今日内容总结
1.字符组
'''字符的默认的匹配顺序是从前往后'''
[0123456789] 从0到九
[0-9] 简写
[a-z] 字母a到z
[A-Z] 大写字母A到Z
[0-9a-z] 字符组默认或的关系
2.特殊符号
'''特殊符号默认也是挨个匹配'''
. 匹配除换行符意外的所有
\w 匹配数字 字母 下划线
\W 和上面相反
\d 匹配数字
^ 匹配开头
$ 匹配结尾
^a$ 限制匹配的内容
a|b 匹配a或者b
() 分组功能 不影响匹配功能
[] 字符组 内部默认或的关系
[^] 取反操作 匹配除里面的所有
3.量词
'''正则表达式默认情况都是贪婪匹配(能拿多绝不拿少)'''
* 匹配一次或者多次 默认无穷次
+ 匹配一次或者多次 默认无穷次
? 匹配零次或者一次 用于将贪婪匹配变成非贪婪
{n} 重复n次
{n,} 重复n次或者更多次
{n,m} 重复n到m次
# 量词要和结合表达式一起使用 不能单独出现 并且只影响左边的第一个表达式
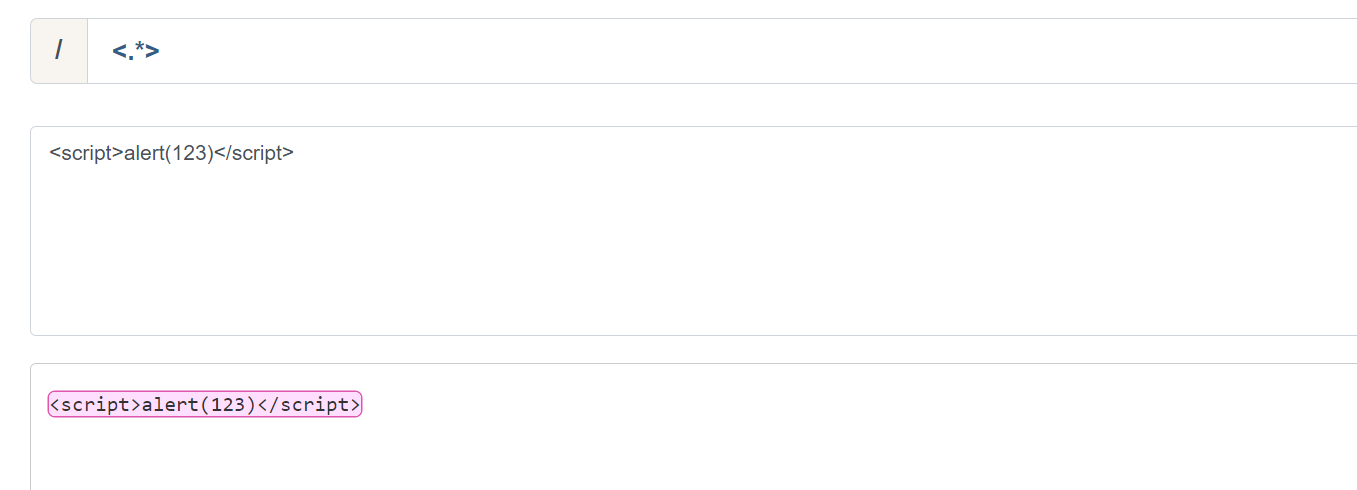
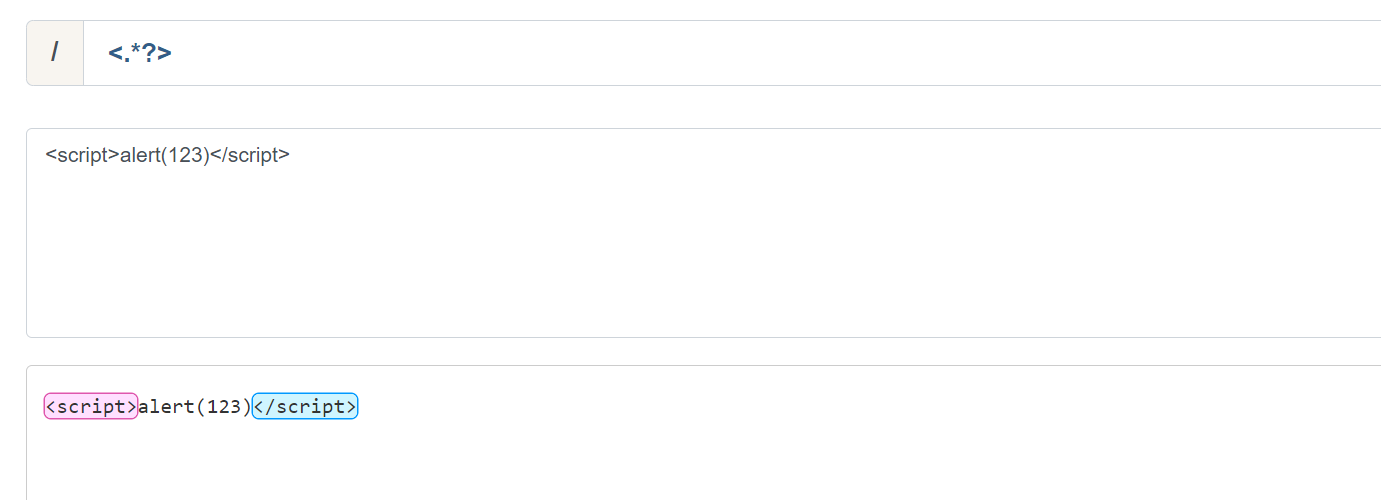
4.贪婪匹配与非贪婪匹配
'''只要在量词后加上?就可以转换成非贪婪匹配'''
eg:<script>alert(123)</script>
使用贪婪匹配
使用非贪婪匹配
5.转义符
'''由于斜杠和字符会有特殊含义'''
eg:
\n 表达换行符
\\n 则不会有什么意义
要想打出\\n 则需要\\\\n
在python中使用r""可以作为转义符
6.正则表达式实战建议
#使用的方面很多
1.校验身份证的输入是否正确
2.编写校验邮箱正则
3.编写校验用户手机号的正则
4.编写教养用户qq号的正则
but 许多正则是已经有的 我们可以取前人写好了的
7.re模块
#在python中使用re模块
import re
'''
常见的操作
res = re.findall('a','jason apple aaa')
print(res) 查找符合要求的字符组 返回的结果是一个列表
res = re.finditer('a','jason apple aaa')
print(res) 也是查找符合结果的字符组 但返回的是一个迭代器对象
