数据库对比
逻辑结构关系对比
关系型数据库:
MySQL 数据库(database)、表(table)、记录(rows)三个层次概念组成。非关系型数据库:
MongoDB 数据库(database)、集合(collection)、文档对象(document)三个层次概念组成。
MongoDB 里的集合对应于关系型数据库里的表,但是集合中没有列、行和关系的概念,集合中只有文档,一个文档就相当于一条记录,这体现了模式自由的特点。
1.3、MongoDB 基本概念
文档(document)是 MongoDB 中数据的基本单元,非常类似于关系型数据库系统中的行(但是比行要复杂的多);
集合(collection)就是一组文档,如果说 MongoDB 中的文档类似于关系型数据库中的行,那么集合就如同表;
MongoDB 的单个实例可以容纳多个独立的数据库,每一个数据库都有自己的集合和权限。MongoDB 自带简洁但功能强大的JavaScript shell,这个工具对于管理 MongoDB 实例和操作数据作用非常大;每一个文档都有一个特殊的键"_id",它在文档所处的集合中是唯一的,相当于关系数据库中的表的主键。
1.4 、MongoDB 数据类型
|
数据类型 |
描述 |
|
String |
字符串。存储数据常用的数据类型。在 MongoDB 中,UTF-8 编码的字符串才是合法的。 |
|
Integer |
整型数值。用于存储数值。根据你所采用的服务器,可分为 32 位 或 64 位。 |
|
Boolean |
布尔值。用于存储布尔值(真/假)。 |
|
Double |
双精度浮点值。用于存储浮点值。 |
|
Min/Max keys |
将一个值与 BSON(二进制的 JSON)元素的最低值和最高值相对比。 |
|
Array |
用于将数组或列表或多个值存储为一个键。 |
|
Timestamp |
时间戳。记录文档修改或添加的具体时间。 |
|
Object |
用于内嵌文档。 |
|
Null |
用于创建空值。 |
|
Symbol |
符号。该数据类型基本上等同于字符串类型,但不同的是,它一 般用于采用特殊符号类型的语言。 |
|
Date |
日期时间。用 UNIX 时间格式来存储当前日期或时间。你可以指定自己的日期时间:创建 Date 对象,传入年月日信息。 |
|
Object ID |
对象 ID。用于创建文档的 ID。 |
|
Binary Data |
二进制数据。用于存储二进制数据。 |
|
Code |
代码类型。用于在文档中存储 JavaScript 代码。 |
|
Regular expression |
正则表达式类型。用于存储正则表达式。 |
2、索引基础知识
2.1、什么是索引
索引最常用的比喻就是书籍的目录,查询索引就像查询一本书的目录。本质上目录是将书中一小部分内容信息(比如题目)和内容的位置信息(页码)共同构成,而由于信息量小(只有题目),所以我们可以很快找到我们想要的信息片段,再根据页码找到相应的内容。同样索引也是只保留某个域的一部分信息(建立了索引的field的信息),以及对应的文档的位置信息。
例如:如下表所示(每行的数据在MongoDB中是存在于一个Document当中)
|
姓名 |
id |
部门 |
籍贯 |
性别 |
年龄 |
|
熊琪 |
2 |
预研部 |
广西 |
女 |
18 |
|
秀雄 |
4 |
预研部 |
广西 |
男 |
23 |
|
天哥 |
3 |
预研部 |
湖北 |
男 |
23 |
|
腾腾 |
1 |
预研部 |
广东 |
男 |
22 |
假如我们想找id为3的document(即天哥的记录),如果没有索引,我们就需要扫描整个数据表,然后找出所有id为3的document。当数据表中有大量documents的时候,这个时间就会非常长(从磁盘上查找数据还涉及大量 的IO操作)。建立索引后会有什么变化呢?MongoDB会将id数据拿出来建立索引数据,如下
|
索引值 |
位置 |
|
1 |
pos4 |
|
2 |
pos1 |
|
3 |
pos3 |
|
4 |
pos2 |
为什么这样速度会快呢?这主要有几方面的因素
1.索引数据通过B+树来存储,从而使得搜索的时间复杂度为O(logdN)级别的(d是B+树的度, 通常d的值比较大,比如大于100),比原先O(N)的复杂度大幅下降。这个差距是惊人的,以一个实际例子来看,假设d=10,N=1亿,那么O(logdN) = 8(s), 而O(N)是1亿。是的,这就是算法的威力。
2.索引本身是在高速缓存当中,相比磁盘IO操作会有大幅的性能提升。(需要注意的是,有的时候数据量非常大的时候,索引数据也会非常大,当大到超出内存容量的时候,会导致部分索引数据存储在磁盘上,这会导致磁盘IO的开销大幅增加,从而影响性能,所以务必要保证有足够的内存能容下所有的索引数据)
当然,事物总有其两面性,在提升查询速度的同时,由于要建立索引,所以写入操作时就需要额外的添加索引的操作,这必然会影响写入的性能,所以当有大量写操作而读操作比较少的时候,且对读操作性能不需要考虑的时候,就不适合建立索引。当然,目前大多数互联网应用都是读操作远大于写操作,因此建立索引很多时候是非常划算和必要的操作。
