

大数据4.1 - Flume整合案例+Hive数据仓
1.1 使用Flume收集数据落地HDFS
1.1.1 实现方案

log4j和flume整合
配置log4j.properties
log4j.rootLogger = info,stdout,flume log4j.appender.stdout = org.apache.log4j.ConsoleAppender log4j.appender.stdout.Target = System.out log4j.appender.stdout.layout = org.apache.log4j.PatternLayout log4j.appender.stdout.layout.ConversionPattern = %m%n # appender flume log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender log4j.appender.flume.Hostname = hadoop01 log4j.appender.flume.Port = 22222 log4j.appender.flume.UnsafeMode = true
配置flume-jt.properties
#命名Agent a1的组件 a1.sources = r1 a1.sinks = k1 a1.channels = c1 #描述/配置Source a1.sources.r1.type = avro a1.sources.r1.bind = hadoop01 a1.sources.r1.port = 22222 #描述Sink a1.sinks.k1.type = hdfs a1.sinks.k1.hdfs.path = hdfs://hadoop01:9000/jt/data #描述内存Channel a1.channels.c1.type = memory a1.channels.c1.capacity = 1000 a1.channels.c1.transactionCapacity = 100 #为Channle绑定Source和Sink a1.sources.r1.channels = c1 a1.sinks.k1.channel = c1
复制依赖jar文件
进入共享目录
cd /usr/local/src/hadoop/hadoop-2.7.1/share/hadoop/common
复制文件
cp *.jar /usr/local/src/flume/apache-flume-1.6.0-bin/lib
cd /usr/local/src/hadoop/hadoop-2.7.1/share/hadoop/common/lib
cp commons-configuration-1.6.jar /usr/local/src/flume/apache-flume-1.6.0-bin/lib
cp hadoop-auth-2.7.1.jar /usr/local/src/flume/apache-flume-1.6.0-bin/lib
cp htrace-core-3.1.0-incubating.jar /usr/local/src/flume/apache-flume-1.6.0-bin/lib
cp commons-io-2.4.jar /usr/local/src/flume/apache-flume-1.6.0-bin/lib
cd /usr/local/src/hadoop/hadoop-2.7.1/share/hadoop/hdfs
cp hadoop-hdfs-2.7.1.jar /usr/local/src/flume/apache-flume-1.6.0-bin/lib
否则启动和运行时会报错:
java.lang.NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType
java.io.IOException: No FileSystem for scheme: hdfs
启动Agent
[root@localhost conf]# ../bin/flume-ng agent -c ./ -f ./flume-jt.properties -n a1 -Dflume.root.logger=INFO,console &
#注意在conf配置文件目录下运行
访问数据
启动项目
访问埋点页面
在控制台打印数据
1.1.7 以及flume会写数据到HDFS上
1.1.8 查看下数据
注意:这不是乱码,是数据编码采用了GBK,数据本身没问题。
1.2 Apache Hive
1.2.1 概述
1.2.1.1 Hadoop分布式计算的缺点
开发调试繁琐,周期长。客户需要立即出结果,可开发MR非常耗时,难写
需要对Hadoop底层工作原理及api熟悉,才能开发出比较高质量的分布式程序
用java语言开发,其它语言支持不够友好
1.2.1.2 概述
