


Linux的shell,三剑客日志分析
一、shell
1、Linux Shell 是一种命令行解释器,也被称为shell或命令行界面(CLI).用于与Linux操作系统进行交互。它是用户与操作系统之间的接口。允许用户执行各种命令和操作。
2、Linux shell 提供了许多内置命令和功能,同时还支持脚本编程。使用户可以将一系列命令组合成脚本文件,以自动化任务和批处理操作。
3、Shell 脚本可以包含条件语句、循环、函数等常见的编程元素,使用户能够更加高效完成重复性的操作。
二、awk的使用
1、awk简介
AWK 是一种处理文本文件的语言,是一个强大的文本分析工具。之所以叫 AWK 是因为其取了三位
创始人 Alfred Aho,Peter Weinberger, 和 Brian Kernighan 的 Family Name 的首字符。
linux中三剑客功能:
grep:过滤文本
sed:修改文本
awk:处理文本
2、awk [参数] [处理内容] [操作对象]
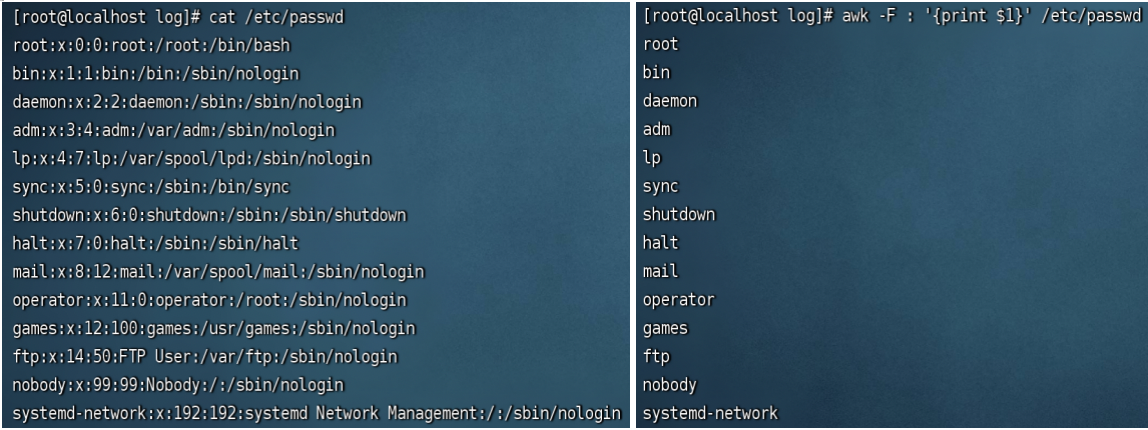
例1:awk -F : '{print $1}' /etc/passwd 打印以冒号分割文本passwd第一列内容
参数 -F 制定文本分割符(默认空格作为分割符),以冒号作为分割符 -F :
处理内容 '{print $NF}' ,print 打印、$ 变量名、NF 变量值(NF为0打印全部,为1打印第一列)