2.2、MongoDB有哪些类型的索引
1 单键索引
单键索引(Single Field Indexes)顾名思义就是单个字段作为索引列,mongoDB的所有collection默认都有一个单键索引_id,我们也可以对一些经常作为过滤条件的字段设置索引,如给age字段添加一个索引,语法十分简单:
//给age字段添加升序索引
db.um_t_staff.createIndex({age:1})
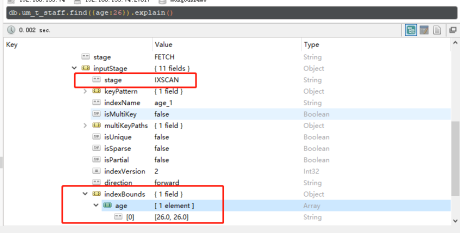
其中{age:1}中的1表示升序,如果想设置倒序索引的话使用 db.um_t_staff.createIndex({age:-1}) 即可。我们通过explain()方法查看查询计划,如下图,看到查询age=23的document时使用了索引,如果没有使用索引的话stage=COLLSCAN。
2 复合索引
复合索引(Compound Indexes)指一个索引包含多个字段,用法和单键索引基本一致。使用复合索引时要注意字段的顺序,如下添加一个name和age的复合索引,name正序,age倒序,document首先按照name正序排序,然后name相同的document按age进行倒序排序。mongoDB中一个复合索引最多可以包含32个字段。
//添加复合索引,name正序,age倒序
db.um_t_staff.createIndex({"name":1,"age":-1})
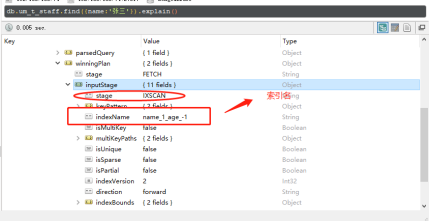
//过滤条件为name,或包含name的查询会使用索引(索引的第一个字段)
db.um_t_staff.find({name:'张三'}).explain()
db.um_t_staff.find({name:"张三",level:10}).explain()db.um_t_staff.find({name:"张三",age:23}).explain()
//查询条件为age时,不会使用上边创建的索引,而是使用的全表扫描
db.um_t_staff.find({age:23}).explain()
3 多键索引
多键索引(mutiKey Indexes)是建在数组上的索引,在mongoDB的document中,有些字段的值为数组,多键索引就是为了提高查询这些数组的效率。看一个栗子:准备测试数据,classes集合中添加两个班级,每个班级都有一个students数组,如下:
db.classes.insertMany([ {
"classname":"class1",
"students":[{name:'jack',age:20},
{name:'tom',age:22},
{name:'lilei',age:25}] },{"classname":"class2",
"students":[{name:'lucy',age:20},
{name:'jim',age:23}, {name:'jarry',age:26}]}] ))

为了提高查询students的效率,我们使用 db.classes.createIndex({'students.age':1}) 给students的age字段添加索引,然后使用索引。
4 哈希索引
哈希索引(hashed Indexes)就是将field的值进行hash计算后作为索引,其强大之处在于实现O(1)查找,当然用哈希索引最主要的功能也就是实现定值查找,对于经常需要排序或查询范围查询的集合不要使用哈希索引。
2.3、mongoDB中常用的索引属性
1 唯一索引
唯一索引(unique indexes)用于为collection添加唯一约束,即强制要求collection中的索引字段没有重复值。添加唯一索引的语法:
//在um_t_staff的name字段添加唯一索引
db.um_t_staff.createIndex({name:1},{unique:true})
2 局部索引
局部索引(Partial Indexes)顾名思义,只对collection的一部分添加索引。创建索引的时候,根据过滤条件判断是否对document添加索引,对于没有添加索引的文档查找时采用的全表扫描,对添加了索引的文档查找时使用索引。使用方法也比较简单:
//um_t_staff集合中age>25的部分添加age字段索引
db.um_t_staff.createIndex( {age:1},
{ partialFilterExpression: {age:{$gt: 25 }}})
//查询age<25的document时,因为age<25的部分没有索引,会全表扫描查找(stage:COLLSCAN)db.um_t_staff.find({age:23})
//查询age>25的document时,因为age>25的部分创建了索引,会使用索引进行查找(stage:IXSCAN)
db.um_t_staff.find({age:26})
当查询age=23的记录时,stage=COLLSCAN,当查询age=26的记录时,使用了索引
3 稀疏索引
