

马哥博客作业第二周
线性数据结构
一、内建常用数据结构
-
序列sequence
- 字符串str、字节序列bytes、bytearray
- 列表list、元组tuple
-
键值对
- 集合set、字典dict
二、线性数据结构
线性表
-
线性表:是一种抽象的数学概念,是一组元素的序列的抽象,它由有穷个元素组成(0个或任意个)
-
顺序表:使用一大块连续的内存顺序存储中的元素,称为顺序表,或称连续表
在顺序表,元素的关系使用顺序表的存储顺序自然地表示
- 链接表:在存储空间中将分散存储的元素链接起来,这种实现称为链接表,简称链表
列表如同地铁站排好的队伍,有序,可以插队,离队,可以索引。
链表如同操场上手拉手的小朋友,有序但排列随意。或则可以想象成一串带线的珠子,随意盘放在桌子上。也可以离队、插队,也可以索引。
列表list

列表是非常这样的数据结构,对气内存结构何操作方法需熟记于心
初始化

索引
索引,也叫下标,分为正索引,负索引
-
正索引:从左至右,从0开始,为列表中每一个元素编号
-
负索引:从右到左,从-1开始,
-
正负索引都不可越界,否则引发异常IndexError
-
列表通过列表可以通过索引访问。 list[index] ,index就是索引,使用中括号访问
使用索引定位访问元素的时间复杂度为O(1),这是最快的方式,是列表最好的使用方式。
列表中的常用方法
查询
标注:value 需要查找的值
start 查找范围的起始索引
stop 查找范围的结束索引
int 返回值时int类型,即值对应的索引
-
index(value[,start[,stop]])->int
通过value值,从指定区间查找列表内的元素是否匹配,匹配第一个就立即返回其对应索引,匹配不到,抛出异常ValueError
-
count(value)
返回列表中匹配value的次数
-
时间复杂度
index和count方法是O(n)
随着列表数据规模的增大,而效率下降
-
如何返回列表元素的个数?如何遍历?如何设计高效?
len()
修改
list[index] = value
将列表中索引为index的值修改为value,注意index索引不能超界
增加单个元素
-
append(object)->None
在列表尾部追加元素object
返回值None就意味着没有新的列表产生,就地修改
时间复杂度O(1)
object需要插入的元素
-
insert(index,object)->None
在指定索引index处插入元素object。
返回值None就意味着没有新的列表产生,就地修改。
时间复杂度O(n)
-
索引能超上下界吗?
超越上界,尾部追加
超越下界,头部追加
增加多个元素
-
extend(iterable)->None
将可迭代对象的元素追加到尾部,返回值None.
就地修改
-
+list
将两个列表链接起来,产生一个新的列表,原列表不变。
本质上是调用了__add()__方法
-
*list
重复操作,将本列表元素重复n次,返回新的列表
![]()

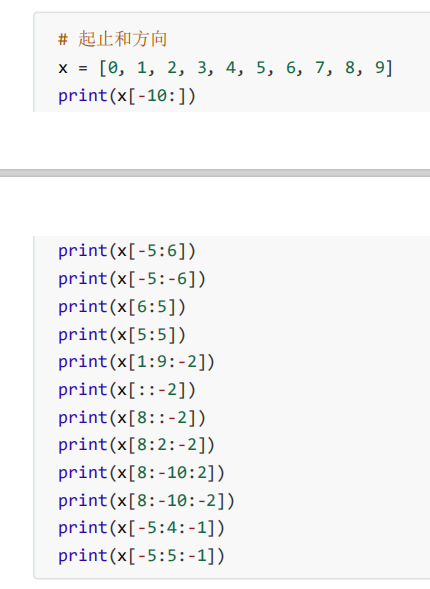
在python中一切皆对象,而对象都是引用类型,可以理解为一个地址指针指向这个对象。
但是,字面常量字符串、数值等表现却不像引用类型,暂时称为简单类型。
元组,字典,列表,包括以后学习的类和势力都可以认为是引用类型。
可以认为简单类型直接存在列表中,而引入类型只是把引用地址存在了列表中。
删除元素
-
remove(value)->None 从左至右查找第一个匹配value的值,移除该元素,返回None.就地修改。效率比较低,会产生元素的挪动。
-
pop([index])->item
删除指定索引index位置的元素,如果不指定,默认从列表尾部删除。返回被删除元素的对象。
index 需要删除元素所在位置的索引。如果不是从尾部删除,会产生元素的挪动。时间复杂度最大为O(n),如果从尾部删除,时间复杂度为O(1)
-
clear()->None
清除列表索引元素,剩下一个空列表,就地修改
反转
reverse()->None 将列表元素反转,返回None。就地修改
这种方法最好不用,可以倒着读取,都不要反转
排序
- sort(key=None,reverse=False)->None 对列表元素进行排序,就地修改,默认升序 key 一个函数,指定key如何排序 lst.sort(key=function) reverse反转,默认值为False,表示升序,如果指定reverse=Ture,反转降序
in成员操作

