Ollama本地部署qwen2.5
一、概述
Ollama 是一个开源的本地大语言模型运行框架,专为在本地机器上便捷部署和运行大型语言模型(LLM)而设计。支持多种操作系统,包括 macOS、Windows、Linux 以及通过 Docker 容器运行。Ollama 提供对模型量化的支持,可以显著降低显存要求,使得在普通家用计算机上运行大型模型成为可能。
二、安装Ollama
环境
操作系统:Windows 11专业版
cpu:4核
内存:16G
显存:2G
下载
下载window版本,然后下一步,下一步安装即可。
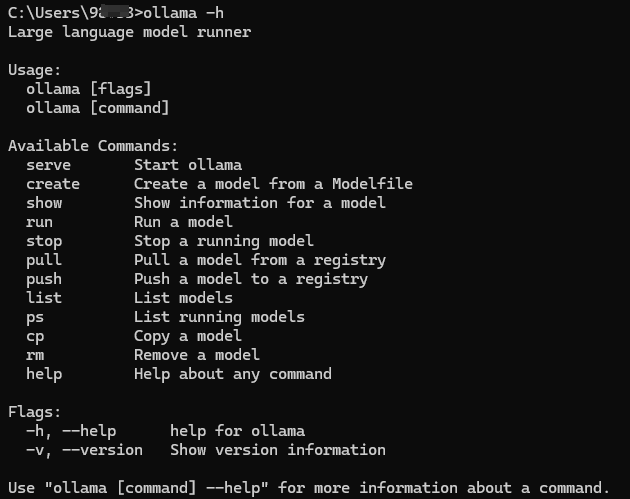
安装成功后,打开cmd窗口,验证ollama是否安装成功
环境变量
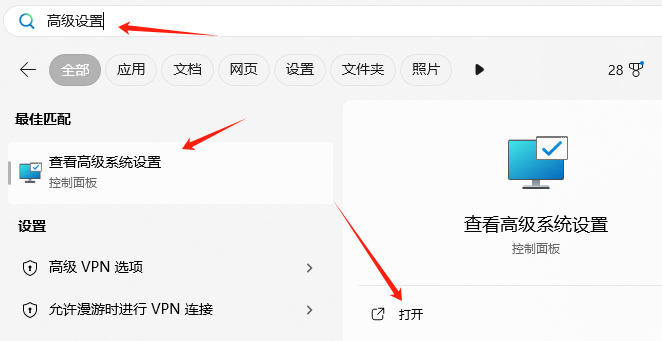
在下载模型之前,先设置一下环境变量,默认会下载到C盘。如果你的C盘空间足够大,可以忽略。
搜索高级设置,打开
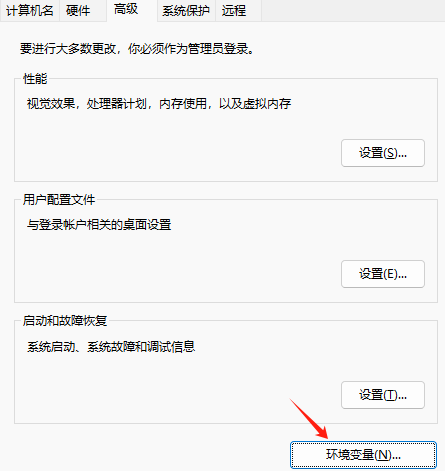
点击环境变量
添加2个环境变量
OLLAMA_MODELS,E:\Ollama\models
OPENAI_API_KEY,e85ed351-1bf4-49ea-8c95-945cdbb85eef
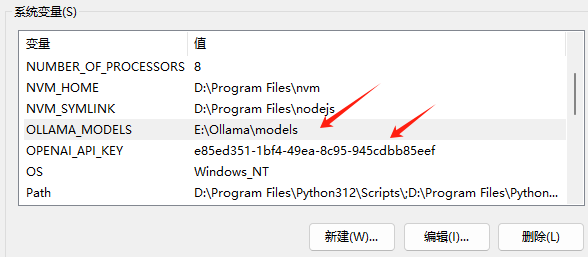
参数解释:
OLLAMA_MODELS,模型下载的默认目录,因为e盘空间比较大,所以设置在这里。
OPENAI_API_KEY,这个是用来给AI模型客户端使用的,用来调用大模型。
三、下载模型
打开网页:https://ollama.com,搜索关键字qwen2.5,就会跳转页面:https://ollama.com/library/qwen2.5
这里选择3b,相对比较最小的模型
复制命令,到cmd运行
ollama run qwen2.5:3b
下载成功后,效果如下:

注意:ollama下载模型的过程中,会进行限速。比如:82秒之后,速度就会明显下降!
解决办法,就是中断下载,然后再次下载,会接着上一次下载的文件继续下载,速度就会提升上来。到了82秒之后,会再次下降,如此往复循环。
然后,就可以提问了。


 浙公网安备 33010602011771号
浙公网安备 33010602011771号