稀疏索引(sparse indexes)在有索引字段的document上添加索引,如在address字段上添加稀疏索引时,只有document有address字段时才会添加索引。而普通索引则是为所有的document添加索引,使用普通索引时如果document没有索引字段的话,设置索引字段的值为null。
稀疏索引的创建方式如下,当document包含address字段时才会创建索引:
//创建在address上创建稀疏索引
db.userinfos.createIndex({address:1},{sparse:true})
4 TTL索引
TTL索引(TTL indexes)是一种特殊的单键索引,用于设置document的过期时间,mongoDB会在document过期后将其删除,TTL非常容易实现类似缓存过期策略的功能。我们看一个使用TTL索引的栗子:
//添加测试数据
db.logs.insertMany([
{_id:1,createtime:new Date(),msg:"log1"},
{_id:2,createtime:new Date(),msg:"log2"},
{_id:3,createtime:new Date(),msg:"log3"},
{_id:4,createtime:new Date(),msg:"log4"} ])
//在createtime字段添加TTL索引,过期时间是120s
db.logs.createIndex({createtime:1}, { expireAfterSeconds: 120 })
//logs中的document在创建后的120s后过期,会被mongoDB自动删除
注意:TTL索引只能设置在date类型字段(或者包含date类型的数组)上,过期时间为字段值+exprireAfterSeconds;document过期时不一定就会被立即删除,因为mongoDB执行删除任务的时间间隔是60s;capped Collection不能设置TTL索引,因为mongoDB不能主动删除capped Collection中的document。
九、采用 docker 方式安装部署
1、环境准备
准备一台服务器,虚拟机也行,linux 系统(centos 或者 ubuntu 都行)。分别装上环境 docker、docker-compose。我用的是 Docker version 18.09.0, build 4d60db4、docker-compose version 1.23.0-rc3, buildea3d406e、centos7.4。
可以去官方镜像仓库拉取 docker pull mongo:4.0.5 或者后续我会把离线的 tar包上传到 github 上面,直接下载下来 docker load --input xxx.tar 到服务器即可完成准备之后,docker images 看一下,镜像是否搞定了。

2、编写docker-compose 文件,我这里命名mongodb.yml

3、部署运行
编写保存 mongodb.yml 文件之后。直接在当前目录下执行命令
$docker-compose -f mongodb.yml up -d
然后可能会出现这个报错

问题不大,仔细看一下报错信息,就是说,找不到”base_net”这个 docker 网卡,怎么办?直接创建出来呀,直接把我标注那一部分指令拷贝,出来执行一遍就可以了。

OK,创建出来了,再次启动 docker-compose
$docker-compose -f mongodb.yml up -d

看起来启动成功了,敲一下 docker ps 指令看看

看到 STATUS 状态没有,如果没有一直在 restart 就说明跑起来了。现在我们可以用 mongodb 的可视化工具连接了,我用的是 Robot3T,你们也可以用别的工具,Studio3T 也不错,没有说规定用哪个,看个人喜好和习惯。就比如他们 mysql 都爱用 navicate(三叶草)的,我是喜欢用 SQLyog 的,毕竟比较简洁,navicate UI 做得比较好看一点,但是花里胡哨确实不太适合我。好了,扯了一堆有的没的。接下来,我用 Robot3T 连一下我们搭建的 mongodb 数据库

Test 一下,没问题就连接进去看看
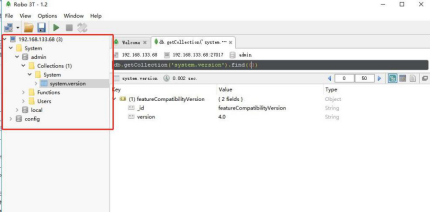
到现在就可以看到, mongodb 的安装部署搭建完成啦, 是不是发现用docker-compose 非常简单(我这不是给 docker 打广告)。
十、实战(springboot2.x 整合 mongodb)
准备
新建一个 springboot 项目,引入以下依赖
<dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter</artifactId> </dependency> <!-- mongo 核心依赖 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-mongodb</artifactId> </dependency> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- lombok 工具类--> <dependency> <groupId>org.projectlombok</groupId> <artifactId>lombok</artifactId>
