今日学习详情
字典的类型转换
1.类型转换:
dict()
字典的转换太过于麻烦所以通常使用手打
2.字典的基本操作
user_dict = {
'username':'xiaochen',
'password':123,
'hobby':['music', 'read']
}
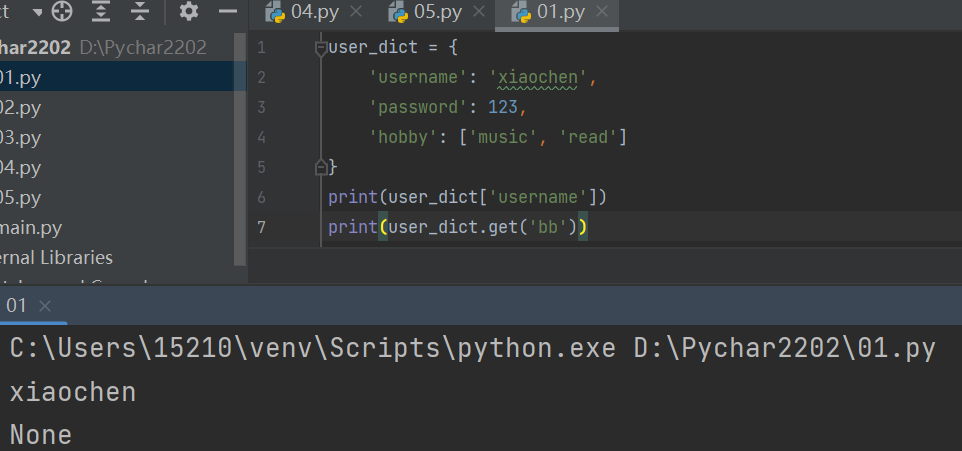
1.按k取值(不推荐使用)
print(user_dict[username]) # 'xiaochen'
#注意 如果k不存在会直接报错
2.按内置方法get使用取值
print(user_dict('bb'))
#可以打印不存在的k并且不会报错,当没有k是默认打none,在后面添加可自定义打印内容
3.修改数据数值
user_dict(username) = 'jason' # 如果键存在直接修改数据
4.新增键值对
useer_dict(name) = 19 # 键不存在直接添加到字典中
5.删除数据
del user_dict[username]
user_dict.pop(username) # 并不是删除只是移出
6.统计字典中键值对的个数
print(len(username))
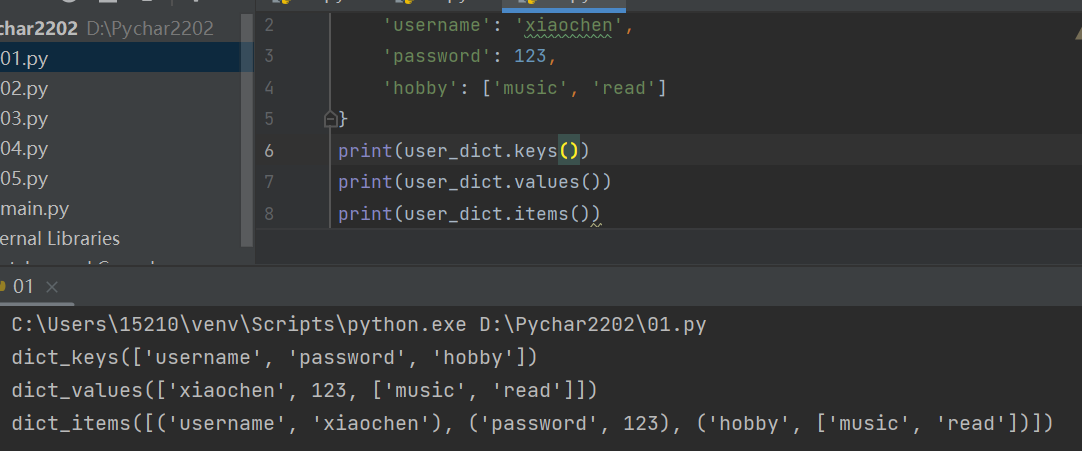
7.字典三剑客
print(user_dict.keys()) # 打印字典中所有的键
print(user_dict.values()) # 打印字典中所有的值
