

大数据3.2 -- 实时笔记
为什么要使用Hadoop技术?为什么会诞生Hadoop技术?
透过现象看本质:所以应用程序集中4个方面:
分布式、高并发、高可用(互联网架构技术)、海量数据(lucene+solr/es数据存储-索引、数据检索)
海量数据存储PB、EB
海量数据分析Hadoop离线分析,Spark实时分析,Storm实时分析。
海量数据展现 eCharts(总结数据)图表展现
Solr和es有什么差异?
Solr处理海量数据的量大过es
Es当数据已经很大量时,创建索引的时间还非常快,几乎和数据量小的时候一样的速度。Solr当数据量大时,创建索引的速度越来越慢。
在业务系统中为了支持更大数据量使用solr离线查询;
如果在大数据范畴,一般都采用es实时的查询。
Hadoop安装
1) ip地址必须成功,NAT换成桥接,Centos桌面版,图形方式配置ip
2) 安装zk,hostname必须按配置文件走,
3) 第一台namenode 耗费资源,尽量多分配内存1g/2g,其它放datanode,512m。
4) 配置很多的配置文件
a) 默认这些配置临时信息默认存放在系统的tmp目录中,当机器万一重启时,服务临时文件就被删除了。Format namenode,就没法正确操作。修改tmp目录
b)
Hadoop 节点
1) Namenode 记录管理信息
2) Datanode
3) SecondNamenode
4) resourceManage
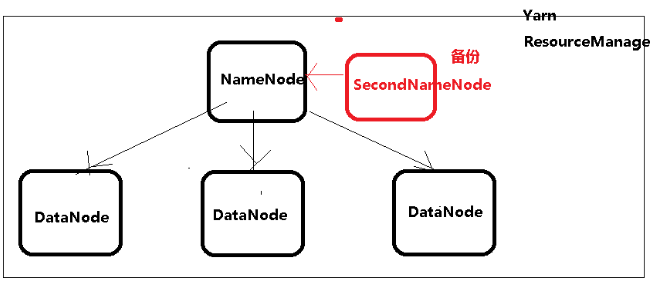
在集群环境中,运行需要reduce过程这时必须启动ResouceManage服务!!!
发生假死!
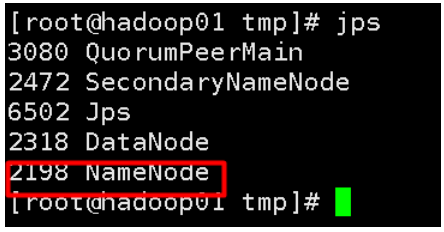
bin/hdfs namenode -format
明明命令非常正确,配置也正确,就是不提示成功。
如果不提示成功,再执行一次即可。注意要把创建的tmp目录下的内容删除
开发中:
1) 配置文件放在windows中编辑,拷贝到linux
2) 命令最好敲(命令执行错误时,第一个就检查这个参数-号)
启动Hadoop后
Apache Flume
Why? 为什么需要Flume这项技术?
Flume日志收集工具,收集+加工+转向到其他工具中
输入+处理+输出(大自然搬运工!)
早期日志
1) 理都不理,业务比较简单这时如果出错,一看就知道是哪个业务错误,立即修改,重新部署就可以。就用System.out
2) 业务模块众多,业务模块交叉,日志信息的量就大了,又很多人访问,出现高并发问题。大家一起访问,一起sysout,业务执行被严重干扰!
3) 出现log4j。出现分级FINAL、ERROR、DEBUG、INFO。根据开发的阶段(需求调研、概要设计、详细设计、开发编码、测试、部署、上线试运行、正式运行、维护期、项目结束)的不同,来设置不同的日志展现级别,展现级别以上信息才被打印,以下级别就不打印。
顺序:FINAL>ERROR >INFO>DEBUG
开发编码DEBUG
测试DEBUG、
部署DEBUG、
上线试运行DEBUG(企业业务人员)
正式运行DEBUG,INFO,NONE(OFF)关闭
维护期OFF
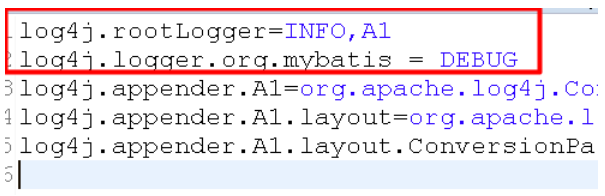
各个模块单独配置日志级别
1) 先配置所有的模块INFO
2) 可以单独设置某个模块mybatis打印详细的日志
分模块:按包路径设置
private static Logger log = Logger.getLogger(LogServlet.class);
在业务中打印日志
Log4j最终是把日志信息写入到日志文件中tomcat/log/localhost_2018040223894782834.log
按日滚动,本质磁盘文本文件。
1) 传统log4j日志IO操作文本文件,文件量有限,IO操作会有性能瓶颈,在海量数据下,高并发下支撑不了的
2) 分布式 log4j不是支撑分布式结构,一般单机。日志散落在很多机器上,这是不方便查看
3) 日志分析PV/UV/VV日志流量分析;从这些日志信息进行规范处理(清洗)
Flume cloudera公司,开源贡献给Apache
名词概念:
1) Event 事件,fun(json)数据,把数据包装了一下
2) Agent 代理:第一数据收集,第二数据传输,第三数据输出(hfds,kafka)
3) Source 数据输入,数据的源头
4) Channel 数据传输过程中转,缓存,排队
5) Sink 数据输出
由上面的这些组件就可以产生千变万化的结构!