列表复制
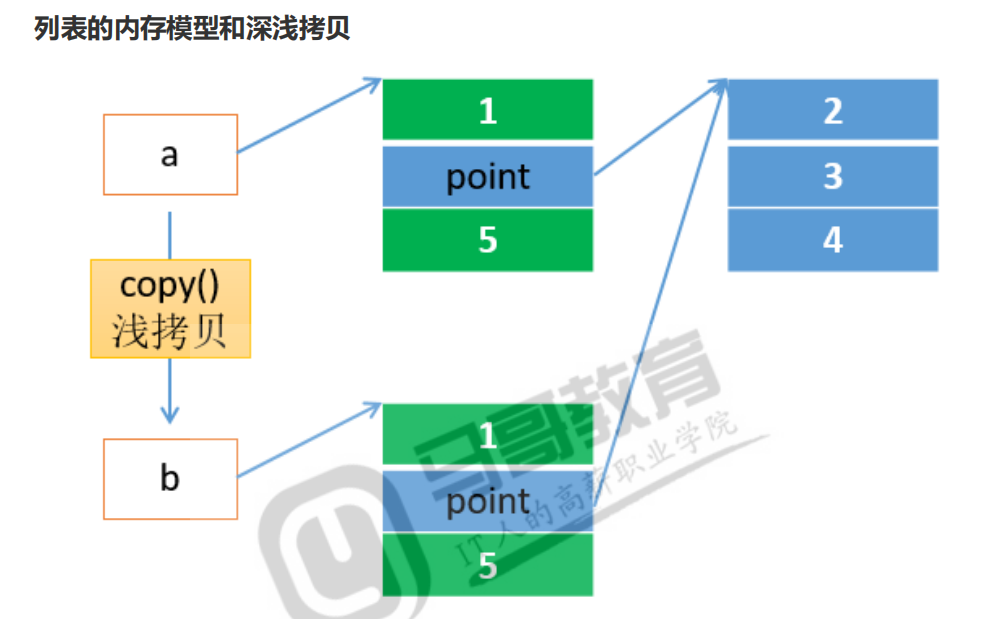
copy()->list 会返回一个新列表。注意copy是浅拷贝,如果列表中的值有引用类型,只会复制引用类型的地址。
如果想使用影子拷贝,也叫深拷贝。深拷贝遇到引用类型,会在内存中重新创建一个和引用类型所指向的对象。
copy模块提供了deepcopy方法可以达到深拷贝 一般情况下,大多数语言提供的默认复制都是浅拷贝
元组
一个有序的元素组成的集合
使用小括号()表示
元组是不可变对象
初始化

索引
与列表规则一样,不可以超界
元组常用方法
查询
与列表一样,时间复杂度也一样 index count len等
增删改
元组元素的个数在初始化的时候已经定义好了,所以不能为元组增加元素、也不能从中删除元素、也不能修改元素的内容。

