深入理解TCP协议及其源代码-拥塞控制算法分析
这是我的第五篇博客,鉴于前面已经有很多人对前四个题目如三次握手等做了很透彻的分析,本博客将对拥塞控制算法做一个介绍。
首先我会简要介绍下TCP协议,其次给出拥塞控制介绍和源代码分析,最后结合源代码具体分析拥塞控制算法。
一、TCP协议
关于TCP协议,其实在我的第二篇博客中:https://www.cnblogs.com/xiaofengustc/p/12012638.html 已有简要的介绍,并且在该博客中我还拿TCP协议与HTTP协议、UDP协议做了相关对比。有兴趣的同学可以参见我的第二篇博客做进一步的了解。
网上关于TCP协议的内容介绍很多:https://www.jianshu.com/p/e916bfb27daa 这篇文章介绍的极其详细,总结一些必备的基础知识如下:
1.TCP协议产生背景:互联网络与单个网络有很大的不同,因为互联网络的不同部分可能有截然不同的拓扑结构、带宽、延迟、数据包大小和其他参数,且不同主机的应用层之间经常需要可靠的、像管道一样的连接,但是IP层不提供这样的流机制,而是提供不可靠的包交换。
2.TCP是能够动态地适应互联网络的这些特性,而且具备面对各种故障时的健壮性,且能够在不可靠的互联网络上提供可靠的端到端字节流而专门设计的一个传输协议。
3.TCP作用原理过程:
应用层向TCP层发送用于网间传输的、用8位字节表示的数据流,然后TCP把数据流分区成适当长度的报文段(通常受该计算机连接的网络的数据链路层的最大传输单元(MTU)的限制)。之后TCP把结果包传给IP层,由它来通过网络将包传送给接收端实体的TCP层。TCP为了保证不发生丢包,就给每个包一个序号,同时序号也保证了传送到接收端实体的包的按序接收。然后接收端实体对已成功收到的包发回一个相应的确认(ACK);如果发送端实体在合理的往返时延(RTT)内未收到确认,那么对应的数据包就被假设为已丢失将会被进行重传。TCP用一个校验和函数来检验数据是否有错误;在发送和接收时都要计算校验和。
4.TCP协议作用过程的7个要点:数据分片、到达确认、超时重发、滑动窗口、失序处理、重复处理、数据校验(具体可参见百度百科对TCP的解释)
5.TCP首部格式图:

(图片引用自:https://blog.51cto.com/11418774/1835048)
几个重要参数解释如下:
紧急 URG —— 当 URG =1 时,表明紧急指针字段有效。它告诉系统此报文段中有紧急数据,应尽快传送(相当于高优先级的数据)。
确认 ACK —— 只有当 ACK = 1 时确认号字段才有效。当 ACK =0 时,确认号无效。
推送 PSH (PuSH) —— 接收 TCP 收到 PSH = 1 的报文段,就尽快地交付接收应用进程,而不再等到整个缓存都填满了后再向上交付。
复位 RST (ReSeT) —— 当 RST =1 时,表明 TCP 连接中出现严重差错(如由于主机崩溃或其他原因),必须释放连接,然后再重新建立运输连接。
同步 SYN —— 同步 SYN = 1 表示这是一个连接请求或连接接受报文。
终止 FIN (FINis) —— 用来释放一个连接。FIN =1 表明此报文段的发送端的数据已发送完毕,并要求释放运输连接。
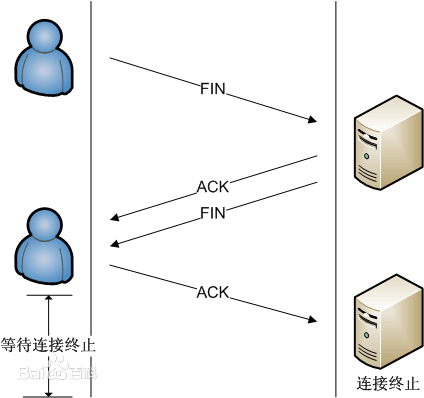
6.TCP工作方式:采用三次握手来建立连接,四次挥手来释放连接,这部分的内容网上资料极其详细,感兴趣的小伙伴可以参见百度百科TCP的内容
如下是TCP连接与终止的过程图: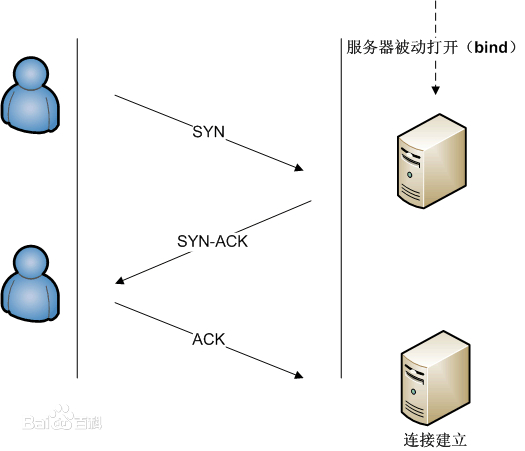
二、拥塞控制介绍和源代码分析
首先在控制拥塞之前,我们需要了解拥塞指代的为何物。
百度百科解释如下:拥塞现象是指到达通信子网中某一部分的分组数量过多,使得该部分网络来不及处理,以致引起这部分乃至整个网络性能下降的现象,严重时甚至会导致网络通信业务陷入停顿,即出现死锁现象。这种现象跟公路网中经常所见的交通拥挤一样,当节假日公路网中车辆大量增加时,各种走向的车流相互干扰,使每辆车到达目的地的时间都相对增加(即延迟增加),甚至有时在某段公路上车辆因堵塞而无法开动(即发生局部死锁)。