print(user_dict.itmes()) # 打印出所有键值对
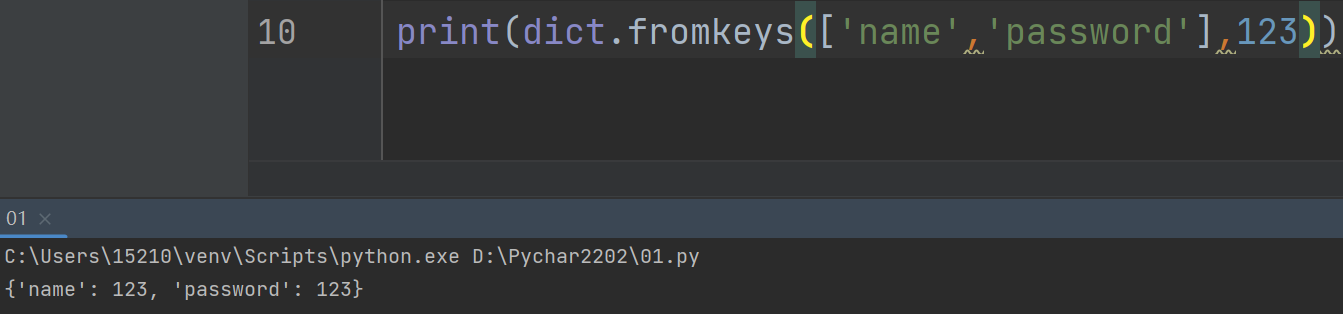
8.补充说明
print(user_dict.formkeys(['name','password'],123))
# 直接打印一个数据值相等的字典
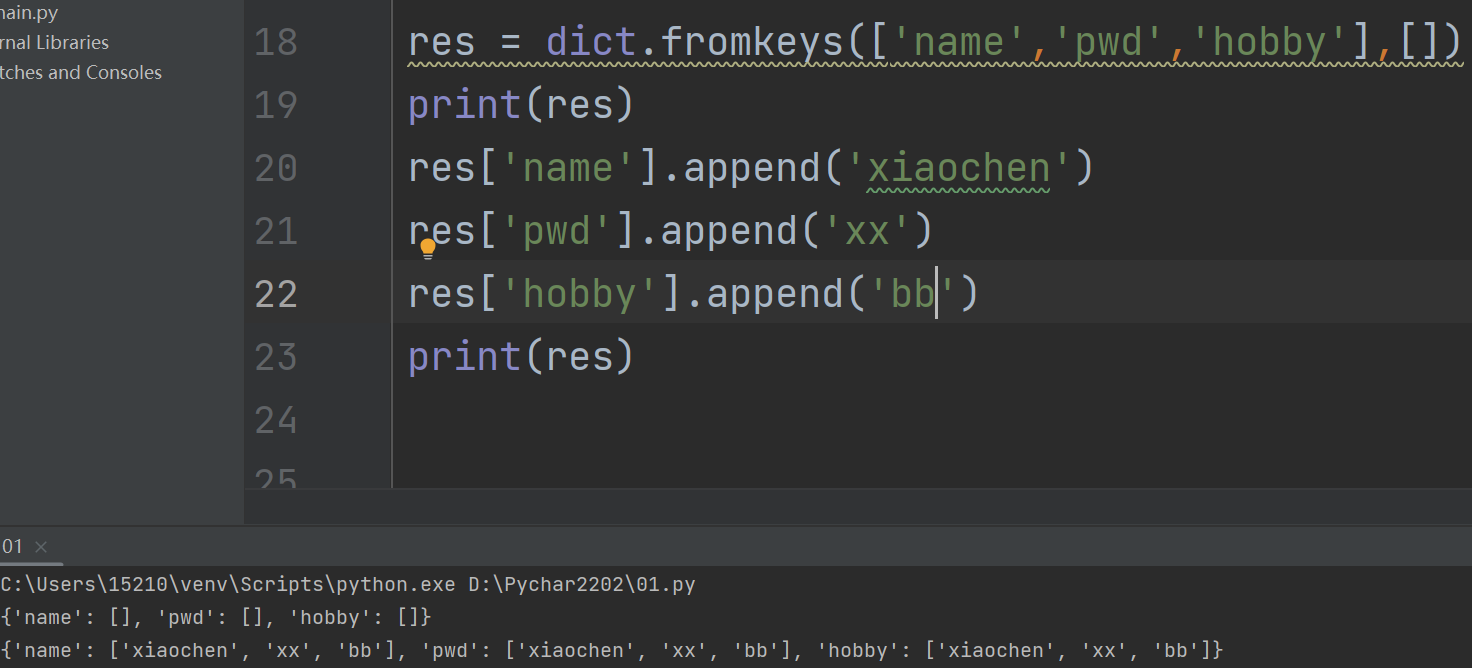
res = dict.fromkeys(['name','pwd','hobby'],[])
print(res)
res['name'].append('xiaochen')
res['pwd'].append('xx')
res['hobby'].append('bb')
print(res)
# 添加一处则会给全部值添加
res = user_dict.setdefault('username','jony')
print(user_dict,res) # 键存在则不修改数值 结果是键对应的值
res = user_dict.setdefault('age',20)
print(user_dict,res) # 不存在则新建一个键值对 结果是新增的值
元组的类型转换
1.类型转换
tuple()
# 支持for循环的数据都支持转变成元组
2.元组的基本操作
1.索引取值
2.切片操作
3.间隔 方向
4.统计元组数据值的总数
print(len(t1))
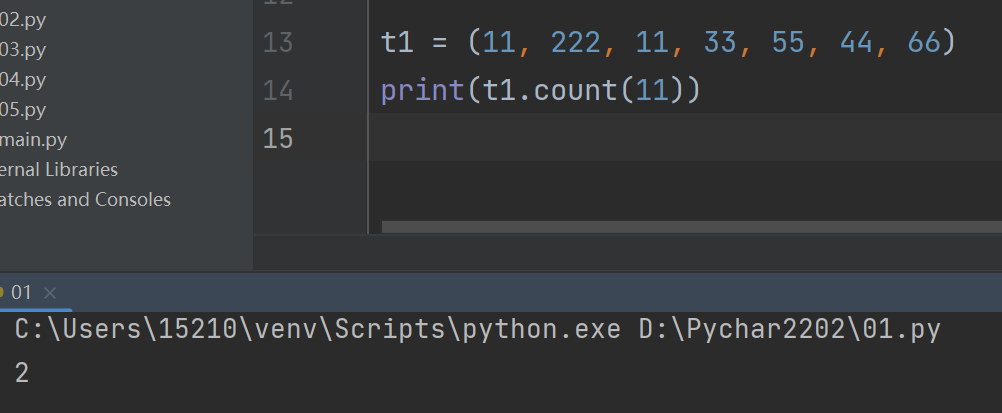
5.统计元组中某一数据出现的次数
