今日内容概要
第三方模块下载与使用
#第三方模块
别人写的模块 一般情况下功能都特别强大
我们如果要使用第三方模块必须要先下载 才可以反复使用
#下载第三方模块的方式以及注意
1.pip工具
每一个python解释器都自带pip工具 但是在不同版本中pip版本也不同 我们要注意在下载模块时下载到的是哪一个版本
下载模块的语句
pip install 模块名
下载模块临时切换仓库
pip install 模块名 -i 仓库地址
下载模块的指定版本(默认最新版)
pip install 模块名==版本号 -i 仓库地址
#除了可以使用代码实现 在pycharm里是提供了快捷方式
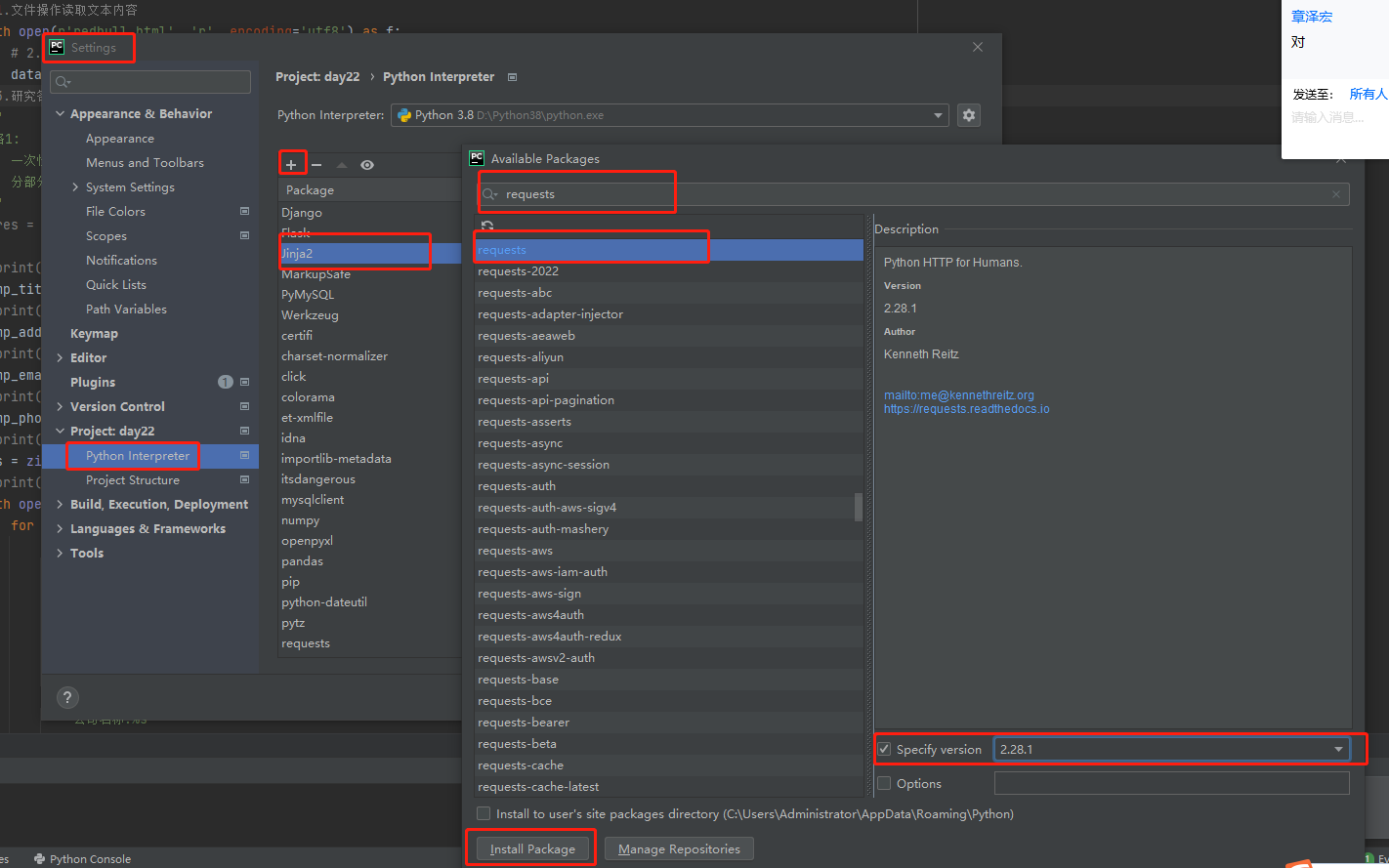
在下载模块可能会出现的问题 以及解决方案
#1.报错并附带警告信息
WARNING: You are using pip version 20.2.1
提示 pip的版本太低 需要更新
d:\python38\python.exe -m pip install --upgrade pip
执行此命名可以自动更新 更新完成重新输入指令就行
#2.报错并含有Timeout关键字
提示的意思就是当前网络不稳定
只要换网重新执行几次就行
#3.报错中若没有关键字
直接百度搜:
pip下载(模块名)报错:报错信息
这类报错一般是要在下载前准备一些东西
#4.下载的速度慢
pip默认的下载地址是在国外 python.org
我们可以手动切换下载的地址
pip install 模块名 -i 仓库地址
eg:
清华大学 :https://pypi.tuna.tsinghua.edu.cn/simple/
阿里云:http://mirrors.aliyun.com/pypi/simple/
中国科学技术大学 :http://pypi.mirrors.ustc.edu.cn/simple/
华中科技大学:http://pypi.hustunique.com/
豆瓣源:http://pypi.douban.com/simple/
腾讯源:http://mirrors.cloud.tencent.com/pypi/simple
华为镜像源:https://repo.huaweicloud.com/repository/pypi/simple/
'''补充:更换下载地址并没有实质性的区别 只是为了提高下载的速度'''
网络爬虫模块之requests模块
requests模块能够模拟浏览器发送请求
import requests
#1.朝之指定网址发送请求获取页面数据(等价于:浏览器地址栏输入网址回车访问)