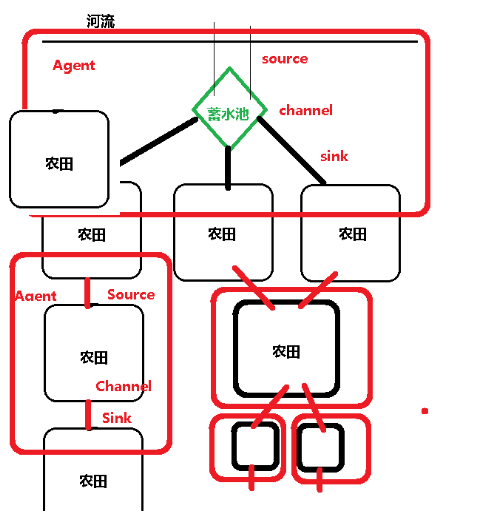
特点:
Agent高度抽象概念,
Source可以多数据源(file,dir,hdfs,log4j,mysql)
Channel在每个Agent中只有一个channel
Sink可以多个输出(file,hdfs,kafka)
Flume.properties属性配置文件,配置agent,source,channel,sink

步骤:
1) 根据业务配置flume-avro.properties,配置agent,source,sink,channel
2) 运行flume进程
../bin/flume-ng #bin目录下的flume-ng执行文件
agent #配置一个agent
-c ./ 配置路径 ./当前路径
-f ./flume-avro.properties #flume配置文件,路径:在配置文件所在路径运行程序
-n a1 #给agent命名,a1,必须和配置文件中定义agent名称一致
-Dflume.root.logger=INFO,console #配置输出logger,打印控制台
./flume-ng avro-client flume-ng自带一个客户端工具,发出tcp请求
-c ../conf 配置目录位置
-H 0.0.0.0 hostname,ip地址,域名 localhost
-p 22222 端口
-F ../../log.txt 数据文件所在位置
这个信息如果很多,这里只打印开头的部分信息!
支持http请求,启动tomcat web中间件,flume内置jetty。启动web服务。
Linux系统自带命令:
curl -X POST -d '[{"headers":{"tester":"tony"},"body":"hello http flume"}]' http://0.0.0.0:22222
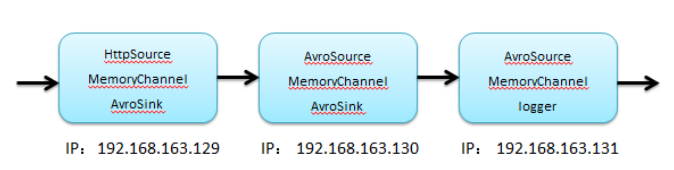
用户已http请求发起访问,访问a1,获取到数据,进行处理,封装avroSink输出,它作为a2它数据源,获取到数据,进行处理,封装avroSink输出,它作为a3的数据源,数据处理,最终将结果打印到控制台上。
步骤:
1、远程复制
scp -r flume/ root@hadoop02:/usr/local/src/
2、给每个节点创建一个flume配置文件
3、分别启动每个节点上的flume,启动时有没有顺序啊?从后往前来启动各自flume
NoClassDefFoundError: org/apache/hadoop/io/SequenceFile$CompressionType
HDFS处理很多,需要api支撑
Common.configration包jar
hdfs://hadoop01:9000/flume/data2/FlumeData.1522657046769.tmp
flume默认文件名FlumeData
1522657046769 时间戳
正在处理时文件名会有tmp后缀,当处理完成就会自动改掉
cd /usr/local/src/hadoop-2.7.1/share/hadoop/common/lib
cp *.jar /usr/local/src/flume/apache-flume-1.6.0-bin/lib
实现日志系统信息收集到flume中,步骤:
1) 日志项目要整合flume,插件包

