并发编程之GIL解释器锁
引言
首先需要明确的一点是GIL并不是Python的特性,它是在实现Python解析器(CPython)时所引入的一个概念。就好比C++是一套语言(语法)标准,但是可以用不同的编译器来编译成可执行代码。有名的编译器例如GCC,INTEL C++,Visual C++等。Python也一样,同样一段代码可以通过CPython,PyPy,Psyco等不同的Python执行环境来执行。像其中的JPython就没有GIL。然而因为CPython是大部分环境下默认的Python执行环境。所以在很多人的概念里CPython就是Python,也就想当然的把GIL归结为Python语言的缺陷。所以这里要先明确一点:GIL并不是Python的特性,Python完全可以不依赖于GIL。
GIL文献,建议深入了解的可以查看:
http://www.dabeaz.com/python/UnderstandingGIL.pdf
什么是GIL
GIL 是python的全局解释器锁,同一进程中假如有多个线程运行,一个线程在运行python程序的时候会霸占python解释器(加了一把锁即GIL),使该进程内的其他线程无法运行,等该线程运行完后其他线程才能运行。如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。所以在多线程中,线程的运行仍是有先后顺序的,并不是同时进行。
我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。GIL只在Cpython中才有。
GIL通俗介绍
GIL本质就是一把互斥锁,既然是互斥锁,所有互斥锁的本质都一样,都是将并发运行变成串行,以此来控制同一时间内共享数据只能被一个任务所修改,进而保证数据安全。
可以肯定的一点是:保护不同的数据的安全,就应该加不同的锁。
要想了解GIL,首先确定一点:每次执行python程序,都会产生一个独立的进程。例如python test.py,python aaa.py,python bbb.py会产生3个不同的python进程
在一个python的进程内,不仅有test.py的主线程或者由该主线程开启的其他线程,还有解释器开启的垃圾回收等解释器级别的线程,总之,所有线程都运行在这一个进程内,毫无疑问。
了解的事实:
1、所有数据都是共享的,这其中,代码作为一种数据也是被所有线程共享的(test.py的所有代码以及Cpython解释器的所有代码)
例如:test.py定义一个函数work(代码内容如下图),在进程内所有线程都能访问到work的代码,于是我们可以开启三个线程然后target都指向该代码,能访问到意味着就是可以执行。