代码实现:
res = requests('网址名')
print(res.content) # 获取butes类型的网页数据(二进制)
res.encoding = 'utf8' #指定编码
print(res.txt) # 获取字符串类型的网页数据(默认按照utf8)
网络爬虫实战获取链家二手房数据
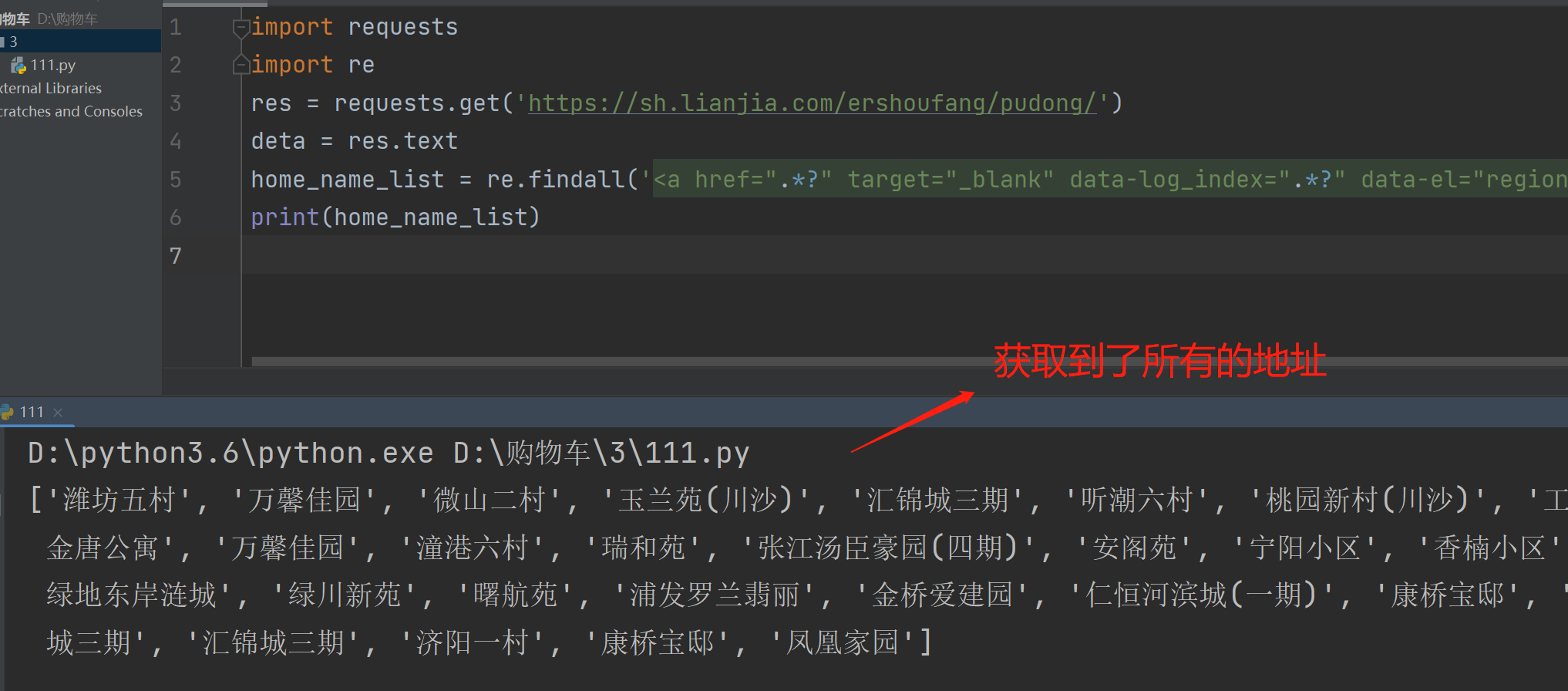
import requests
import re
res = requests.get('https://sh.lianjia.com/ershoufang/pudong/')
deta = res.text
home_title_list = re.findall(
'<a class="" href=".*?" target="_blank" data-log_index=".*?" data-el="ershoufang" data-housecode=".*?" data-is_focus="" data-sl="">(.*?)</a>',
data)
#利用正则表达式来获取我们想要的内容
print(home_title_list)
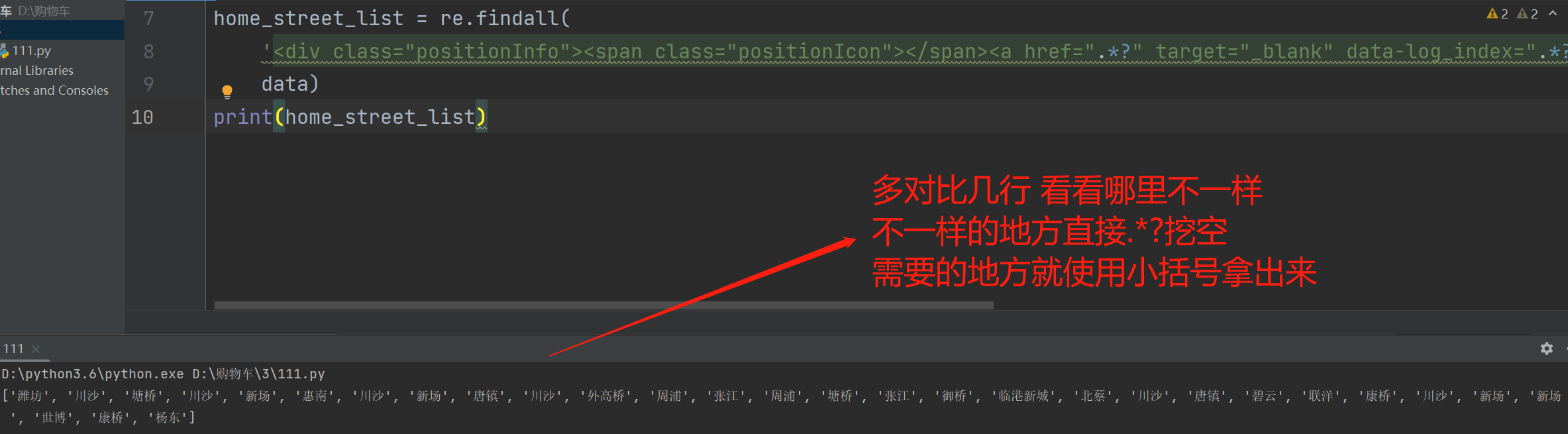
home_street_list = re.findall(
'<div class="positionInfo"><span class="positionIcon"></span><a href=".*?" target="_blank" data-log_index=".*?" data-el="region">.*? </a> - <a href=".*?" target="_blank">(.*?)</a> </div>',
data)
print(home_street_list)
#以次类推
#我们可以获取到我们所需的数据 让后将其总结到一起
可以使用到zip()
home = zip(home_title_list,home_street_list)
#也可以选择写入到文件保存
with open(r'文件地址','w',encoding='utf8') as f:
for data in home:
f.write('''
1.信息1:%s
2.信息2:%s
'''data)
自动化办公领域之openpyxl模块
1.excel文件的后缀问题
03版本之前
.xls
02版本之前
.xlsx
2.操作excel表格的第三方模块
xlwt往表格中写入数据,wlrd从表格中读取数据