Hive起源于Facebook,它是建立在 Hadoop 上的数据仓库基础构架。它提供了一系列的工具,可以用来进行数据提取转化加载(ETL),这是一种可以存储、查询和分析存储在 Hadoop 中的大规模数据的机制。Hive 定义了简单的类 SQL 查询语言,称为 HQL,它允许熟悉 SQL 的用户查询数据。同时,这个语言也允许熟悉 MapReduce 开发者的开发自定义的 mapper 和 reducer 来处理内建的 mapper 和 reducer 无法完成的复杂的分析工作。
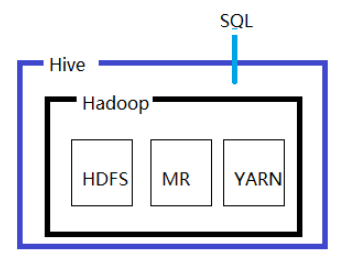
1.2.1.3 基本概念
Hive 中所有的数据都存储在 HDFS 中,Hive 中包含以下数据模型:表(Table),外部表(External Table),分区(Partition),桶(Bucket)。
Hive 中的 Table 和数据库中的 Table 在概念上是类似的,每一个 Table 在 Hive 中都有一个相应的目录存储数据。
artition 对应于数据库中的 Partition 列的密集索引,但是 Hive 中 Partition 的组织方式和数据库中的很不相同。在 Hive 中,表中的一个 Partition 对应于表下的一个目录,所有的 Partition 的数据都存储在对应的目录中。
Buckets 对指定列计算 hash,根据 hash 值切分数据,目的是为了并行,每一个 Bucket 对应一个文件。
External Table 指向已经在 HDFS 中存在的数据,可以创建 Partition。它和 Table 在元数据的组织上是相同的,而实际数据的存储则有较大的差异。
1.2.1.4 应用场景
Hive 构建在基于静态批处理的Hadoop 之上,Hadoop 通常都有较高的延迟并且在作业提交和调度的时候需要大量的开销。例如,Hive 在几百MB 的数据集上执行查询一般有分钟级的时间延迟。因此,Hive 并不适合那些需要低延迟的应用,例如,联机事务处理(OLTP)。
Hive 查询操作过程严格遵守Hadoop MapReduce 的作业执行模型,Hive 将用户的HiveQL 语句通过解释器转换为MapReduce 作业提交到Hadoop 集群上,Hadoop 监控作业执行过程,然后返回作业执行结果给用户。Hive 的最佳使用场合是大数据集的批处理作业,例如,网络日志分析。
Hive 在加载数据过程中不会对数据进行任何的修改,只是将数据移动到HDFS 中Hive 设定的目录下,因此,Hive 不支持对数据的改写和添加,所有的数据都是在加载的时候确定的。
1.2.1.5 特点
支持索引,加快数据查询。
不同的存储类型,例如,纯文本文件、HBase中的文件。
将元数据保存在关系数据库中,大大减少了在查询过程中执行语义检查的时间。
可以直接使用存储在Hadoop 文件系统中的数据。
内置大量用户函数UDF 来操作时间、字符串和其他的数据挖掘工具,支持用户扩展UDF 函数来完成内置函数无法实现的操作。
类SQL 的查询方式,将SQL 查询转换为MapReduce 的job 在Hadoop集群上执行。
不支持在线事务处理,也不支持行级的插入、更新和删除。
1.2.2 安装配置
1.2.2.1 Hadoop集群规划
Hive是在Hadoop的基础上,所以先需要安装Hadoop集群。
|
主机名 |
IP |
安装的软件 |
进程 |
|
hadoop01 |
192.168.163.129 |
jdk、hadoop |
namenode resourcemanager |
|
hadoop02 |
192.168.163.130 |
jdk、hadoop |
datanode secondnamenode |
|
hadoop03 |
192.168.163.131 |
jdk、hadoop |
datanode |
1.2.2.2 Hive安装配置
cd /usr/local/src
mkdir hive #创建目录
cd hive #进入目录
apache-hive-1.2.0-bin.tar.gz #上传,注意和Hadoop的版本对应
tar -xvf apache-hive-1.2.0-bin.tar.gz #解压,基于jdk
cd apache-hive-1.2.0-bin/bin/ #进入目录
1.1.1.1 启动Hadoop集群
cd /usr/local/src/hadoop/hadoop-2.7.1/sbin #进入hadoop目录
./stop-dfs.sh #停止之前的HDFS服务
start-all.sh #启动hadoop服务
jps #启动4个服务NameNode,DataNode,SecondaryNameNode,ResourceManager
1.1.1.2 运行Hive
./hive #启动hive,必须有jdk+Hadoop
1.2.3 基础操作
1.2.3.1 常见命令
hive> show databases; #查看数据库,默认只有default库
hive> use default; #打开默认数据库
hive> create table tb_teacher(id int,name string); #建立表
hive> exit; #退出hive
hive> create database jtdb; #创建库
hive> use jtdb; #打开库