print(t1.count(11))
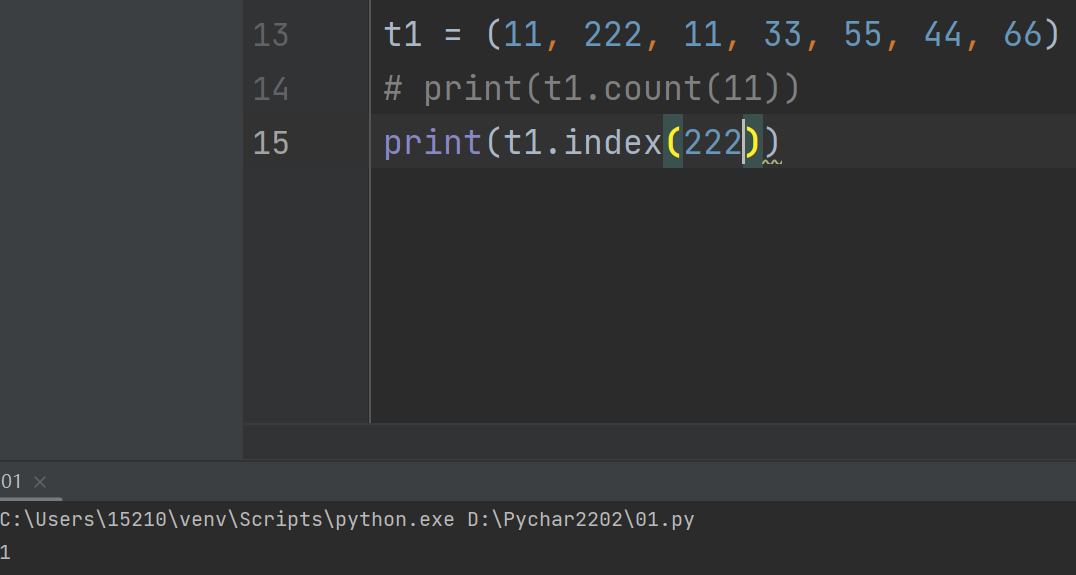
6.统计元组中内指定数据值的索引值
print(t1.index(22))
7.元组中如果只有一个数据也需加上逗号
8.元组内被绑定的内存地址无法被修改
9.元组不能添加和删除数据
集合的类型转换
1.类型转换
set()
集合内数据必须是不可变类型(整形 浮点型 字符串 元组)
# 集合数据是无序的 没有索引概念
2.集合所需掌握的用法
去重
关系运算
# 很少使用集合 只有以上两种需求才考虑使用集合
3.去重
集合内所有的元素不得重复 所以在转变为集合时会将重复的数据移除
"""去重后的数据无法保持原先的顺序"""
4.关系运算
# 集合的各个关系(交集 并集 补集 全集)
f1={'jason','xiaochen','bb','cc'}
f2={'cc','dd','xiaochen','jason'}
# 求两个集合的共同部分
print(f1 & f2)
# 求f1 中独有的元素
print(f1-f2)
# 求两个集合所有的元素
print(f1 | f2)
# 求两个集合特有的元素
print(f1 ^ f2)
5.父集和子集
print(f1 < f2)
print(f1 > f2)
# 包含关系
字符编码理论
1.字符编码只针对文本数据
2.计算机储存数据的本质是利用二进制
3.字符编码本利用01表达我们所认识的字符
4.字符编程史
4.1.一家独大