字符串
-
一个个字符串组成的有序的序列,是字符的集合
-
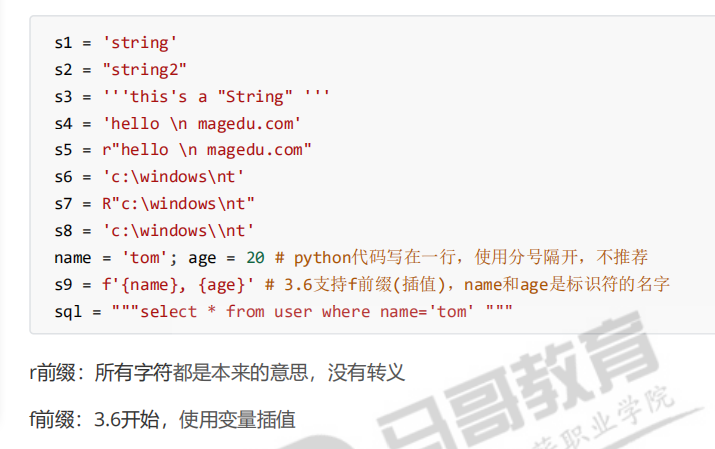
使用单引号,双引号,三引号引住的字符序列
-
字符串是不可变对象,是字面常量
python3起,字符串都是unicdoe类型
初始化
索引
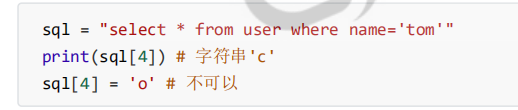
字符串是序列,支持下标访问。但不可改变,不可以修改元素。
连接
+加号
- 将两个字符串连接起来,返回一个新的字符串
join方法
-
sep.join(iterable)
-
使用指定字符串作为分隔符,将可迭代对象中字符串使用分隔符拼接起来
-
返回新的字符串
![]()

字符查找


index(sub[,start[,end]])->int #在指定的区间[start,end),从左到右,查找子串sub。找到返回索引,没找到抛出异常ValueError(如果不设置start和end就在整个字符串中查找)
rindex(sub[,start[,end]])->int #在指定的区间[start,end),从右到左,查找子串sub。找到返回索引,没找到抛出异常ValueError(如果不设置start和end就在整个字符串中查找)
标注:
- sub 要查找的字符串
- start 查找区间的起始索引
- end 查找区间的结束索引(不包含结束索引)
index方法和find方法很像,不好的地方在于找不到抛异常,推荐使用find方法
分割


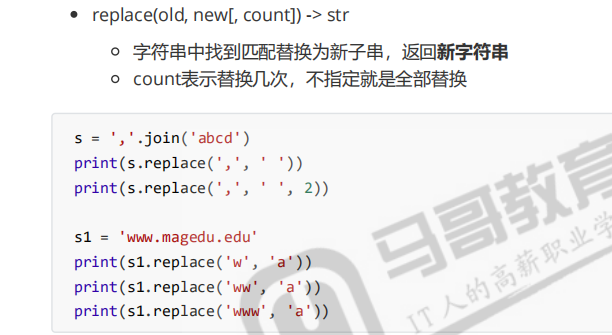
替换
移除
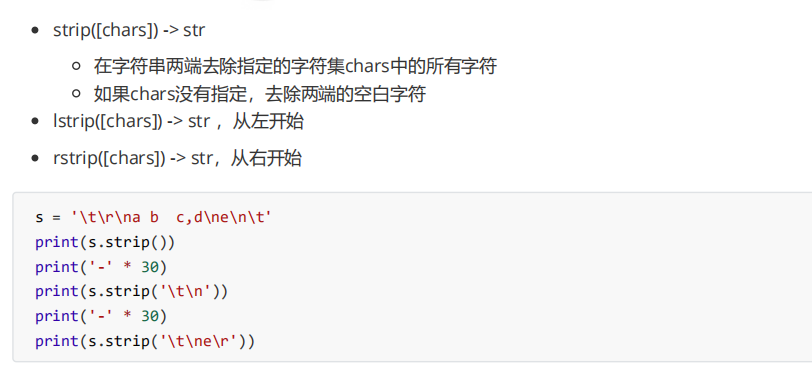
首位判断