造成拥塞的原因由如下两点:
在不同的层处理拥塞有不同的方法,具体如下:
3.在数据链路层可采用:重传策略、乱序缓存策略、确认策略和流控制策略。
本博客重点介绍的是传输层下TCP协议的拥塞控制手段
TCP传统的拥塞控制AIMD算法的四个部分如下:
AIMD传统算法现在已经很少使用了,故不再贴出对它的源代码分析
下面分析目前应用最广泛且较为成熟的Reno算法,该算法所包含的慢启动、拥塞避免和快速重传、快速恢复机制,是现有的众多算法的基础。
源代码位于内核linux5.0.1/net/ipv4/tcp_cong.c中,贴出部分代码分析如下:
/* * TCP Reno congestion control * This is special case used for fallback as well. */ /* This is Jacobson's slow start and congestion avoidance. * SIGCOMM '88, p. 328. */ void tcp_reno_cong_avoid(struct sock *sk, u32 ack, u32 acked) { struct tcp_sock *tp = tcp_sk(sk); if (!tcp_is_cwnd_limited(sk)) return; /* In "safe" area, increase. */ if (tcp_in_slow_start(tp)) { acked = tcp_slow_start(tp, acked); if (!acked) return; } /* In dangerous area, increase slowly. */ tcp_cong_avoid_ai(tp, tp->snd_cwnd, acked); } EXPORT_SYMBOL_GPL(tcp_reno_cong_avoid); /* Slow start threshold is half the congestion window (min 2) */ u32 tcp_reno_ssthresh(struct sock *sk) { const struct tcp_sock *tp = tcp_sk(sk); return max(tp->snd_cwnd >> 1U, 2U); } EXPORT_SYMBOL_GPL(tcp_reno_ssthresh); u32 tcp_reno_undo_cwnd(struct sock *sk) { const struct tcp_sock *tp = tcp_sk(sk); return max(tp->snd_cwnd, tp->prior_cwnd); } EXPORT_SYMBOL_GPL(tcp_reno_undo_cwnd); struct tcp_congestion_ops tcp_reno = { .flags = TCP_CONG_NON_RESTRICTED, .name = "reno", .owner = THIS_MODULE, .ssthresh = tcp_reno_ssthresh, .cong_avoid = tcp_reno_cong_avoid, .undo_cwnd = tcp_reno_undo_cwnd, };
从Reno运行机制中很容易看出,为了维持一个动态平衡,必须周期性地产生一定量的丢失,再加上AIMD机制--减少快,增长慢,尤其是在大窗口环境下,由于一个数据报的丢失所带来的窗口缩小要花费很长的时间来恢复,这样,带宽利用率不可能很高且随着网络的链路带宽不断提升,这种弊端将越来越明显。公平性方面,根据统计数据,Reno的公平性还是得到了相当的肯定,它能够在较大的网络范围内理想地维持公平性原则。
Reno算法以其简单、有效和鲁棒性成为主流,被广泛的采用。
但是它不能有效的处理多个分组从同一个数据窗口丢失的情况。这一问题在New Reno算法中得到解决。