兼容性所有版本的excel文件
openpyxl最近几年比较火热的操作excel表格的模块
03版本之前的兼容性较差
ps:还有很多操作excel表格的模块 甚至覆盖了上述的模块>>>:pandas
3.openpyxl操作:
'''在官方文档中有详细的记载'''
from openpyxl import Workbook
#创建一个excel文件
wb = Workbook()
#在一个excel文件内创建多个工作簿
wb1 = wb.create_sheet('学生名单')
wb2 = wb.create_sheet('上海富婆通讯录')
#还可以移动位置
wb3 = wb.create_sheet('上海富婆通讯录',0) #移至最前
#二次修改工作簿名字
wb3.title = '上海米女通讯录'
#修改字体及颜色
wb4.sheet_properties.tabColor = '1072BA'
#填写数据的方式
1.wb4['G4'] = 666 # 在G4位置填写数据666
2.wb4.cell(row=3, column=1, value=666) #在行数为3列数为1的位置填写数据666
3.wb4.append() 默认横着填写
#填写数学公式
wb4.call(row=a,column=b,value='c')
a处填写行数 b处填写列数 c处可以填写数据值 也可以直接填写数学公式
eg:
wb4.call(row=4,column=4,value='sum(A1,A3)')
计算A1到A3的总和 将结果直接写道4,4
#保存excel文件
wb4.save(r'111.xlsx')
'''
openpyxl 主要用于数据的写入 至于后续的表单操作并不擅长 如果想做需要更高级的模块pands
import pands
data_dict = {
"公司名称": comp_title_list,
"公司地址": comp_address_list,
"公司邮编": comp_email_list,
"公司电话": comp_phone_list
}
将字典转换pandas里面的DataFrame数据结构
df = pandas.DataFrme(data_dict)
直接保存excel文件
df.to_excel(r'pd_comp_info.xlsx')
excel软件正常可以打开操作的数据集在10万左右 一旦数据集过大 软件操作基本无效 需要代码进行操作>>>:pandas模块
'''






 浙公网安备 33010602011771号
浙公网安备 33010602011771号