2) 配置log4j属性配置,配置appender
log4j.appender.flume = org.apache.flume.clients.log4jappender.Log4jAppender
log4j.appender.flume.Hostname = hadoop01
log4j.appender.flume.Port = 22222
log4j.appender.flume.UnsafeMode = true
log4j和flume整合,log4j打日志时就会把数据写入到flume中,并且封装成avro方式
3) 配置flume-jt.properties属性文件
a) Source格式:avro(约定)
b) Channel格式:memory
c) Sink格式:hdfs
4) 运行agent
5) 运行日志系统,访问a.jsp,jsp中的埋点就访问日志系统servlet,打印log4j日志,lo4j打印日志,同时输出内容到flume中,flume写入hdfs上。
SEQ!org.apache.hadoop.io.LongWritable"org.apache.hadoop.io.BytesWritable 嬀R?
/兠4F?褅 b厔9? http://localhost/a.jsp|a.jsp|椤甸潰A|UTF-8|1024x768|24-bit|zh-cn|0|1||0.5267947720016783||Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/66.0.3343.4 Safari/537.36|95686657276343000667|6107185215_0_1522658447208|0:0:0:0:0:0:0:1
不是乱码,因为对中文按GBK编码。
两个名词:
1) 扇入
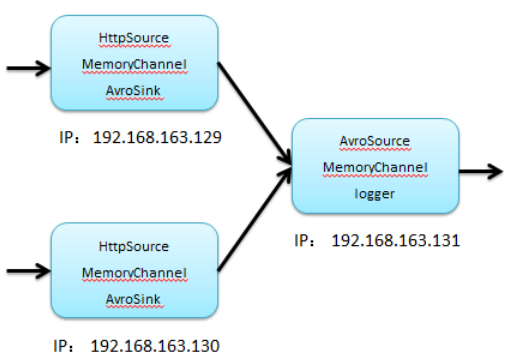
步骤:
1)3个配置文件
2)分别启动服务,131,129/130
3)发起http测试即可
2) 扇出
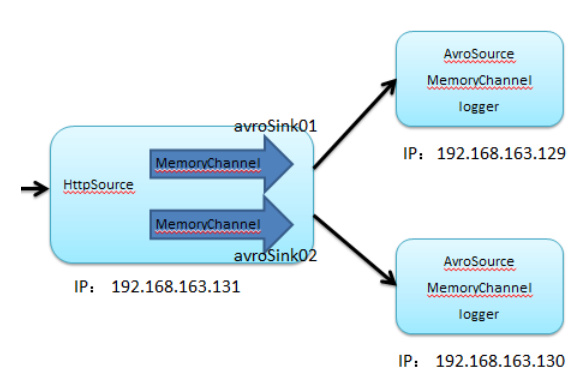
一个channel对应一个sink
步骤:
1) 三个配置文件,第一配置文件要创建2个channel,为了两个sink
2) 运行flume-ng
小结:
1) Apache Flume 日志收集工具
2) 概念
a) Event flume把数据封装json格式:[{“header”:xxx},{body:{xxxx}}]
b) Agent 代理,包括:Source、Channel、Sink
c) Source 数据源avro、http、jdbc、spooldir….官网
d) Channel 中转缓存,队列
e) Sink 输出 avro、hdfs、kafka
f) 扇入:汇聚
g) 扇出:拆分
3) hdfs在操作时复制很多jar
/usr/local/src/hadoop/hadoop-2.7.1/share/hadoop/common/lib 所有的jar复制过去
/usr/local/src/hadoop/hadoop-2.7.1/share/hadoop/common 3个jar包
/usr/local/src/hadoop/hadoop-2.7.1/share/hadoop/hdfs 目录 hadoop-hdfs-2.7.1.jar

 浙公网安备 33010602011771号
浙公网安备 33010602011771号