近几年来,随着高带宽延时网络(High Bandwidth-Delay product network)的普及,针对提高TCP带宽利用率这一点上,又涌现出许多新的基于丢包反馈的TCP协议改进,这其中包括HSTCP、STCP、BIC-TCP、CUBIC和H-TCP。
总的来说,基于丢包反馈的协议是一种被动式的拥塞控制机制,其依据网络中的丢包事件来做网络拥塞判断。即便网络中的负载很高时,只要没有产生拥塞丢包,协议就不会主动降低自己的发送速度。这种协议可以最大程度的利用网络剩余带宽,提高吞吐量。然而,由于基于丢包反馈协议在网络近饱和状态下所表现出来的侵略性,一方面大大提高了网络的带宽利用率;但另一方面,对于基于丢包反馈的拥塞控制协议来说,大大提高网络利用率同时意味着下一次拥塞丢包事件为期不远了,所以这些协议在提高网络带宽利用率的同时也间接加大了网络的丢包率,造成整个网络的抖动性加剧。
下面给出BIC-TCP源代码分析如下:位于linux5.0.1/net/ipv4/tcp_bic.c中
/* BIC TCP Parameters */ struct bictcp { u32 cnt; /* increase cwnd by 1 after ACKs */ u32 last_max_cwnd; /* last maximum snd_cwnd */ u32 last_cwnd; /* the last snd_cwnd */ u32 last_time; /* time when updated last_cwnd */ u32 epoch_start; /* beginning of an epoch */ #define ACK_RATIO_SHIFT 4 u32 delayed_ack; /* estimate the ratio of Packets/ACKs << 4 */ }; static inline void bictcp_reset(struct bictcp *ca) { ca->cnt = 0; ca->last_max_cwnd = 0; ca->last_cwnd = 0; ca->last_time = 0; ca->epoch_start = 0; ca->delayed_ack = 2 << ACK_RATIO_SHIFT; } static void bictcp_init(struct sock *sk) { struct bictcp *ca = inet_csk_ca(sk); bictcp_reset(ca); if (initial_ssthresh) tcp_sk(sk)->snd_ssthresh = initial_ssthresh; } /* * Compute congestion window to use. */ static inline void bictcp_update(struct bictcp *ca, u32 cwnd) { if (ca->last_cwnd == cwnd && (s32)(tcp_jiffies32 - ca->last_time) <= HZ / 32) return; ca->last_cwnd = cwnd; ca->last_time = tcp_jiffies32; if (ca->epoch_start == 0) /* record the beginning of an epoch */ ca->epoch_start = tcp_jiffies32; /* start off normal */ if (cwnd <= low_window) { ca->cnt = cwnd; return; } /* binary increase */ if (cwnd < ca->last_max_cwnd) { __u32 dist = (ca->last_max_cwnd - cwnd) / BICTCP_B; if (dist > max_increment) /* linear