hive> create table tb_user(id int, name string); #创建表
hive> show tables; #查看所有表
hive> desc tb_user; #查看表结构
hive> show create table tb_user; #查看创建表语句
OK
执行结果:
CREATE TABLE `tb_user`(
`id` int,
`name` string)
ROW FORMAT SERDE
'org.apache.hadoop.hive.serde2.lazy.LazySimpleSerDe'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://192.168.163.129:9000/user/hive/warehouse/jtdb.db/tb_user'
TBLPROPERTIES (
'transient_lastDdlTime'='1511504310')
Time taken: 0.362 seconds, Fetched: 13 row(s)
1.2.3.2 查看数据库
可以看到jtdb.db是一个目录,tb_user表也是个目录。
1.2.3.3 插入数据
插入单条
insert into tb_user values(1, ‘tony’);
1.2.3.4 批量载入数据
数据文件user.txt
1 严嵩
2 徐阶
3 高供
4 张居正
批量插入数据
load data local inpath '/usr/local/src/user.txt' into table tb_user;
执行结果
Loading data to table jtdb.tb_user
Table jtdb.tb_user stats: [numFiles=1, totalSize=38]
OK
Time taken: 0.744 seconds
hive> select * from tb_user;
OK
NULL NULL
NULL NULL
NULL NULL
NULL NULL
神奇怎么都是NULL呢?如果说没有插入那怎么会显示的刚好4条呢?
先看看数据
可以看出,其实表下面的数据就是上传的文件。
Hive中要指定txt文件中列的分隔符:
create table tb_user2 (id bigint, name string) row format delimited fields terminated by ' ';
load data local inpath '/usr/local/src/user.txt' into table tb_user2;
1.2.3.5 给同一个表再次载入数据
编辑user2.txt,修改数据为拼音,然后载入
load data local inpath '/usr/local/src/user3.txt' into table tb_user2;
select * from tb_user2;
查询数据发现都在
hive> select * from tb_user2;
OK
1 严嵩
2 徐阶
3 高供
4 张居正
Time taken: 0.338 seconds, Fetched: 8 row(s)
1.2.3.6 小结
l hive中的数据库对应hdfs中/user/hive/warehouse目录下以.db结尾的目录
l hive中的表对应hdfs/user/hive/warehouse/[db目录]中的一个目录
l hive中的数据对应当前hive表对应的hdfs目录中的文件
l 执行select count(*) from tb_user; 可以看出hive会将命令转换为mapreduce执行
l 行级别的增删改是不允许的
可以看到Hive就是把MR(MapReduce)封装了下,可以使用类似SQL语句的形式来操作Hadoop,直接使用HDFS。
1.2.4 常见问题
1.2.4.1 查看日志
有错误时hive不在console控制台显示,这时就需要查看日志。
在hive/conf/ hive-log4j.properties 文件中记录了Hive日志的存储情况,
默认的存储情况:
hive.root.logger=WARN,DRFA
hive.log.dir=/tmp/${user.name} # 默认的存储位置
hive.log.file=hive.log # 默认的文件名
Job日志又存储在什么地方呢 ?
//Location of Hive run time structured log file
HIVEHISTORYFILELOC("hive.querylog.location", "/tmp/" + System.getProperty("user.name")),
默认存储与 /tmp/{user.name}目录下。
查看日志
cd /tmp/root
tail –f hive.log
1.2.4.2 Hive假死
执行其他hql(select * from tb_user)顺利执行;但只要执行需要mr的hql(select * from tb_user)就假死不动,查看日志如红框异常。什么原因呢?