其他函数
-
upper()大写
-
lower()小写
-
swapcase()交换大小写
-
isalnum() bool是否是字母和数字组成
-
isalpha()是否是字母
-
isdecimal()是否只包含十进制数字
-
isdigit()是否全部数字(0-9)
-
isidentifier()是不是字母和下划线开头、其他都是字母、数字、下划线
-
islower()是否都是小写
-
isupper()是否全部大写
-
isspace()是否包含空白字符
其他格式打印函数中文几乎不用
格式化
简单的使用+或者join也可以拼接字符串,但是需要先转换数据到字符串才能拼接
C风格printf-style
-
占位符:使用%和格式字符,例:%5 %d
-
修饰符:在占位符中还可以插入修饰符,例:%03d
-
format % values
- format是格式字符串,values是被格式的值
- 格式字符和被格式的值之间使用%
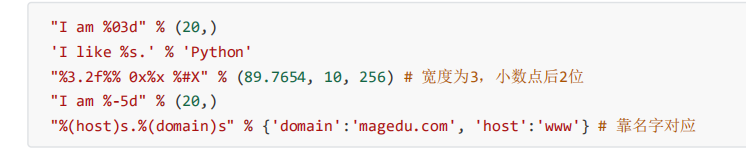
format函数
在python2.5之后,字符串类型提供了format函数,功能更强大,鼓励使用。
”{}{xxx}”.format(*args,**kwargs)->str
args是位置参数,是一个元组
kwargs是关键字参数,是一个字典
{}花括号为占位符,表示按照顺序匹配参数,{n}表示取位置参数args[n]对应的值
{xxx}其中xxx为关键字名称,表示在关键字参数kwargs中搜索名称一致的参数对应值
{{}}表示打印花括号(注意:双符号表示转译输出)
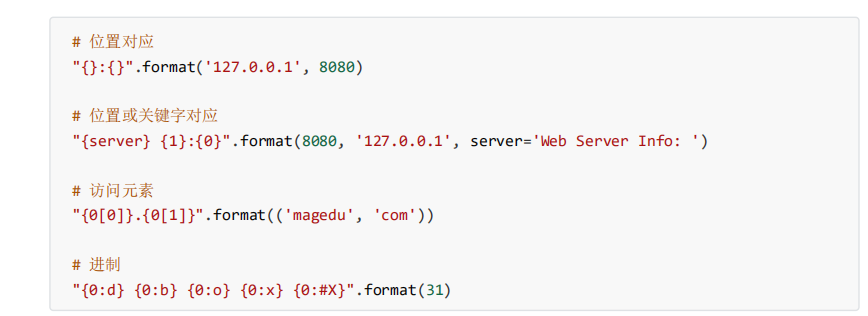
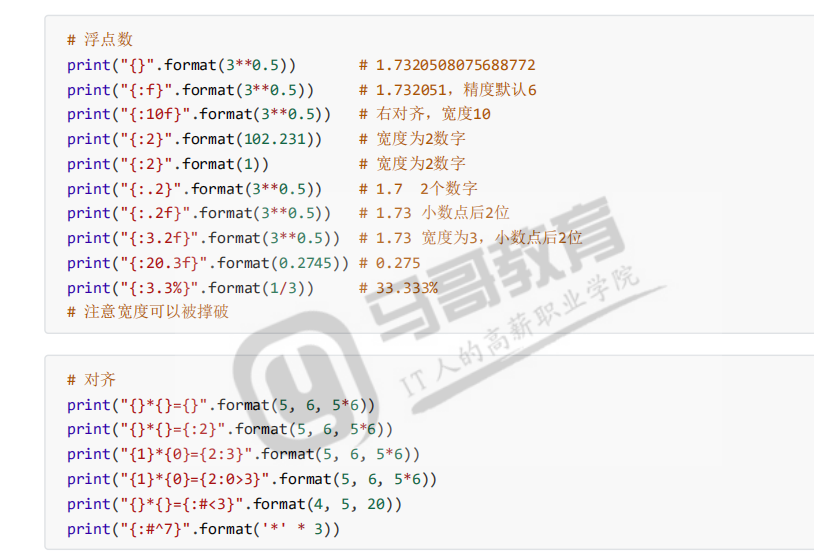
编码与解码
编码:str —> bytes 将字符串这个字符序列使用指定字符集encode编码为一个个字节组成的序列bytes
解码:bytes或byte array=>str,将一个个字节按某种指定字符集解码为一个个字符串组成的字符串

