

大数据入门
大数据
大数据:big data,指无法在一定时间范围内用常规软件工具进行捕捉、管理和处理的数据集合,
是需要新处理模式才能具有更强的决策力、洞察发现力和流程优化能力的海量、高增长率和多样化的信息资产。
问题:
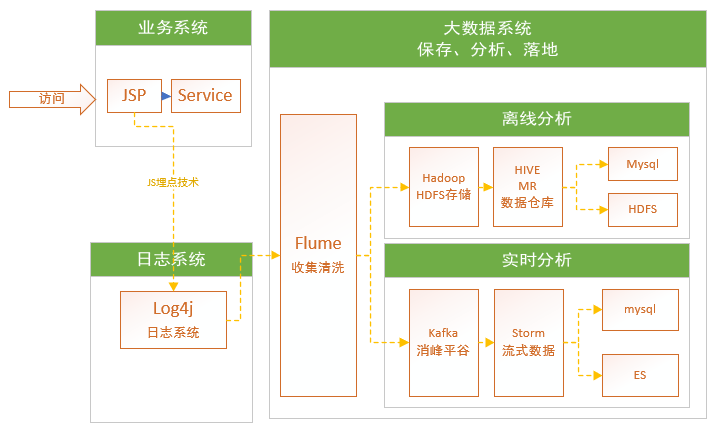
1、业务系统中打印日志,会影响我们的执行效率,在高并发情况下,对性能影响极大。
所以使用js埋点技术进行解决。将日志收集和业务服务进行分离。
主流处理海量数据
有两条线:
1) 离线分析,业务系统打log4j日志,通过flume获取log4j日志,保存数据到HDFS分布式文件处理,通过MR(Map拆分Reduce汇聚)进行离线分析,MR晦涩难懂,需要去了解Hadoop提供API,于是Hive产品,基于MR形成HQL语句,类SQL语句。分析人员就非常方便来学习和使用。而且Hive在HDFS上创建数据仓库(数据挖掘),结果如果少量保存mysql,如果海量Hbase/HDFS。
2)实时分析,spark/storm,storm实时处理中最快0.2s~05s,基于事件模型event,单条处理。不能直接把flume收集数据放入storm中,如果数据量非常大,storm抛弃,如果抛弃过多数据分析的结果偏差比较大。引入kafka,起到削峰平谷作用。Storm处理时就更加平滑。
log4j
日志系统
Log4j是Apache的一个开源项目,通过使用Log4j,
我们可以控制日志信息输送的目的地是控制台、文件、GUI组件,甚至是套接口服务器、NT的事件记录器、UNIX Syslog守护进程等;
我们也可以控制每一条日志的输出格式;
通过定义每一条日志信息的级别,我们能够更加细致地控制日志的生成过程。
最令人感兴趣的就是,这些可以通过一个配置文件来灵活地进行配置,而不需要修改应用的代码。
flume
flume:水道,引水槽
收集清洗
Hadoop
HDFS : Hadoop Distributed File System:分布式文件系统
hadoop:分布式计算
distributed:分布式的,分散性的
MapReduce: 分布式计算系统
Hadoop是一个由Apache基金会所开发的分布式系统基础架构。
用户可以在不了解分布式底层细节的情况下,开发分布式程序。充分利用集群的威力进行高速运算和存储。
Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS。HDFS有高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上;而且它提供高吞吐量(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,可以以流的形式访问(streaming access)文件系统中的数据。
Hadoop的框架最核心的设计就是:HDFS和MapReduce。
HDFS为海量的数据提供了存储,则MapReduce为海量的数据提供了计算。
Hive
hive:群居;入蜂房;生活在蜂房中
kafka
storm
想高薪就业,有长足发展!
面对海量数据?
1) 解决海量数据的存储(solr全文检索、Hadoop HDFS(PB=1024TB,EB=1024PB)
2) 海量数据的处理(不着急-离线分析Hadoop MapReduce(MR) Hive数据仓库Hive QL(HQL类sql的方式);立竿见影-实时分析 Spark RDD分布式的数据集/Spark SQL/Spark Streaming 流式数据处理 storm实时处理流式,快0.2s~0.5s,单条,spark1s~5s吞吐量,批量/Spark MLib 机器学习)
3) 处理完海量数据落地
- 处理完还是海量数据,保存HDFS,HBase
- 处理完不是海量数据,比较少,保存txt,excel,mysql
四类问题:
1)分布式
2)高并发
3)高可用
4)海量数据
两个生态链
1) Hadoop生态链:HadoopHDFS分布式的文件管理系统,Yarn集群调度,MR(MapReduce)离线计算,数据挖掘(利用原始数据中提炼有价值信息)DW(DataWarehouse数据仓库)Hive提前创建中间结果(数据建模)。HBase nosql 列式存储(海量) Sqoop数据迁移(Oracle导入Mysql)limit 10,rownum >10 存储过程、触发器(废除!)HDFS导入mysql,mysql导入HDFS。
2) Spark生态链、
Spark RDD分布式的数据集、Spark Streaming流式处理、Spark SQL 类SQL查询、Spark Mlib 机器学习
Storm 流式数据处理,性能storm最快 0.2s~0.5s,批量 spark streaming 2s~5s
3) zookeeper集群管理
问题:收集哪些参数?
网站流量日志分析系统:8项
1) PV page view 点击率,越高越好
2) UV unique view 独立访客数,类似登录,标识你是唯一用户
3) VV visitor view 某个访客访问次数,某个客户访问的次数累计
4) br bounce rate 跳出率,访问页面推荐,持续访问的指标,反应对用户黏着度
5) NewIP 统计一天内出现新的IP地址,日活!
6) NewCust 新用户
7) AvgTime 平均访问时长,如果某个页面停留时间越长,说明这个信息用户感兴趣。
8) AvgDeep 平均访问深度,一个页面就是一,数字越大网站吸引人
AvgTime统计这个值,a页面2分钟,b页面5分钟,c页面5分钟,d页面(被忽略)
常见情况:
1) d页面停留很久,30分钟session
2) d页面点进去后把ie关闭
这些统计中很多的数据统计不够“严谨”,这些都是近似值!!!!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号