哈希表(散列表)
一、写在前面的
数组寻址容易,插入和删除困难;而链表寻址困难,但插入和删除容易;结合以上两点,衍生出哈希表结构。
比如在一个动态查找问题中,可以利用AVL树解决,但AVL树更擅长处理数字之间的比较,而变量名之间的比较是字符串之间的比较,字符串之间的比较需要一个一个地比较,比数字之间的比较复杂的多,如果我们可以把字符串通过某种函数(散列函数)转化成数字,然后比较字符串就可以转化成比较两个数字,可以大大提高比较的速度。
二、散列(Hashing)的基本思想:
(1)以关键字key为自变量,通过一个确定的函数(散列函数)计算对应的函数值 h(key),作为数据对象的存储地址。
(2)可能不同的关键字会映射到同一个散列地址上,即 h(key_i)= h(key_ j ),称为“冲突(collision)”,需要某种解决冲突策略。
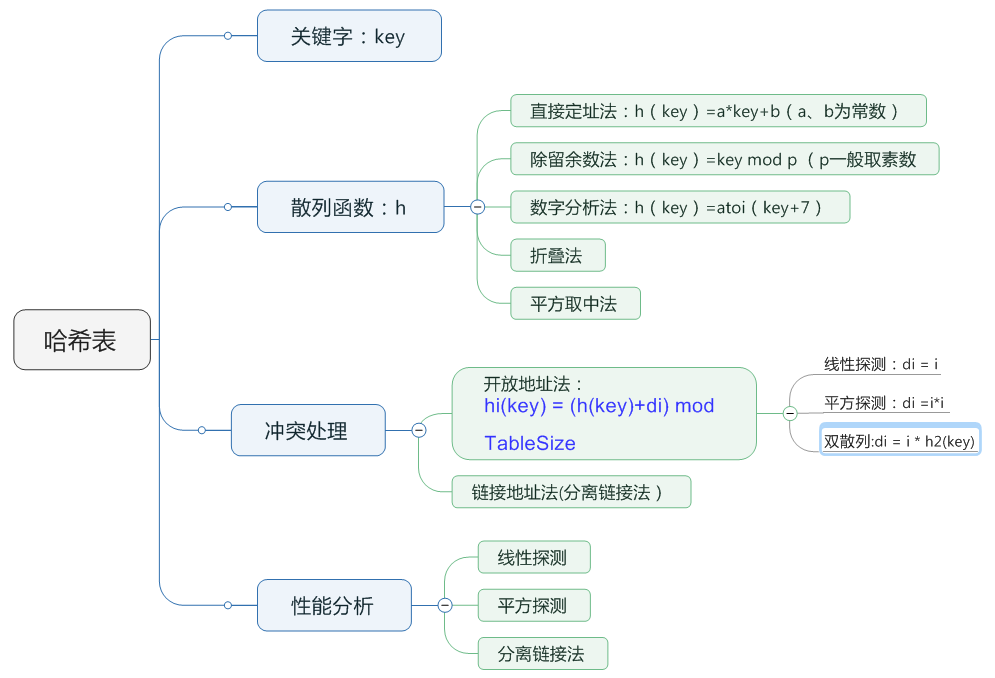
性能分析由于思维导图插入公式比较困难,这里另写出来:
性能分析主要是由平均查找长度(ASL)来度量的,用来度量散列表查找效率即成功或者不成功,关键词的比较次数,取决于冲突的多少,而影响冲突的因素有:散列函数是否均匀、处理冲突的方法、散列表的装填因子α,下面讨论不同的冲突处理方法、装填因子对效率的影响
(1)线性探测
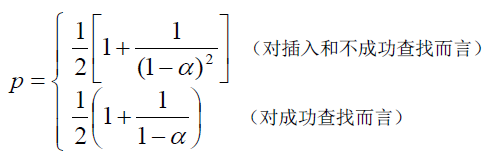
(2) 平方探测法、双散列法

(3)分离链接法的查找性能

既然无论如何时间都会过去,为什么不选择做些有意义的事情呢

 浙公网安备 33010602011771号
浙公网安备 33010602011771号