increase */ ca->cnt = cwnd / max_increment; else if (dist <= 1U) /* binary search increase */ ca->cnt = (cwnd * smooth_part) / BICTCP_B; else /* binary search increase */ ca->cnt = cwnd / dist; } else { /* slow start AMD linear increase */ if (cwnd < ca->last_max_cwnd + BICTCP_B) /* slow start */ ca->cnt = (cwnd * smooth_part) / BICTCP_B; else if (cwnd < ca->last_max_cwnd + max_increment*(BICTCP_B-1)) /* slow start */ ca->cnt = (cwnd * (BICTCP_B-1)) / (cwnd - ca->last_max_cwnd); else /* linear increase */ ca->cnt = cwnd / max_increment; } /* if in slow start or link utilization is very low */ if (ca->last_max_cwnd == 0) { if (ca->cnt > 20) /* increase cwnd 5% per RTT */ ca->cnt = 20; } ca->cnt = (ca->cnt << ACK_RATIO_SHIFT) / ca->delayed_ack; if (ca->cnt == 0) /* cannot be zero */ ca->cnt = 1; } static void bictcp_cong_avoid(struct sock *sk, u32 ack, u32 acked) { struct tcp_sock *tp = tcp_sk(sk); struct bictcp *ca = inet_csk_ca(sk); if (!tcp_is_cwnd_limited(sk)) return; if (tcp_in_slow_start(tp)) tcp_slow_start(tp, acked); else { bictcp_update(ca, tp->snd_cwnd); tcp_cong_avoid_ai(tp, ca->cnt, 1); } }
可以看出其在大大提高了自身吞吐率的同时,也严重影响了Reno流的吞吐率。基于丢包反馈的协议产生如此低劣的TCP友好性的组要原因在于这些协议算法本身的侵略性拥塞窗口管理机制,这些协议通常认为网络只要没有产生丢包就一定存在多余的带宽,从而不断提高自己的发送速率。其发送速率从时间的宏观角度上来看呈现出一种凹形的发展趋势,越接近网络带宽的峰值发送速率增长得越快。这不仅带来了大量拥塞丢包,同时也恶意吞并了网络中其它共存流的带宽资源,造成整个网络的公平性下降。
三、拥塞控制实验演示
可利用Wireshark 记录若干TCP 短流(少于5 秒,如访问web 页面,收发邮件等)和TCP长流(长于1 分钟,如FTP 下载大文件,用HTTP 观看在线视频等)。
对于每个TCP 流,可画出其congestion window 随时间的变化曲线,指出拥塞控制的慢启动、拥塞避免、快恢复等阶段。
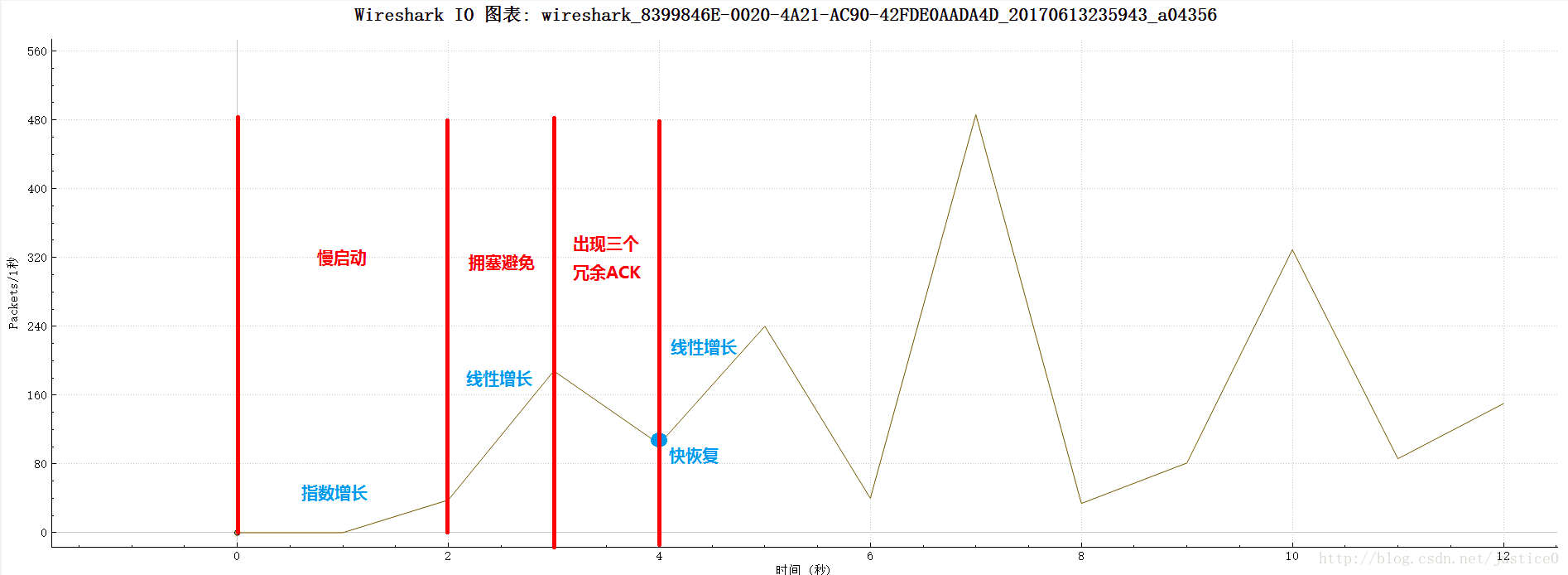
详情可参见:https://blog.csdn.net/justice0/article/details/73697213
总结:选题之前没有意识到拥塞控制在内核中的实现实在太难了,网上对源代码的分析很少很少,本博客介绍的特别肤浅,后续还需要加强对拥塞控制的理解。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号