2、所有线程的任务,都需要将任务的代码当做参数传给解释器的代码去执行,即所有的线程要想运行自己的任务,首先需要解决的是能够访问到解释器的代码。
什么时候释放GIL锁
1、某个线程运行完后其他线程才能运行。
2、如果线程运行过程中遇到耗时操作,则解释器锁解开,使其他线程运行。
为什么会有GIL锁
python使用引用计数为主,标记清楚和隔代回收为辅来进行内存管理。所有python脚本中创建的对象,都会配备一个引用计数,来记录有多少个指针来指向它。当对象的引用技术为0时,会自动释放其所占用的内存。
假设有2个python线程同时引用一个数据(a=100,引用计数为1),2个线程都会去操作该数据,由于多线程对同一个资源的竞争,实际上引用计数为3,但是由于没有GIL锁,导致引用计数只增加1(引用计数为2),这造成的后果是,当第1个线程结束时,会把引用计数减少为1;当第2个线程结束时,会把引用计数减少为0;当下一个线程再次视图访问这个数据时,就无法找到有效的内存了。

GIL和Lock锁的区别
Python已经有一个GIL来保证同一时间只能有一个线程来执行了,为什么这里还需要lock? Lock是用户级的lock,跟那个GIL没关系。GIL 是Python 中对解析器使用。
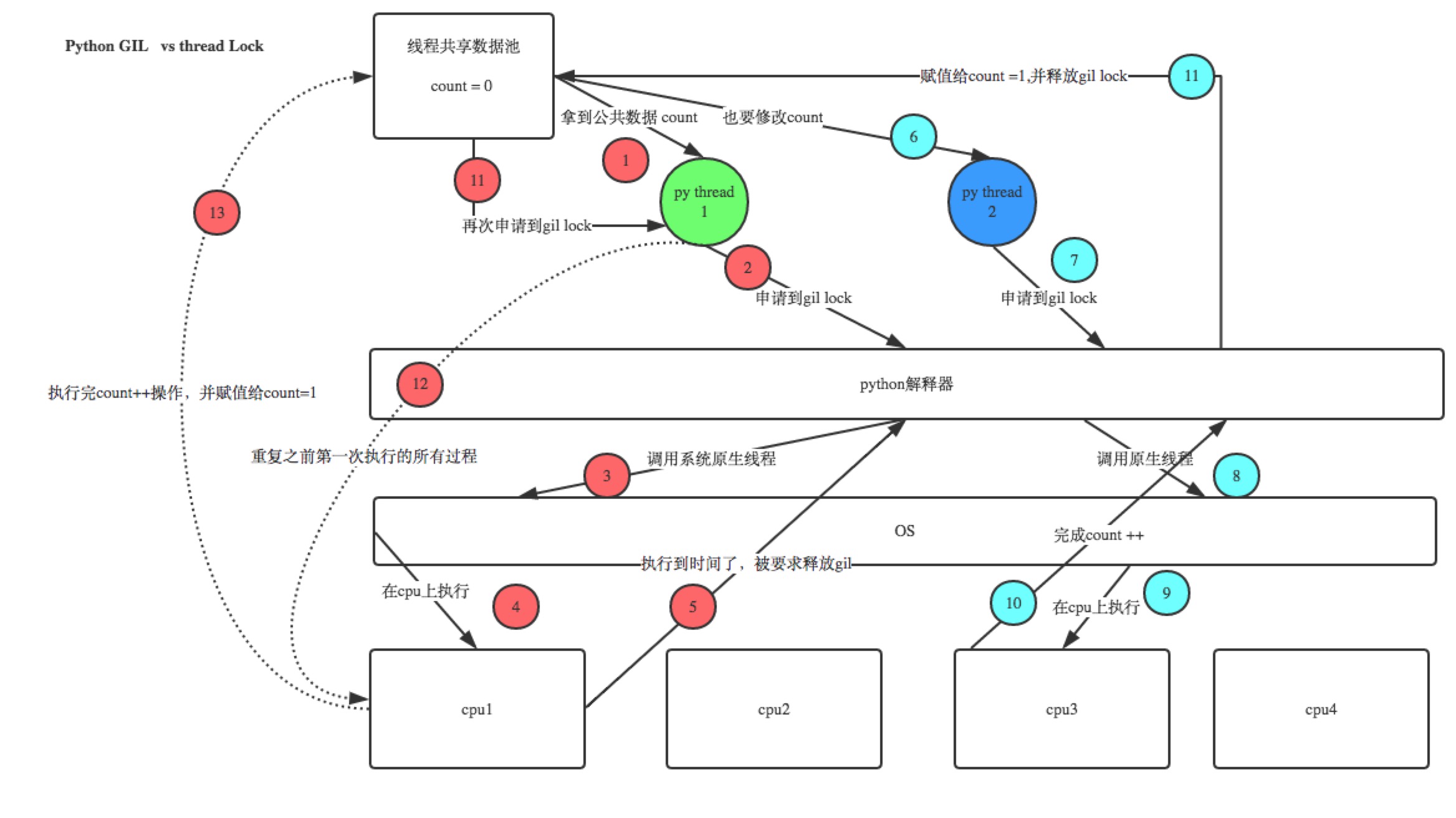
示例分析:
- 自动加锁并解锁
- 子线程启动 , 后先去抢 GIL 锁 , 进入 IO 自动释放 GIL 锁 , 但是自己加的锁还没解开 ,其他线程资源能抢到 GIL 锁,但是抢不到互斥锁
- 最终 GIL 回到 互斥锁的那个进程上,处理数据
from threading import Thread, Lock
import time
mutex = Lock()
money = 100
def task():
global money
# 自动执行 加锁 再解锁操作
with mutex:
temp = money
time.sleep(0.1) # 只要进入 IO 会自动释放 GIL 锁
money -= temp
def main():
t_list = []
for i in range(100):
t = Thread(target=task)
t.start()
t_list.append(t)
for t in t_list:
t.join()
print(money)
if __name__ == '__main__':
main()
GIL导致多线程无法利用多核优势
在 Cpython 解释器中 GIL 是一把互斥锁,用来阻止同一个进程下的多个线程的同时进行
-
同一个进程下的多个线程无法利用这一优势?
