
day2021_9_19
今日内容
-
西瓜书第三章与第四章的内容学习
-
第三章线性模型:
- 线性回归
- 对数几率回归
- 线性判别分析(LDA)
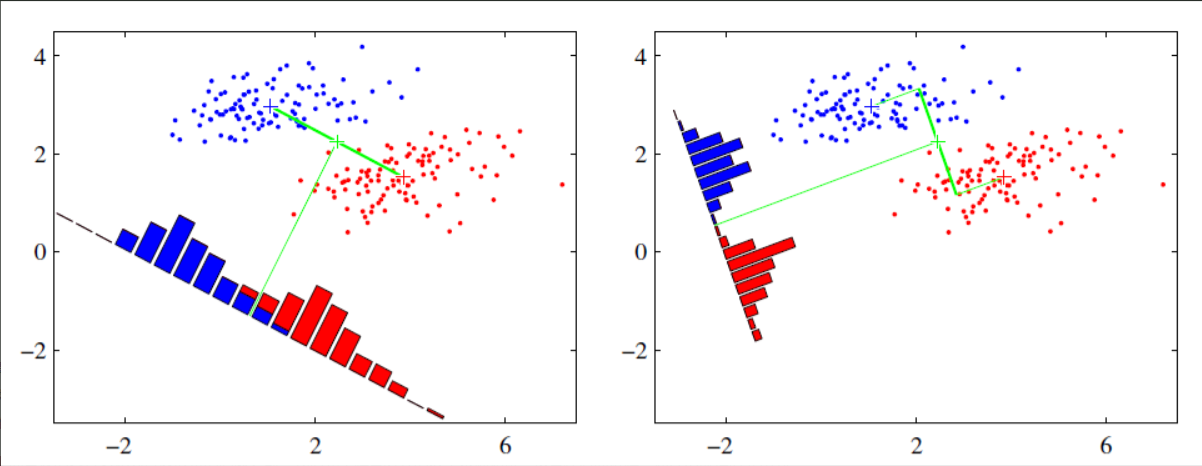
给定训练集,设法将训练集投影到一条直线上,使得同类的投影点尽可能近(同类投影点的协方差尽可能小),不同类的尽可能远(不同类的投影点集合的中心距离相差尽可能远),达到分类的目的。下图中左图的投影线就不合格,右图效果较好![]()
- 多分类学习:
可以由二分类推广到多分类。有一对一、一对多、多对多三种拆分策略
如给定数据集D={(x1,y1),(x2,y2),(x3,y3),...,(xm,ym),},yi(即类别)有N种
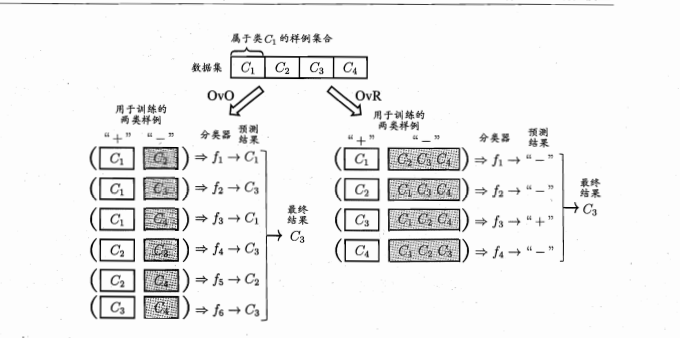
OvO将N个类别两两匹配,从而有N(N-1)/2个二分类任务,最后就会产生N(N-1)/2个分类结果,再把被预测得最多得类别作为最终的分类结果![]()
OvR则是将N个类别中的一个类作为正例,其他为反例,训练N个分类器。测试时若只有一个分类器预测为正类,则对应的类别标记作为最终的分类结果,若有多个,则需要考虑分类器的预测置信度,选择最大的作为结果
MvM将若干类作为正例,若干个作为反例
5. 类别不平衡问题:
分类任务中,不同类别的训练样例数目差距很大,就会遇到这种情况。 -
第四章 决策树
- 决策树构建的目的:随着决策树深度的增加,节点的熵迅速地降低,得到一颗高度最矮的树
** 为什么高度要最矮**
决策树深度的增加,分类就会越明细,很容易产生过拟合现象。可以通过剪枝操作防止过拟合 - 非叶子结点的划分选择:
可以通过信息熵(ID3)、基尼指数、信息增益、信息增益率(CD4.5)等划分属性 - 剪枝处理:预剪枝与后剪枝
** 4. 连续值与缺失值的处理方法**
- 决策树构建的目的:随着决策树深度的增加,节点的熵迅速地降低,得到一颗高度最矮的树
遇到的问题
- 公式推导容易遗忘,但是能够记住概念,以后复习拿起的时候会比较快,只能等到后期慢慢加强
明日计划
- 继续西瓜书后面章节的学习

 浙公网安备 33010602011771号
浙公网安备 33010602011771号