Hive是运行在Hadoop集群上的,集群的计算框架配置为了yarn,所以hdfs和yarn都处于运行中才可以。执行jps必须看到ResourceManager才可以。没有就单独启动其服务。
因为我们分布式集群配置在hadoop03上启动资源管理服务,所以在hadoop03启动
一路回车,yes,密码root,最终jps看到ResourceManager。再执行select count(*) from tb_user,虽然还是比较慢,但可以顺利执行完毕。
1.2.4.3 Hive启动报错$HADOOP_HOME
Cannot find hadoop installation: $HADOOP_HOME or $HADOOP_PREFIX must be set or hadoop must be in the path
解决办法:
指定HADOOP_HOME路径
cd /usr/local/src/hive/apache-hive-1.2.0-bin/conf
cp hive-env.sh.template hive-env.sh
增加HADOOP_HOME
HADOOP_HOME=/usr/local/src/hadoop/hadoop-2.7.1
1.2.4.4 Hive启动报错Safe mode
Hadoop在启动时有个安全模式,其在启动时有些工作要做,元数据的处理,DataNode的等待等过程。需要一段时间,遇到时需要等一段时间,耐心稍微等一会。过会自动就会好。
如果长时间还报错,还在安全模式。可以手工设置退出安全模式。
[root@hadoop01 bin]# pwd
/usr/local/src/hadoop/hadoop-2.7.1/bin
[root@hadoop01 bin]# ./hadoop dfsadmin -safemode leave
DEPRECATED: Use of this script to execute hdfs command is deprecated.
Instead use the hdfs command for it.
Safe mode is OFF
[root@hadoop01 bin]#
参数value的说明如下:
l enter - 进入安全模式
l leave - 强制NameNode离开安全模式
l get - 返回安全模式是否开启的信息
l wait - 等待,一直到安全模式结束
1.2.5 Derby数据库元数据丢失问题及解决办法
1.2.5.1 ApacheDerby的问题
./hive show databases;操作正常,bin/hive 查询会发现之前的表没有了,为什么呢?
hive会把这些信息存放在传统的关系型数据库中。如果不指定它会存放在默认的数据库,它是传统file文件类型数据库derby。它有个缺点,只认当前目录中的metastore_db。所以运行不在hive/bin目录中时,就无法读取到metastrom_db文件,从而之前的库和表都不见了。
所以要注意,换了路径后会新产生metastore_db,从而信息丢失。这是derby数据库的问题。幸好hive还支持另一种关系型数据库mysql。
1.2.5.2 安装MySQL
cd /usr/local/src #进入目录
mkdir mysql #创建目录
cd mysql #进入目录
上传文件到目录中
MySQL-server-5.6.29-1.linux_glibc2.5.x86_64.rpm
MySQL-client-5.6.29-1.linux_glibc2.5.x86_64.rpm
rpm -qa |grep -i mysql #查询是否有mysql
#查询mysql系统中已经有旧的mysql版本:mysql-libs-5.1.71-1.el6.x86_64
rpm -ev --nodeps mysql-libs-5.1.71-1.el6.x86_64 #删除旧的版本
groupadd mysql #增加用户组
useradd –r –g mysql mysql #增加用户mysql,加入用户组
chown -R mysql:mysql /usr/local/mysql/data #设置数据存放目录的写权限
rpm -ivh MySQL-server-5.6.29-1.linux_glibc2.5.x86_64.rpm #服务端
rpm -ivh MySQL-client-5.6.29-1.linux_glibc2.5.x86_64.rpm #客户端
1.2.5.3 初次配置MySQL重设密码
cd /etc/init.d #进入到mysql执行目录
#默认mysql不允许远程访问,所以要以安全模式启动,允许远程访问
mysqld_safe --user=mysql --skip-grant-tables --skip-networking &
执行结果:
[1] 4469
[root@hadoop01 init.d]# 171220 18:23:27 mysqld_safe Logging to '/var/lib/mysql/hadoop01.err'.