项目目录结构
配置
接下来我需要讲解的是 springboot 整合 mongodb 的配置。
application.yml 文件:
spring:
data: mongodb:
#mongodb 服务的地址 host: 192.168.133.68
#mongodb 服务的端口
port: 27017
#当前数据源连接的数据库
database: mongodbDemo
server:
port: 8089
mongodb 核心配置,MongoConfig.java
/** *@description mongoDB 配 置 *@author Zhifeng.Zeng */ @Configuration @EnableConfigurationProperties(MongoProperties.class) public class MongoConfig extends AbstractMongoConfiguration { @Autowired private MongoProperties properties; @Override public MongoClient mongoClient(){ return new MongoClient(properties.getHost(),properties.getPort()); } @Override public String getDatabaseName(){ return properties.getDatabase(); } /** *@description: 去除“_class”字段 *@return MappingMongoConverter * @date 2018/08/15 16:24 *@author Rong.Jia *@throws Exception */ @Bean @Override public MappingMongoConverter mappingMongoConverter() throws Exception { MappingMongoConverter mmc = super.mappingMongoConverter(); mmc.setTypeMapper(new DefaultMongoTypeMapper(null));
Api 接口
这里我只编写了一个 UserController,实现了基本的 CRUD。
/** *@author Zhifeng.Zeng *@descrption * @date 2020/05/05 11:20 */ @RestController @RequestMapping("/user") public class UserController { @Autowired private UserService userService; /** *添加用户 *@param userDto */ @PostMapping public ResponseVO addUser(@RequestBody UserDTO userDto){ userService.addUser(userDto); return ResponseVO.success(); } /** *编辑用户 *@param userDto */ @PutMapping public ResponseVO updateUser(@RequestBody UserDTO userDto){ userService.updateUser(userDto); return ResponseVO.success(); } /***删除用户 *@param userId */ @DeleteMapping("/{userId}") public ResponseVO deleteUser(@PathVariable("userId") String userId){ userService.deleteUser(userId); return ResponseVO.success(); } /** *查询用户 */ @GetMapping public ResponseVO<PageVO<UserVO>> findUsers(UserDTO userDTO){ PageVO<UserVO> userVoPageVo = userService.findUsers(userDTO); return ResponseVO.success(userVoPageVo); }
这里所有的接口功能,我都已经在业务代码里实现了,接下来业务接口的相关实现的内容我会贴出来。
业务接口
Userservice.java
/** *@author Zhifeng.Zeng *@descrption 用户管理业务接口 * @date 2020/05/05 12:10 */ public interface UserService { /** *添加用户 *@param userDto */ void addUser(UserDTO userDto); /***编辑用户 *@param userDto */ void updateUser(UserDTO userDto); /** *删除用户 *@param userId */ void deleteUser(String userId); /** *查询用户 */ PageVO<UserVO> findUsers(UserDTO userDTO); }