注意:这里的1指的是字符1,不是数字1 utf-8、gbk都兼容了ASCII

字节序列
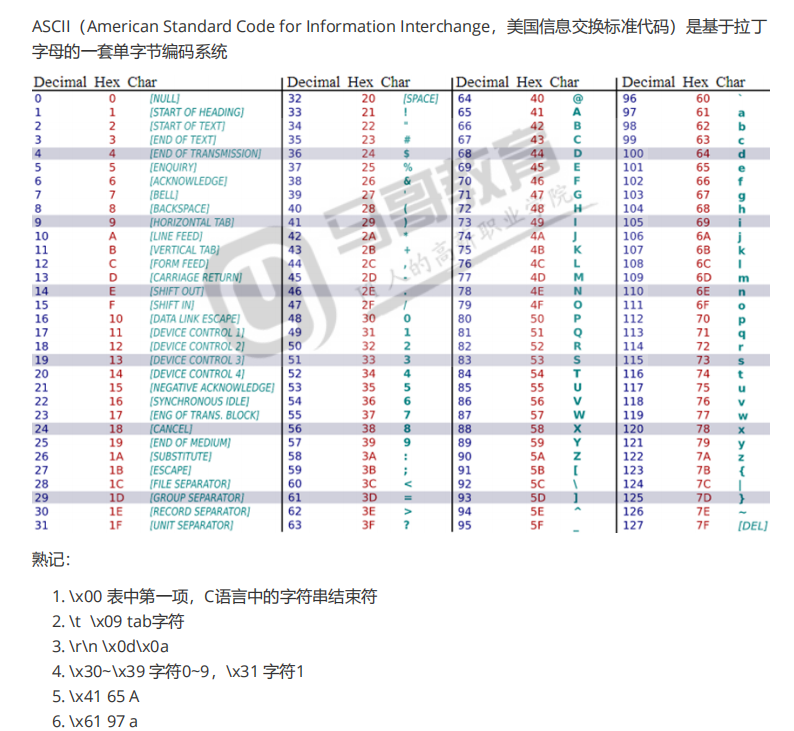
python3中引入两种新类型: bytes(不可变字节序列) byte array(可变字节数组)
bytes(不可变字节序列)
初始化

索引
print(b'abcd'[2]) 返回int,指定是本字节对应的十进制数
bytes操作方法
大部分方法和str类似,都是不可变类型,所以方法很多都一样。只不过bytes方法,输入的是bytes输出的也是bytes
b'abcdef'.replace(b'f',b'z')
b'abc'.find(b'c')
类方法构造
bytes就是字节序列,最好书写的方式就是16进制的字符串表达,例如‘6162 6a 6b’,这个字符串的空格将被忽略。

十六进制表达
一个bytes对象,就是应该给字节的序列,完全可以把每个字节用16进制表示 例'abcde'.encode().hex() 返回字符串
byte array(可变字节数组)
初始化

索引
print(bytearray(b'abcd')[2]) 返回int,指定是本字节对应的十进制数
byte array操作方法
和bytes类似
b'abcdef'.replace(b'f',b'z') b'abc'.find(b'c')
类方法构造
byte array就是字节数组,最好书写方式就是十六进制的字符串表达,例如'6162 6a 6b',这个字符串中的空格将被忽略

更多操作方法
由于byte array类型是可变数组,所以,又类似列表
- append(int)尾部追加一个元素
- insert(index,int)在指定索引位置插入元素
- extend(iterable_of_ints)将一个可迭代的整数集合追加到当前byte array
- pop(index=-1)从指定索引异除元素,默认从尾部移除
- remove(value)找到第一个value移除,找不到抛ValueError异常
- 注意:上述方法若需要使用int类型,值在[0,255]
- clear()清空byte array
- reverse()翻转byte array,就地修改
![]()
字节序
内存中对于一个超过译者字节数据的分布方式