-
Python的多线程是不是一点用都没有?
-
同一个进程下的多线程无法利用多核优势,是不是就没用了
-
多线程是否有用要看情况
-
单核
- 四个任务(IO密集型/计算密集型)
-
多核
- 四个任务(IO密集型/计算密集型)
-
-
因为在
Cpython中的内存管理不是线程安全的- ps:内存管理(垃圾回收机制)
- 引用计数
- 标记清除
- 分代回收
- ps:内存管理(垃圾回收机制)
分析
对于需要执行的任务来说,分为两种:计算密集型、IO 密集型
计算密集型:要进行大量的数值计算,例如进行上亿的数字计算、计算圆周率、对视频进行高清解码等等。这种计算密集型任务虽然也可以用多任务完成,但是花费的主要时间在任务切换的时间,此时CPU执行任务的效率比较低。
IO密集型:涉及到网络请求(time.sleep())、磁盘IO的任务都是IO密集型任务,这类任务的特点是CPU消耗很少,任务的大部分时间都在等待IO操作完成(因为IO的速度远远低于CPU和内存的速度)。对于IO密集型任务,任务越多,CPU效率越高,但也有一个限度。
假如一个计算密集型的任务需要10s的执行时间,总共有4个这样的任务
在 4核及以上的情况下:
多进程:需要开启 4 个进程,但是 4 个 CPU 并行,最终只需要消耗 10s 多一点的时间。
多线程:只需要开1 个进程,这个进程开启 4 个线程,开启线程所消耗的资源很少,但是由于最终执行是只有一个 CPU 可以工作,所以最终消耗 40s 多的时间。
假如是多个 IO密集型 的任务
CPU 大多数时间是处于闲置状态,频繁的切换
多进程:进程进行切换需要消耗大量资源
多线程:线程进行切换并不需要消耗大量资源
(1) 计算密集型——采用多进程
执行时间为: 2.474289894104004
from multiprocessing import Process
import time
def func1():
sum=0
for i in range(100000000):
sum+=1
print(sum)
if __name__ == '__main__':
now=time.time()
l=[]
for i in range(10):
p=Process(target=func1)
p.start()
l.append(p)
for p in l:
p.join()
end=time.time()
print('执行时间为:',end-now)
(2) 计算密集型——采用多线程
执行时间为: 19.56025981903076
from threading import Thread
import time
def func1():
sum=0
for i in range(100000000):
sum+=1
print(sum)
if __name__ == '__main__':
now=time.time()
l=[]
for i in range(10):
p=Thread(target=func1)
p.start()
l.append(p)
for p in l:
p.join()
end=time.time()
print('执行时间为:',end-now)
(3) IO密集型——采用多进程
执行时间为: 3.3192360401153564
from multiprocessing import Process
import time
def func1():
time.sleep(2)
if __name__ == '__main__':
now=time.time()
l=[]
for i in range(100):
p=Process(target=func1)
p.start()
l.append(p)
for p in l:
p.join()
end=time.time()
print('执行时间为:',end-now)
(4)IO密集型——采用多线程
执行时间为: 2.009773015975952
from threading import Thread
import time
def func1():
time.sleep(2)
if __name__ == '__main__':
now=time.time()
l=[]
for i in range(100):
p=Thread(target=func1)
p.start()
l.append(p)
for p in l:
p.join()
end=time.time()
print('执行时间为:',end-now)
总结
对于IO密集型应用,即便有GIL存在,由于IO操作会导致GIL释放,其他线程能够获得执行权限。由于多线程的通讯成本低于多进程,因此偏向使用多线程。
对于计算密集型应用,由于CPU一直处于被占用状态,GIL锁直到规定时间才会释放,然后才会切换状态,导致多线程处于绝对的劣势,此时可以采用多进程+协程。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号