UserserviceImpl.java
/** *@author Zhifeng.Zeng *@descrption 用户管理业务实现类 * @date 2020/05/05 12:11 */ @Service public class UserServiceImpl implements UserService { @Autowired private UserRepository userRepository; @Override public void addUser(UserDTO userDto) { User user = new User(); BeanUtils.copyProperties(userDto,user); user.setTimestamp(System.currentTimeMillis()); userRepository.addUser(user); } @Override public void updateUser(UserDTO userDto) {User user = new User(); user.setId(new ObjectId(userDto.getId())); BeanUtils.copyProperties(userDto,user); userRepository.updateUser(user); } @Override public void deleteUser(String userId) { userRepository.deleteUser(userId); } @Override public PageVO<UserVO> findUsers(UserDTO userDTO) { PageVO<UserVO> pageVO = new PageVO(); Page<User> userPage = userRepository.findUsers(userDTO); List<User> userList = userPage.getContent(); if(userList!=null && userList.size()>0){ List<UserVO> userVoList = new ArrayList<>(); userList.forEach(user->{ UserVO userVo = new UserVO(); BeanUtils.copyProperties(user,userVo); userVo.setId(user.getId().toHexString()); userVoList.add(userVo); }); pageVO.setRecords(userVoList); } pageVO.setTotalPages(userPage.getTotalPages()); pageVO.setTotal(userPage.getTotalElements()); pageVO.setIsLast(userPage.isLast()); pageVO.setIsFirst(userPage.isFirst()); pageVO.setHasPrevious(userPage.hasPrevious()); pageVO.setCurrentPage(userDTO.getCurrentPage()); pageVO.setPageSize(userDTO.getPageSize()); return pageVO; }
持久层接口
我们做 javaEE 开发的,都知道,我们是遵循 mvc 架构的,mvc 架构不需要我解释了吧! 所以当然还有一层持久层。
UserRepository.java
/** *@author Zhifeng.Zeng *@descrption 用户管理持久化接口 * @date 2020/05/05 12:25 */ public interface UserRepository { /** *添加用户 *@param user */ void addUser(User user); /** *编辑用户 *@param user */ void updateUser(User user); /** *删除用户 *@param userId */ void deleteUser(String userId); /** *查询用户 */ Page<User> findUsers(UserDTO userDTO); }
UserRepositoryImpl.java