原文件 处理后的内容
例2: awk -F : '/^root/{print $0}' /etc/passwd 打印包含root的整列内容,^通配符,0表示整列内容
![]()
例3:awk '{print $1}' access.log | wc -l 统计第一列ip的数据条数(默认空格分割)
![]()
wc 命令用于计算字数。
参数: -c,bytes:统计字节数。
-m,chars:统计字符数。
-w,words:统计字数。
-l,lines:统计行数。
-L,max-line-length:统计最长行的长度。
例4:awk '{print $1}' access.log | uniq | wc -l 统计第一列ip的数据条数,去除重复的(默认空格分割)
uniq 检查文本重复出现的行列
![]()
三、sed的使用
sed是一种流编辑器,它一次处理一行内容。处理时,把当前处理的行存储在临时缓冲区中,称为“模式空间”,
接着用sed命令处理缓冲区中的内容,处理完成后,把缓冲区的内容送往屏幕,接着处理下一行,这样不断重复,直
到文件末尾。文件内容并没有改变,除非使用重定向存储输出。
创建一个sed.txt文件
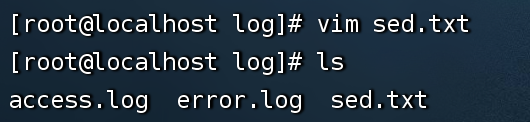
1、sed使用
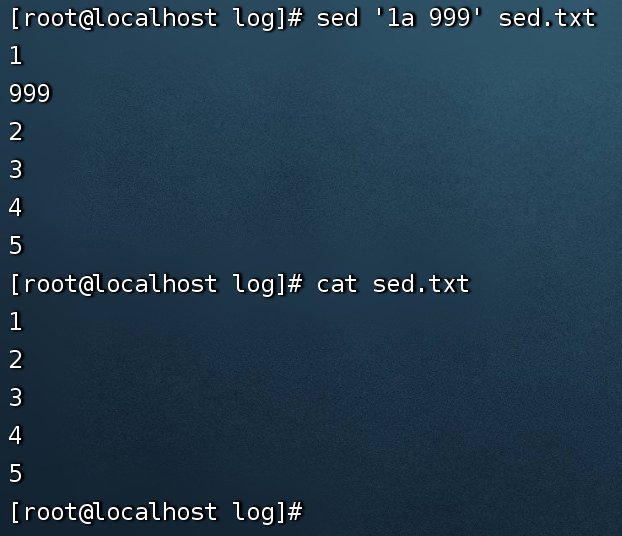
例1:sed '1a 999' sed.txt 在文本文件sed.txt第一行下面新增999