171220 18:23:27 mysqld_safe Starting mysqld daemon with databases from /var/lib/mysql
修改密码:
mysql -u root mysql #以root账号登录,访问mysql数据库
#修改root账号的密码
mysql> update user set password=PASSWORD('root') where user='root';
mysql> flush privileges; #更新权限
mysql> quit #退出
service mysql stop #关闭安全模式的服务
service mysql start #启动正常的服务
mysql -u root –proot #连接进入mysql
ps -ef|grep mysql #查看mysql的安装运行路径
1.2.5.4 查看mysql信息
mysql> \s
--------------
mysql Ver 14.14 Distrib 5.6.29, for Linux (x86_64) using EditLine wrapper
Connection id: 6
Current database:
Current user: root@localhost
SSL: Not in use
Current pager: stdout
Using outfile: ''
Using delimiter: ;
Server version: 5.6.29 MySQL Community Server (GPL)
Protocol version: 10
Connection: Localhost via UNIX socket
Server characterset: latin1
Db characterset: latin1
Client characterset: utf8
Conn. characterset: utf8
UNIX socket: /var/lib/mysql/mysql.sock
Uptime: 2 hours 16 min 52 sec
Threads: 2 Questions: 42 Slow queries: 0 Opens: 67 Flush tables: 1 Open tables: 60 Queries per second avg: 0.005
1.2.5.5 修改元数据存储到MySQL中
cd /usr/local/src/hive/apache-hive-1.2.0-bin/conf
cp hive-default.xml.template hive-site.xml #复制模板文件改名
模板中3000多行都是默认值,既然默认值都可以删除,只留下数据库配置
hive-site.xml
<?xml version="1.0" encoding="UTF-8" standalone="no"?>
<?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
<configuration>
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop01:3306/hive?createDatabaseIfNotExist=true</value>
</property>
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>root</value>
</property>
</configuration>
此时如果启动hive会报两个错误:
1、 找不到数据库驱动jar包
2、 数据库默认不允许访问,必须开放远程访问权限
上传mysql驱动包到指定目录
/usr/local/src/hive/apache-hive-1.2.0-bin/lib
mysql-connector-java-5.1.32.jar
mysql –uroot –proot
#授权开启远程访问
grant all privileges on *.* to 'root'@'%' identified by 'root' with grant option;
注意:如果上面语句出错,提示必须先set password,那执行下面语句
set password = PASSWORD('root');
flush privileges; #更新权限
如果上面修改后还提示权限错误,修改指定机器
grant all privileges on *.* to 'root'@'hadoop01' identified by 'root' with grant option;
flush privileges; #更新权限
1.2.5.6 创建数据
cd /usr/local/src/hive/apache-hive-1.2.0-bin/bin #进入hive目录
hive> create database jtdb; #创建jtdb数据库
hive> use jtdb; #打开数据库
hive> create table tb_user(id int,name string); #建立tb_user表
1.2.5.7 Derby的问题得到解决
cd /usr/local/src/hive/apache-hive-1.2.0-bin/bin #进入目录
/.hive #当前目录下执行
cd /usr/local/src/hive/apache-hive-1.2.0-bin #进入目录
bin/hive #其他目录执行
hive> show databases;
执行结果:
OK
default
jtdb
Time taken: 0.828 seconds, Fetched: 2 row(s)
可以看到解决了Derby数据库元数据的丢失问题。
1.2.6 常见问题
1.2.6.1 密码过期问题
报错:
ERROR 1862 (HY000): Your password has expired. To log in you must change it using a client that supports expired passwords.
解决办法:
use mysql
select * from mysql.user where user='root' \G
update user set password_expired='N' where user='root';
flush privileges;
quit;
1.2.6.2 Connection refused
报错:
Hive出现Caused by: java.net.ConnectException: Connection refused
解决办法:
查看进程jps,要看到4个hadoop的进程
jps #启动4个服务NameNode,DataNode,SecondaryNameNode,ResourceManager
1.2.6.3 Hadoop namenode无法启动
执行start-all.sh的时候发现JPS一下namenode没有启动,每次开机都得重新格式化一下namenode才可以。其实问题就出在tmp文件,默认的tmp文件每次重新开机会被清空,与此同时namenode的格式化信息就会丢失,于是我们得重新配置一个tmp文件目录。首先在home目录下建立一个hadoop_tmp目录
sudo mkdir /usr/local/src/hadoop/hadoop-2.7.1/hadoop_tmp
然后修改hadoop/conf目录里面的core-site.xml文件,加入以下节点:
<property>
<name>hadoop.tmp.dir</name>
<value>/usr/local/src/hadoop/hadoop-2.7.1/hadoop_tmp</value>
</property>
重新格式化Namenode
cd /usr/local/src/hadoop/hadoop-2.7.1/bin
hadoop namenode -format
然后启动hadoop
cd /usr/local/src/hadoop/hadoop-2.7.1/sbin
start-all.sh
执行下jps命令就可以看到NameNode了。
1.2.7 元数据库
1.2.7.1 启动hive后查看mysql数据库
1.2.7.2 数据库DBS
两个数据库default和jtdb
1.2.7.3 表TBLS
数据库表
有个很关键的字段TBL_TYPE表的类型叫MANAGED_TABLE,叫“内部表”
1.2.7.4 列COLUMNS_V2
数据库表的字段
1.2.7.5 存储位置SDS
记录表所在的位置。CD_ID表的编号,LOCATION HDFS中的位置
1.3 外部表
1.3.1 外部表概念
内部表MANAGED_TABLE,它是先有的表,后有的数据。但实际工作中,往往我们是先有数据,然后利用hive去处理这些数据。比如flume,flume收集的信息已经落在HDFS上了。某天我们突然想分析这些数据了。这样的情况下就先有了数据,后要创建表。那这些表就叫外部表。
那外部表怎么产生呢?