/** *@author Zhifeng.Zeng *@descrption 用户管理持久化实现类 * @date 2020/05/05 12:25 */ @Repository public class UserRepositoryImpl implements UserRepository { @Autowired private MongoTemplate mongoTemplate; @Override public void addUser(User user) { mongoTemplate.insert(user); } @Override public void updateUser(User user) { Query updateQuery = new Query(); updateQuery.addCriteria(Criteria.where("_id").is(user.getId().toHexStri ng())); Update update = new Update(); update.set("address",user.getAddress()); update.set("age",user.getAge()); update.set("name",user.getName()); update.set("sex",user.getSex()); mongoTemplate.updateMulti(updateQuery,update,User.class); } @Override public void deleteUser(String userId) { Query deleteQuery = new Query(); deleteQuery.addCriteria(Criteria.where("_id").is(userId)); mongoTemplate.remove(deleteQuery,User.class); } @Override public Page<User> findUsers(UserDTO userDTO) { Query query = new Query(); if(userDTO.getAddress() != null){ Pattern pattern = Pattern.compile("^.*" + userDTO.getAddress() + ".*$", Pattern.CASE_INSENSITIVE); query.addCriteria(Criteria.where("address").regex(pattern)); } if(userDTO.getAge() != null){ query.addCriteria(Criteria.where("age").is(userDTO.getAge())); } if(userDTO.getSex() != null){ query.addCriteria(Criteria.where("sex").is(userDTO.getSex())); } if(userDTO.getName() != null){ query.addCriteria(Criteria.where("name").is(userDTO.getName())); } // 排序方式 Sort sort = new Sort(Sort.Direction.DESC, "timestamp"); // 分页条件 Pageable pageable = PageRequest.of(userDTO.getCurrentPage(), userDTO.getPageSize(), sort); List<User> userList = mongoTemplate.find(query.with(pageable), User.class); long count = mongoTemplate.count(query, User.class); return new PageImpl<>(userList,pageable,count); }
源码
github地址:
https://github.com/githubzengzhifeng/springboot-mongodb
示例
Demo 代码大概就这么多,非常容易理解,接下来看看效果。这里我使用postman(接口测试工具)去对接口做一些简单的测试。先将服务跑起来
(1) 添加用户

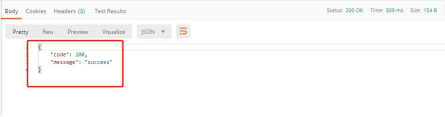
可以看到,返回成功,去看看数据库
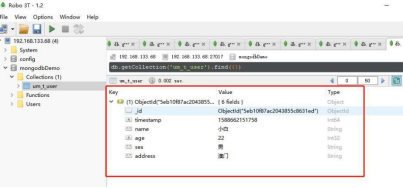
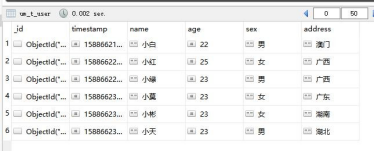
没有问题,为了方便后面调试,我多添加了几个。
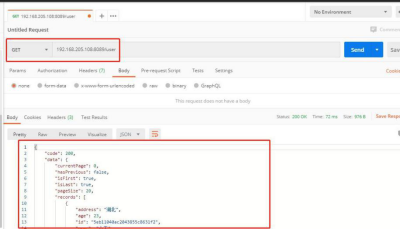
(2) 不传任何条件检索
返回的 responseBody