1a表示第一行后(亦即是加在第二行)加上
注意:sed.txt内容本身没有变
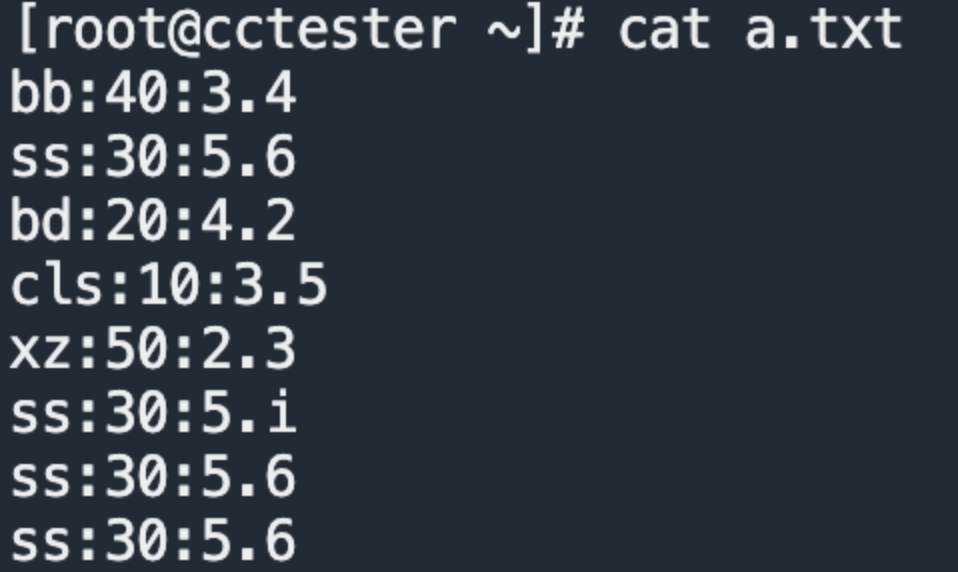
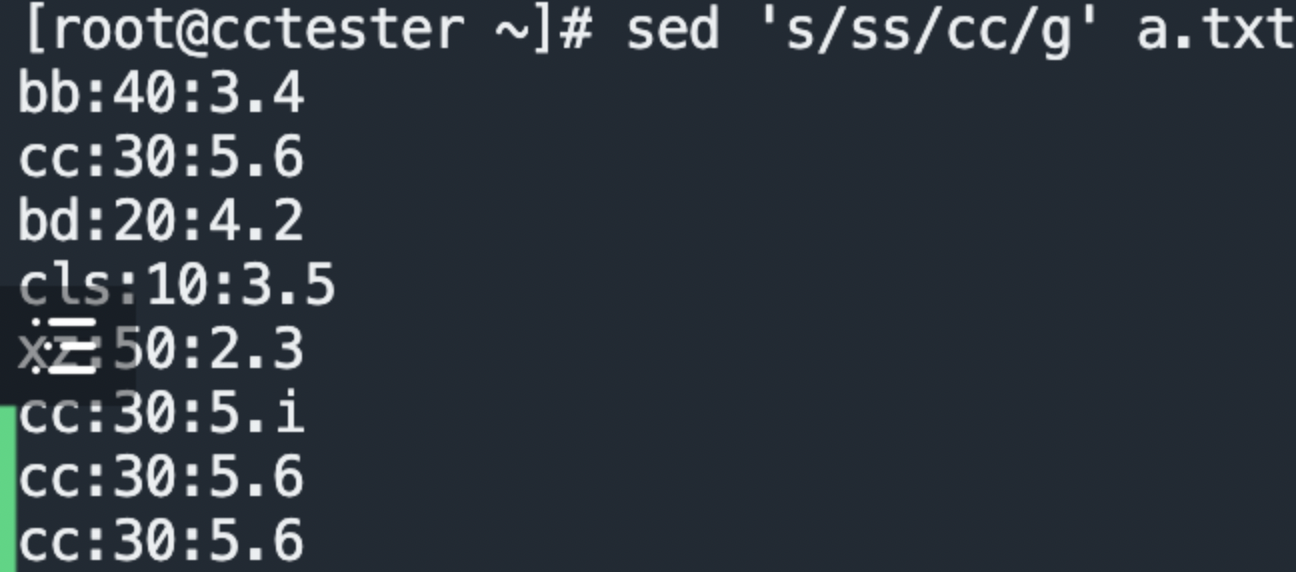
例2: sed 's/ss/cc/g' a.txt 把ss替换成cc
sed 's/要被取代的字串/新的字串/g'
四、cat使用
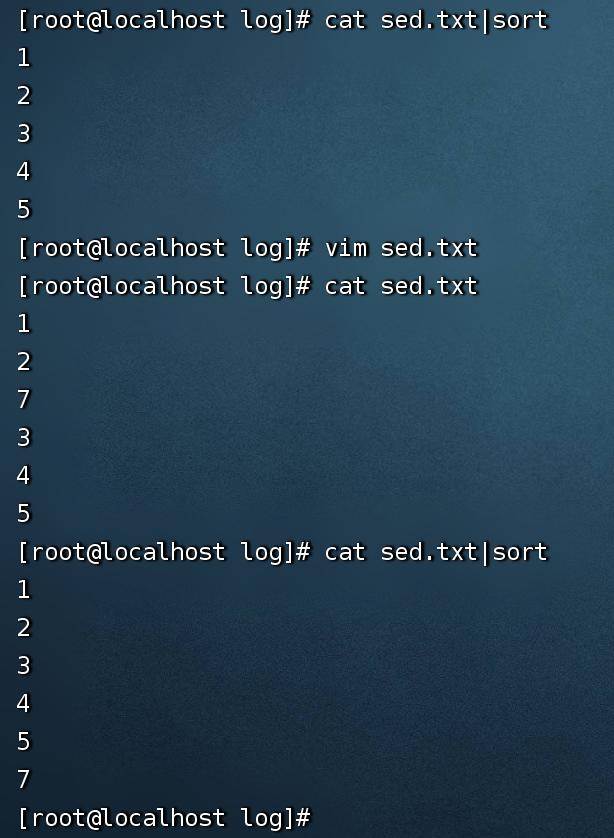
例1:cat sed.txt|sort 给文件内容排序
cat sed.txt|sort -r 给文件反向排序
注意:sed.txt内容本身没有变
五、sort使用
sort命令将文件进行排序,并将排序的结果标准输出。
sort
-r:表示降序排列,默认是升序
-n:按数值大小排序
-t:设置排序时所用的分隔字符,sort命令默认字段分隔符为空格和Tab
-k:指定需要排序的列
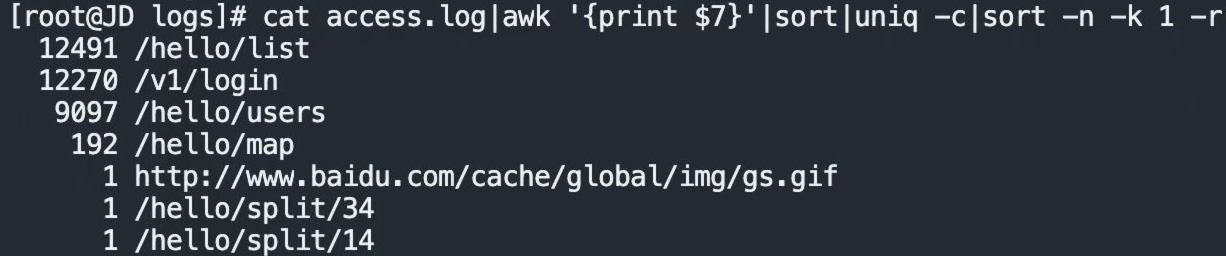
例1:cat access.log|awk '{print $7}'|sort|uniq -c|sort -n -k 1 -r
例2:sort -t : -nrk3 a.txt. 设置排序的分隔字符,第三列按数值大小倒序

六、uniq用法
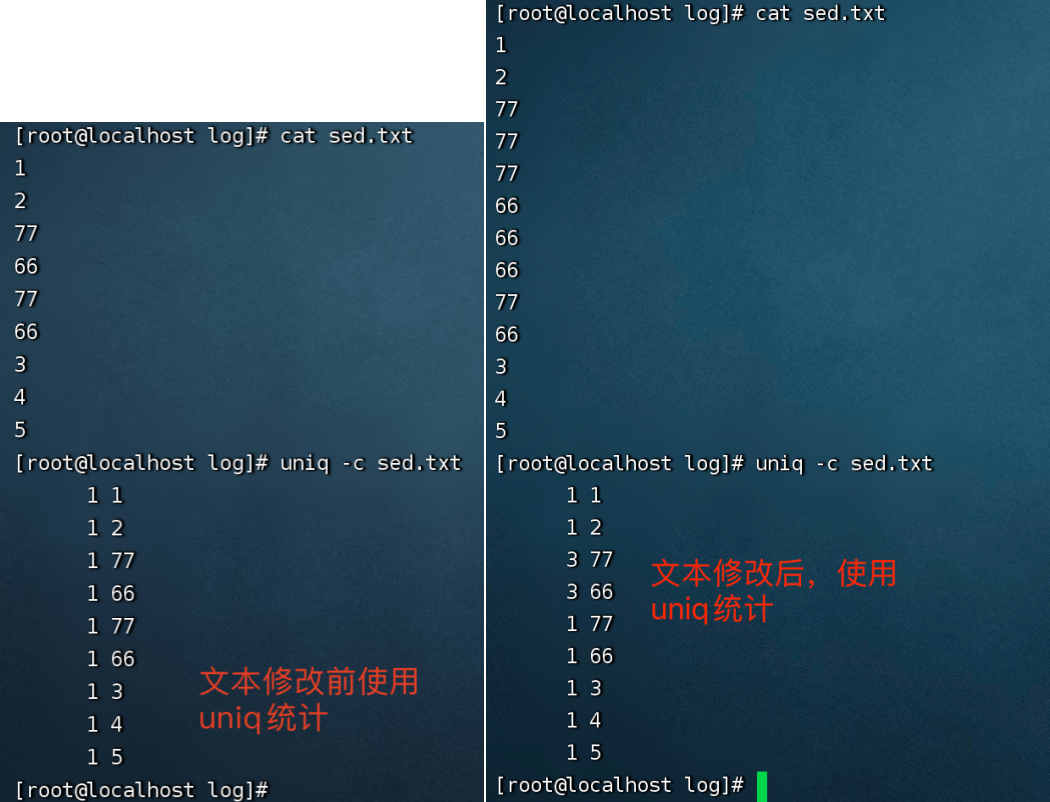
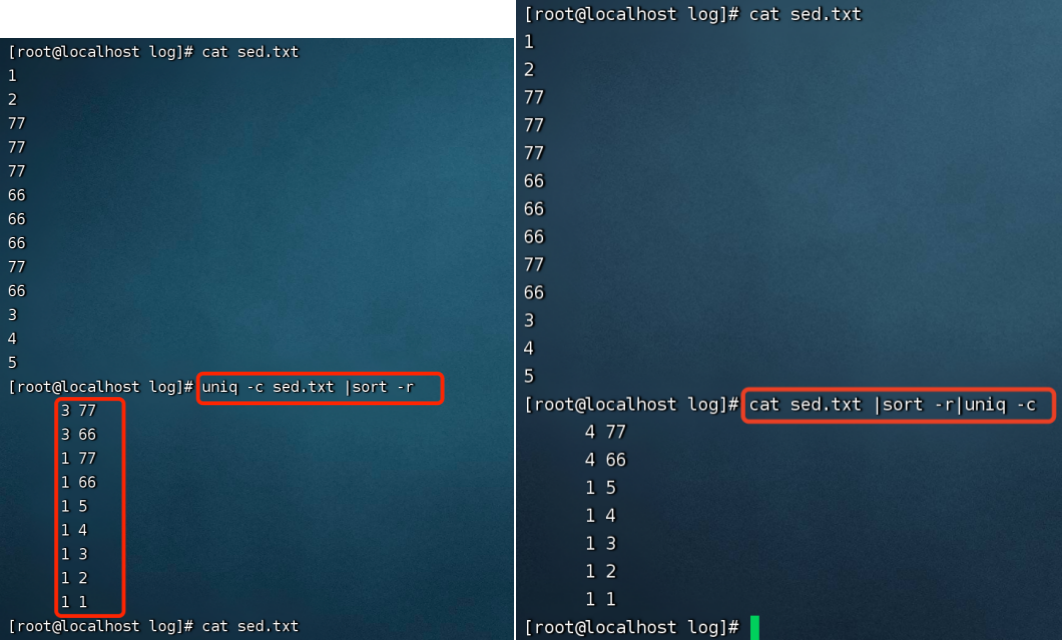