先上传文件到HDFS上
1.3.2 HDFS添加数据文件
/usr/local/src/book.txt,注意数据以tab为分隔符
1 三国演义
2 水浒传
3 西游记
4 红楼梦
执行命令很慢,执行时稍等片刻
cd /usr/local/src/hadoop/hadoop-2.7.1 #进入hadoop命令
bin/hdfs dfs -mkdir /data #创建data
bin/hdfs dfs -put /usr/local/src/book.txt /data #上传到data目录
bin/hdfs dfs -ls /data #列目录
1.3.3 创建外部表
hive> create external table ext_book(id int, name string) row format delimited fields terminated by '\t' location '/data';
查看TBLS,可以看到我们刚创建的外部表
查看SDS,表的存储位置,就是我们配置的/data
1.3.4 查询外部表数据
hive> select * from ext_book;
OK
1 三国演义
2 水浒传
3 西游记
4 红楼梦
可以看到,所谓外部表就是HDFS某个目录下的文件内容,就是我们刚刚上传的book.txt的内容。
1.3.5 内部表和外部表的差异
当删除内部表时,内部表元数据和数据都会被删除
当删除外部表时,外部表元数据会被删除,数据还存在
删除内部表:
hive> show tables;
OK
ext_book
tb_user
Time taken: 0.164 seconds, Fetched: 2 row(s)
hive> drop table tb_user;
OK
Time taken: 1.155 seconds
hive> show tables;
OK
ext_book
Time taken: 0.145 seconds, Fetched: 1 row(s)
hive>
查看内部表,列表中已经被删除
http://192.168.163.129:50070/explorer.html#/user/hive/warehouse/jtdb.db
删除外部表:
hive> show tables;
OK
ext_book
Time taken: 0.137 seconds, Fetched: 1 row(s)
hive> drop table ext_book;
OK
Time taken: 0.406 seconds
hive> show tables;
OK
Time taken: 0.132 seconds
hive>
查看外部表,列表中的文件还存在
http://192.168.163.129:50070/explorer.html#/data
1.4 分区表
1.4.1 分区表概念
Hive中最重的作用就是创建数据仓库,以不同维度来创建数据集合,本质以空间换时间。而数据库仓库就和分区表紧密相连。这也是Hive区别与其他产品的优势。
对数据进行分区可以提高查询效率。
1.4.1.1 创建单分区表
1.4.1.1.1 创建分区表
hive> create table tb_book(id int,name string) partitioned by (category string) row format delimited fields terminated by '\t';
可见,就是增加了一句partitioned by (category string)。
1.4.1.1.2 准备数据
zh.txt
1 西游记
2 红楼梦
3 三国演义
4 水浒传
jp.txt
1 一休
2 圣斗士
3 灌篮高手
4 犬夜叉
en.txt
1 Pride and Prejudice (傲慢与偏见)
2 Sense and Sensibility (理智与情感)
3 The Great Gatsby(了不起的盖茨比)
上传文件到/usr/local/src目录中
1.4.1.1.3 插入数据
hive> load data local inpath '/usr/local/src/zh.txt' overwrite into table tb_book partition (category='china');
hive> load data local inpath '/usr/local/src/jp.txt' overwrite into table tb_book partition (category='jp');
hive> load data local inpath '/usr/local/src/en.txt' overwrite into table tb_book partition (category='en');
注:insert into并不是hive中标准的用法,而应该用load。
1.4.1.1.4 存放结构
可以看到分区表就多了级目录而已,上传的文件就被放在了对应的目录下,但就因为多了级目录意义就非常重大。我们先继续来看后面总结时再说它的意义。
1.4.1.1.5 查询数据
hive> select * from tb_book;
OK
1 西游记 china
2 红楼梦 china
3 三国演义 china
4 水浒传 china
1 Pride and Prejudice (傲慢与偏见) en
2 Sense and Sensibility (理智与情感) en
3 The Great Gatsby(了不起的盖茨比) en
1 一休 jp
2 圣斗士 jp
3 灌篮高手 jp
4 犬夜叉 jp
Time taken: 0.31 seconds, Fetched: 11 row(s)
可以看到我们的表是两列,在最后又按分类加了一列。
如果整表查询,和以前没什么差别,性能一样。但是如何下面的差就不一样了。
Time taken: 0.31 seconds, Fetched: 11 row(s)
hive> select * from tb_book where category='china';
OK
1 西游记 china
2 红楼梦 china
3 三国演义 china
4 水浒传 china
Time taken: 0.655 seconds, Fetched: 4 row(s)
hive>
大家思考下,这样查询有什么不同?