{ "code": 200, "data": { "currentPage": 0, "hasPrevious": false, "isFirst": true, "isLast": true, "pageSize": 20, "records": [ { "address": "湖北", "age": 23, "id": "5eb11040ac2043855c8631f2", "name": "小天", "sex": "男", "timestamp": 1588662336103 }, { "address": "湖南", "age": 23, "id": "5eb11032ac2043855c8631f1", "name": "小彬", "sex": "女", "timestamp": 1588662322215 }, { "address": "广东", "age": 23, "id": "5eb11026ac2043855c8631f0", "name": "小莫", "sex": "女", "timestamp": 1588662310483 }, { "address": "广西", "age": 23, "id": "5eb11019ac2043855c8631ef", "name": "小绿", "sex": "男", "timestamp": 1588662297421 }, { "address": "广西", "age": 25, "id": "5eb1100bac2043855c8631ee", "name": "小红", "sex": "女", "timestamp": 1588662283491 }, { "address": "澳门", "age": 22, "id": "5eb10f87ac2043855c8631ed", "name": "小白", "sex": "男", "timestamp": 1588662151758 } ], "total": 6, "totalPages": 1 }, "message": "success" }
(3) 带”姓名”条件检索
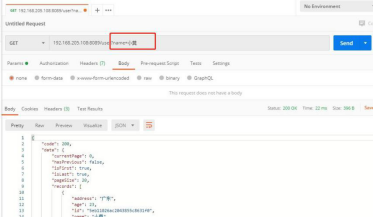
返回的 responseBody
{ "code": 200, "data": { "currentPage": 0, "hasPrevious": false, "isFirst": true, "isLast": true, "pageSize": 20, "records": [ { "address": "广东", "age": 23, "id": "5eb11026ac2043855c8631f0", "name": "小莫", "sex": "女", "timestamp": 1588662310483 } ], "total": 1, "totalPages": 1 }, "message": "success" }
(4) 带”地址”条件检索(地址模糊查询)
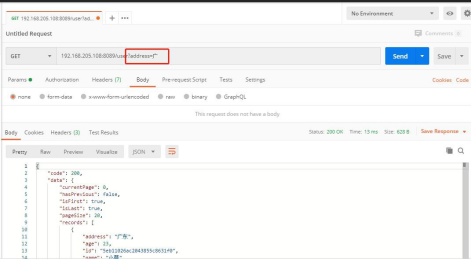
返回的 responseBody
{ "code": 200, "data": { "currentPage": 0, "hasPrevious": false, "isFirst": true, "isLast": true, "pageSize": 20, "records": [ { "address": "广东", "age": 23, "id": "5eb11026ac2043855c8631f0", "name": "小莫", "sex": "女", "timestamp": 1588662310483 }, { "address": "广西", "age": 23, "id": "5eb11019ac2043855c8631ef", "name": "小绿", "sex": "男", "timestamp": 1588662297421 }, { "address": "广西", "age": 25, "id": "5eb1100bac2043855c8631ee", "name": "小红", "sex": "女", "timestamp": 1588662283491 } ], "total": 3, "totalPages": 1 }, "message": "success" }
(5) 编辑用户
这里,我们要把小白的年龄改成 25,地址改成香港
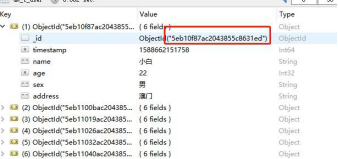
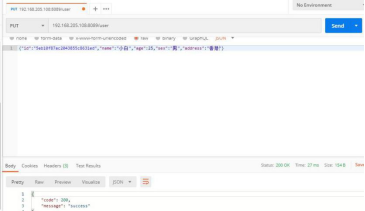
可以看到,返回成功,去看看数据库。
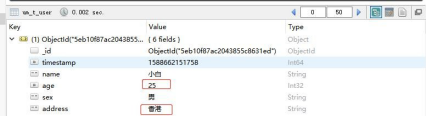
没有问题
(6) 删除用户
这里,我们要把小白这条信息删了
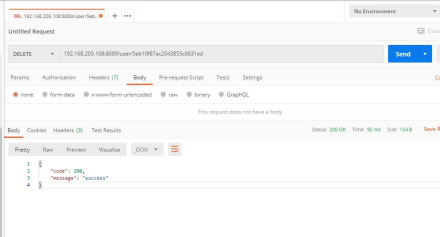
可以看到,返回成功,去看看数据库。
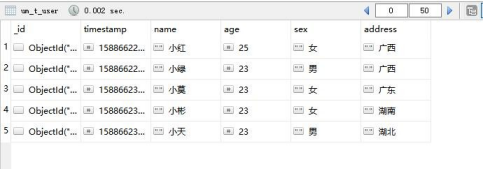
小白没了,说明删除成功。
总结
mongodb 的教程就暂时告一段落了,这只是开始,只是入门的基础。像mongodb 还支持复杂的嵌套对象及嵌套查询、聚合统计查询;高可用(Replica 副本集或 Master-Slave 主从复制)、sharding 分片等等技术,我后续也会把内容做出来。但是,俗话说得好,知识无底,学海无涯,成长还得靠自己。行动起来吧,实践才是检验真理的唯一标准,你们也许会在无数次”踩坑”中学会填坑的。
备注:本文理论主要参考mongodb中文官网
host: 192.168.133.68