- 大端模式,big-endian;小端模式,litter-endian
- intel x86 cpu 使用小端模式
- 网络传输更多使用大端模式
- Windows、Linux使用小端模式
- mac os 使用大端模式
- Java虚拟机是大端模式
int和bytes互转
int.from_bytes(bytes,byteorder)
- 按照指定字节序,将一个字节序表示成整数
int.to_bytes(length,byteorder)
- 按照指定字节序,将一个整数表达成一个指定长度的字节序列
![]()

线性结构
线性结构特征:
-
可迭代for... in
-
有长度,通过len(x)获取,容器
-
通过整数下标可以访问元素。正索引、负索引 可切片
已经学习过的线性结构:list、tuple、str、bytes、byte array
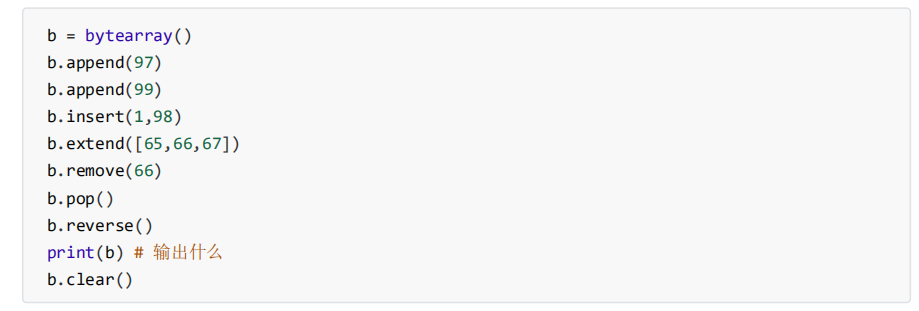
切片
sequence[start:stop]
sequence[start:stop:step]
- 通过给定索引区间获得线性结构的一部分数据
- start、stop、step为整数,可以是正整数,负整数,零
- start为0时,可以省略
- stop为末尾时,可以省略
- step为1时,可以省略
- 切片时,索引超过上界(右边界),就取到末尾;超过下界(左边界),取到开头
![]()
![]()

在序列上使用切片[start:stop],子区间索引范围(start,stop),相当于从start开始指向stop的方向上获取数据
默认step为1,表示向右;步长为负数,表示向左
如果子区间方向和步长方向不一致,直接返回当前类型的”空对象“
如果子区间方向和步长方向一致,则从起点间隔步长取值
本质

上例可知,实际上切片后得到一个全新的对象。[ : ]或[ : : ]相当于copy方法
切片赋值
- 切片操作写在了等号左边
- 被插入的可迭代对象卸载等号右边
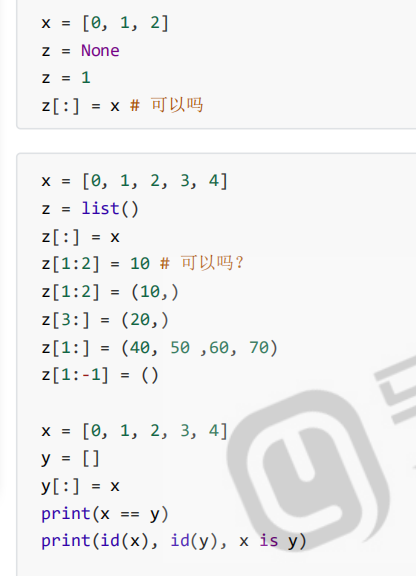
m和x它们两个变量指向同一个对象
y=[]、y[:]=x等价于z=x[:],都是创建x的副本
切片赋值用作与初始化相当于copy,还可以使用。如果用的替换、插入元素,看似语法比较简单,但是由于列表是顺序表结构,将会引起数据的挪动,这非常影响性能,应当尽量避免使用。