res = re.search('a','jason apple aaa')
print(res) 所打印的结果不可读
print(res.group()) 匹配到第一个符合条件的就结束
res = re.match('a','jason apple aaa')
print(res) None
print(res.group()) 如果开头不满足也就不会有后后续了
'''
#当我们需要频繁使用可以将其组成模板
obj = re.compile('\d{3}')
res1 = obj.findall('ssadsadad')
res2 = obj.findall('sahdsja')
print(res1,res2)
就可以直接使用
#分割操作
res = re.split('[a,b]','abcd')
先按照a进行切割 结果是:['','bcd']
再按照b进行切割 ['','','cd']
#代替操作
res = re.sub('\d','h','snajdsn2s332',1) # 将数字替换成h 替换的数量为1个
如果没有添加次数参数 返回的则是一个元组
格式:('替换后的格式',被替换的数量)
8.re模块补充说明
#1.分组优先
res = re.findall('www.(bbb|aaa).com','www.aaa.com')
print(res) #['aaa']
小括号内被定义为一个分组 会优先展示分组中的内容
使用?:可以取消分组的优先
res = re.findall('www.(?:bbb|aaa).com','www.aaa.com')
print(res) #['www.aaa.com']
使用group()也可以取消分组优先
#2.分组别名
res = re.search('www.(?P<别名>adsad|sadasd).com','www.sadasd.com')
print(res.group()) # www.sadasd.com
print(res.group('别名')) # sadasd
print(res.group(1)) # sadasd
不建议使用索引取值的方式来 会混乱
9.网络爬虫
#正则表达式的最大作用就是可以对数据进行一个筛选 而爬虫需要的就是对数据的筛选





 浙公网安备 33010602011771号
浙公网安备 33010602011771号