1、uniq -c sed.txt
-c: 打印每行出现的次数
-d:打印重复出现的行
结论:uniq只会按照连续(或相邻的)重复值去重统计
2、解决连续重复的去重统计问题
uniq -c sed.txt | sort -r 排序后去重
问题:还是有重复的,并没有做到排序去重
改变命令执行顺序:cat sed.txt | sort -r | uniq -c 先查看sed.txt,排序,去重
七、查看处理日志
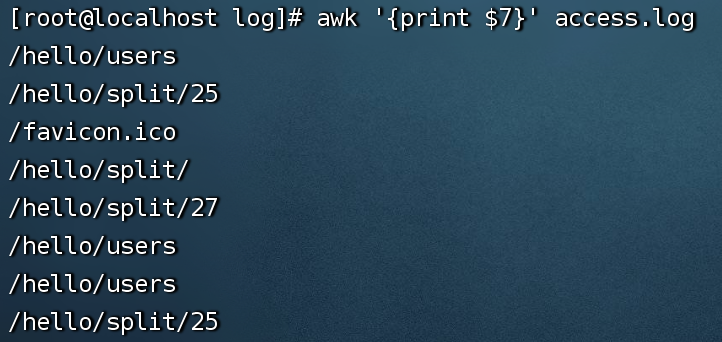
1、例1:awk '{print $7}' /data/nginx/log/access.log 查看访问了那些接口
cat access.log | awk '{print $7}' | sort -r | uniq -c 查看日志第7列降序排列,打印每行出现的次数
cat access.log | awk '{print $7}' | sort | uniq -c |sort -nrk 1 查看日志第7列降序排列,打印每行出现的次数,按照第一列数值大小降序排列
cat access.log | awk '{print $7}' | sort | uniq -c |sort -nrk 1 | awk '$1 >20 {print}' 查看日志第7列升序,打印每行出现的次数,按照第一列数值大小降序排列并且出现次数大于20
2、echo 0>access.log 清空日志