如果不分区,所有内容zh.txt、jp.txt、en.txt的内容都在一起,而category只是表的一列属性。如果要查china就要所有数据都遍历一遍,要一条一条判断,从中过滤出要的内容。那我们现在做了分区,我们查询条件很特殊,我们是按分区的条件进行查询。那有什么不同。还用遍历那么多数据吗?还要做判断吗?是不直接返回。哪个查询效率高,是不一目了然。分区后查询效率高。
回顾下我们说过的数据库仓库,把数据按不同的维度事先处理,那将来查询时效率是不就高了。按什么维度呢?category,预先处理把数据分到不同分区。
多分区
1.4.1.2 常见错误
For direct MetaStore DB connections, we don’t support retries at the client level.
现象:
在hive中插入数据时提示失败,但是在浏览器中查看时发现数据上传成功了。但在hive中查询表中的数据时,没有显示。
解决办法:
这是由于字符集的问题,需要配置MySQL的字符集:
Mysql> alter database hive character set latin1;
需要保证hive为latin1格式
1.4.1.3 创建多分区表
1.4.1.3.1 创建分区表
hive> create table tb_book2(id int, name string) partitioned by(category string,gender string) row format delimited fields terminated by '\t';
hive> desc tb_book2;
OK
id int
name string
category string
gender string
# Partition Information
# col_name data_type comment
category string
gender string
Time taken: 0.252 seconds, Fetched: 10 row(s)
hive> show create table tb_book2;
OK
CREATE TABLE `tb_book2`(
`id` int,
`name` string)
PARTITIONED BY (
`category` string,
`gender` string)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS INPUTFORMAT
'org.apache.hadoop.mapred.TextInputFormat'
OUTPUTFORMAT
'org.apache.hadoop.hive.ql.io.HiveIgnoreKeyTextOutputFormat'
LOCATION
'hdfs://192.168.163.129:9000/user/hive/warehouse/jtdb.db/tb_book2'
TBLPROPERTIES (
'transient_lastDdlTime'='1514343503')
Time taken: 0.172 seconds, Fetched: 16 row(s)
hive>
1.4.1.3.2 准备数据
将数据先进行分维度,也就是分成多个文件,然后再逐个导入。
zh-male.txt
1 西游记 吴承恩 男 1296
2 红楼梦 曹雪芹 男 1510
3 三国演义 罗贯中 男 1330
4 水浒传 施耐庵 男 1715
jp-male.txt
1 一休 大川久男 男 1975
2 圣斗士 车田正美 男 1974
3 灌篮高手 井上雄彦 男 1996
jp-fmale.txt
4 犬夜叉 高桥留美子 女 1996
en-male.txt
3 The Great Gatsby(了不起的盖茨比) 菲茨杰拉德 男 1919
en-fmale.txt
1 Pride and Prejudice (傲慢与偏见) 简·奥斯汀 女 1813
2 Sense and Sensibility (理智与情感) 简·奥斯汀 女 1775
上传文件到/usr/local/src目录中
1.4.1.3.3 插入数据
hive> load data local inpath '/usr/local/src/zh-male.txt' overwrite into table tb_book2 partition(category='china',gender='male');
hive> load data local inpath '/usr/local/src/jp-male.txt' overwrite into table tb_book2 partition(category='jp',gender='male');