计算机是由美国人发明的 为了能够让计算机识别英文
需要发明一个数字跟英文字母的对应关系
ASCII码:记录了英文字母跟数字的对应关系
用8bit(1字节)来表示一个英文字符
4.2.群雄割据
中国人
GBK码:记录了英文、中文与数字的对应关系
用至少16bit(2字节)来表示一个中文字符
很多生僻字还需要使用更多的字节
英文还是用8bit(1字节)来表示
日本人
shift_JIS码:记录了英文、日文与数字的对应关系
韩国人
Euc_kr码:记录了英文、韩文与数字的对应关系
"""
每个国家的计算机使用的都是自己定制的编码本
不同国家的文本数据无法直接交互 会出现"乱码"
"""
4.3.天下一统
unicode万国码
兼容所有国家语言字符
起步就是两个字节来表示字符
utf系列:utf8 utf16 ...
专门用于优化unocide存储问题
英文还是采用一个字节 中文三个字节
字符编码实操
1.针对乱码不要慌 切换编码慢慢试即可
2.编码与解码
编码:将人类的字符按照指定的编码编码成计算机能够读懂的数据
字符串.encode()
解码:将计算机能够读懂的数据按照指定的编码解码成人能够读懂
bytes类型数据.decode()
3.python2与python3差异
python2默认的编码是ASCII
1.文件头
# encoding:utf8
2.字符串前面加u
u'你好啊'
python3默认的编码是utf系列(unicode)





 浙公网安备 33010602011771号
浙公网安备 33010602011771号