3、tail -n 300 -f access.log 动态查看300行日志
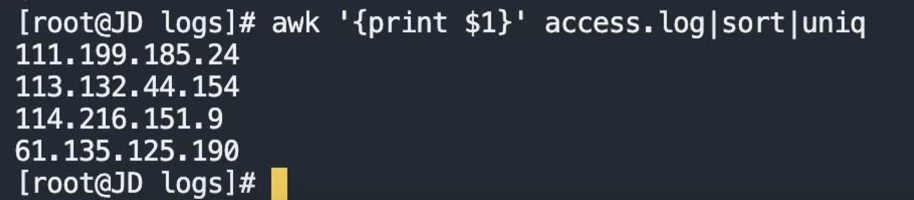
4、awk '{print $7}' /data/nginx/log/access.log|sort|uniq 排序去重查找日志access.log里的ip
awk '{print $7}' /data/nginx/log/access.log|sort|uniq|wc -l 排序去重查找日志access.log里的ip的个数
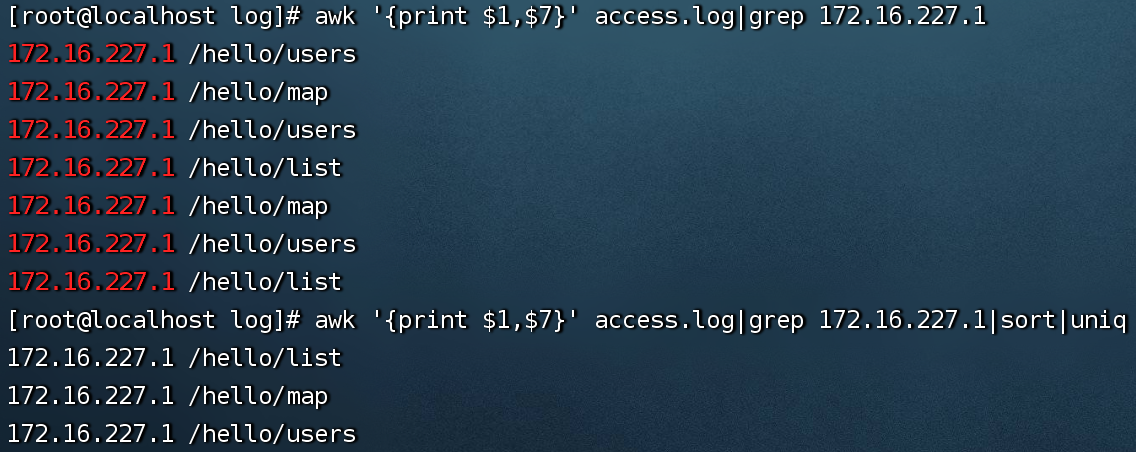
5、awk '{print $1,$7}' access.log|grep 172.16.227.1 查找某个ip访问接口了那些接口
awk '{print $1,$7}' access.log|grep 172.16.227.1|sort|uniq 进一步排序去重(注意uniq去重之前要先排序)
6、awk '{print $4,$1,$7}' access.log|grep 14/Aug/2022:09:37:13 查找特定时间的访问ip和接口
awk '{print $4,$1,$7}' access.log|grep 14/Aug/2022:09:37:13|wc -l 查找特定时间的访问量
awk '{print $4,$1,$7}' access.log|grep 14/Aug/2022:09:37:13|awk '{print $2}'|sort|uniq|wc -l 特定时间访问量去重

实际压力测试过程中不需要统计不同ip不同访问次数,因为在访问过程中的真实压力是真实的、存在的,不会因为jvm、redis对服务器没有压力
7、接口统计小工具
1 import matplotlib.pyplot as plt 2 3 # 给定字段和对应的value数值 4 labels = ['users', 'queryOrderDetail', 'queryOrderHeader', 'headerPagelist','orderNumber','login','list'] 5 sizes = [6556, 3696, 1933, 809, 808,567,501] 6 7 # 计算总值 8 total = sum(sizes) 9 10 # 计算每个字段所占比例 11 percentages = [size / total for size in sizes] 12 13 # 绘制饼图 14 fig, ax = plt.subplots() 15 ax.pie(percentages, labels=labels, autopct='%1.1f%%', startangle=90) 16 ax.axis('equal') # 保持饼图为圆形 17 18 plt.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号