hive> load data local inpath '/usr/local/src/jp-fmale.txt' overwrite into table tb_book2 partition(category='jp',gender='fmale');
hive> load data local inpath '/usr/local/src/en-male.txt' overwrite into table tb_book2 partition(category='en',gender='male');
hive> load data local inpath '/usr/local/src/en-fmale.txt' overwrite into table tb_book2 partition(category='en',gender='fmale');
注:insert into并不是hive中标准的用法,而应该用load。
1.4.1.3.4 存放结构
可以看到多维分区表就多了几级目录而已,上传的文件就被放在了对应的目录下。
查看SDS表
1.4.1.3.5 查询数据
查询所有数据
hive> select * from tb_book2;
OK
1 西游记 china male
2 红楼梦 china male
3 三国演义 china male
4 水浒传 china male
1 Pride and Prejudice (傲慢与偏见) en fmale
2 Sense and Sensibility (理智与情感) en fmale
3 The Great Gatsby(了不起的盖茨比) en male
4 犬夜叉 jp fmale
1 一休 jp male
2 圣斗士 jp male
3 灌篮高手 jp male
Time taken: 0.261 seconds, Fetched: 11 row(s)
查询部分数据
hive> select * from tb_book2 where category='en' and gender='fmale';
OK
1 Pride and Prejudice (傲慢与偏见) en fmale
2 Sense and Sensibility (理智与情感) en fmale
Time taken: 0.267 seconds, Fetched: 2 row(s)
hive>
1.4.1.4 总结
这么做的意义何在呢?例如我只查英文的女作家的where category='en' and gender='fmale'。这样就只查en目录下的fmale目录。少差近1/4的数据。那查询速度就飞速提升。
1.5 Hive的误区
1.5.1 问题:Hive能做数据库吗?
Hive虽然用起来感觉像是数据库,但实际不是。为什么呢?我们知道数据库能完成CRUD操作,但Hive是基于Hadoop的,Hadoop是只能新增和追加的不能删除和修改的。Hive是无法做到实时的CRUD操作的。另外它还需要转换成MR执行,那它的性能不可能特别高。它的本质是一种离线大数据分析工具。
1.5.2 问题:Hive和Hbase的区别?
Hive是基于Hadoop的一个数据仓库工具。可以将结构化的数据文件映射为一张数据库表,并提供完整的sql查询功能,可以将sql语句转换为MapReduce任务进行运行。
Hbase是非结构化数据库,专门处理非结构化数据。
Hive是高吞吐量,一次可以处理大量数据,但是连接时还是不够快,不是一个低延迟的结果,无法直接做到快速响应,秒级甚至毫秒级响应。Hive是一次写入多次读取,而数据库要支持CRUD增删改查操作,所以Hive无法直接做数据库。
1.5.3 问题:数据库和数据仓库的区别?
Hive是基于Hadoop的数据仓库。那什么是数据库仓库呢?和我们学习的mysql、oracle等数据库有什么区别呢?
数据仓库与数据库的主要区别在于:
数据库是面向事务的设计,数据仓库是面向主题设计的
数据库一般存储在线实时数据,数据仓库存储的一般是历史数据
数据库设计是尽量避免冗余,数据仓库在设计是有意引入冗余
数据库是为捕获数据而设计,数据仓库是为分析数据而设计
1.5.4 问题:为什么Hive不支持行级的插入、更新、删除?
因为Hive是基于Hadoop的,Hadoop底层不支持数据的行级插入、更新、删除。那Hadoop为何不支持呢?
Hadoop底层HDFS是分布式的文件存储。1.0默认以64M来分块,2.0默认以128M来分块。如果在中间插入内容势必影响这个文件的这个位置之后的所有分块,而且HDFS是存储海量数据的,可能仅仅因为插入1字节,但导致后面的所有分块都要重新分配,工作量巨大,耗时长。一只蚂蚁却引来了大厦的垮塌。得不偿失,所以Hadoop选择了拒绝,选择了不支持。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号