
4.梳理HBase的结构与运行流程,以用图与自己的话进行简要描述,图中包括以下内容:
- Master主服务器的功能
- 主服务器Master主要负责表和Region的管理工作:
– 管理用户对表的增加、删除、修改、查询等操作
– 实现不同Region服务器之间的负载均衡
– 在Region分裂或合并后,负责重新调整Region的分布
– 对发生故障失效的Region服务器上的Region进行迁移
- 主服务器Master主要负责表和Region的管理工作:
- Region服务器的功能
- Region服务器是HBase中最核心的模块,负责维护分配给自己的Region,并响应用户的读写请求
- Zookeeper协同的功能
- Zookeeper可以帮助选举出一个Master作为集群的总管,并保证在任何时刻总有唯一一个Master在运行,这就避免了Master的“单点失效”问题
- Client客户端的请求流程
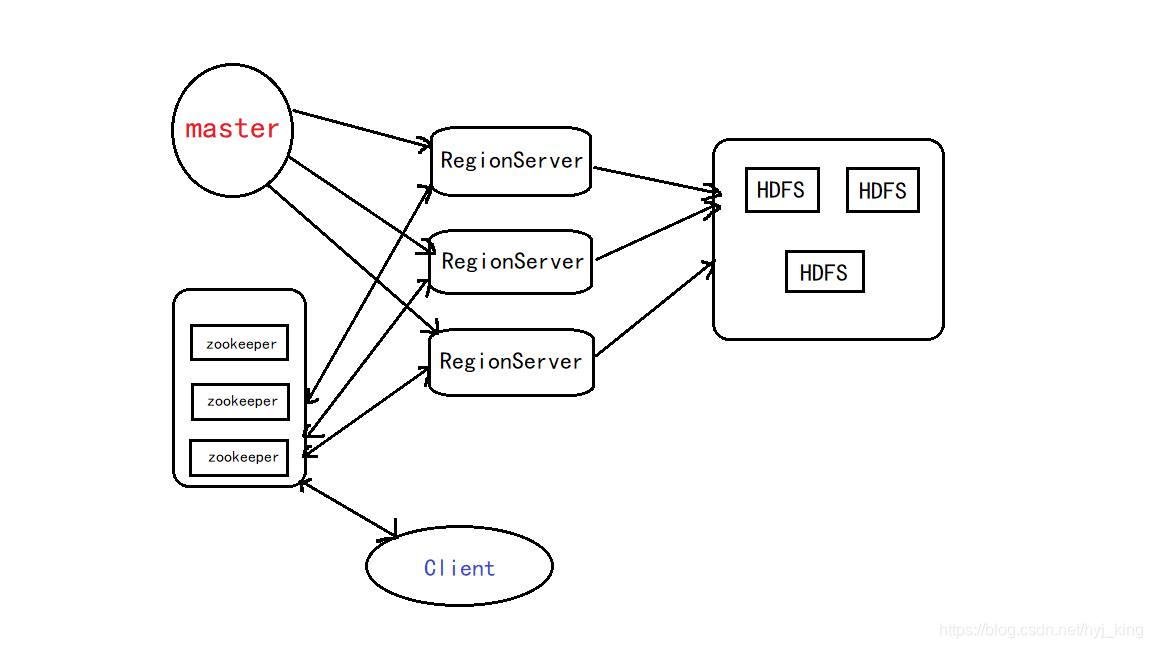
- 四者之间的相系关系
1、Hbase集群有两种服务器:一个Master服务器和多个RegionServer服务器;
2、Master服务负责维护表结构信息和各种协调工作,比如建表、删表、移动region、合并等操作;
3、客户端获取数据是由客户端直连RegionServer的,所以Master服务挂掉之后依然可以查询、存储、删除数据,就是不能建新表了;
4、RegionServer非常依赖Zookeeper服务,Zookeeper管理Hbase所有的RegionServer信息,包括具体的数据段存放在那个RegionServer上;
5、客户端每次与Hbase连接,其实都是先于Zookeeper通信,查询出哪个RegionServer需要连接,然后再连接RegionServer;客户端从Zookeeper获取了RegionServer的地址后,会直接从RegionServer获取数据;
- 与HDFS的关联
RegionServer保存的数据直接存储在Hadoop的HDFS上;
5.理解并描述Hbase表与Region与HDFS的关系。
HBase 表根据 RowKey 的开始和结束范围水平拆分为多个 Region。每个 Region 都包含了 StartKey 和 EndKey 之间的所有行。每个 Region 都会分配到集群的一个节点上,即 RegionServer,由它们为读写提供数。RegionServer 大约可以管理 1000 多个 Region,HDFS是Hadoop分布式文件系统。
HBase的数据通常存储在HDFS上。HDFS为HBase提供了高可靠性的底层存储支持。
Hbase是Hadoop database即Hadoop数据库。它是一个适合于非结构化数据存储的数据库,HBase基于列的而不是基于行的模式。
HBase是Google Bigtable的开源实现,类似Google Bigtable利用GFS作为其文件存储系统,HBase利用Hadoop HDFS作为其文件存储系统;Google运行MapReduce来处理Bigtable中的海量数据,HBase同样利用Hadoop MapReduce来处理HBase中的海量数据。
HDFS为HBase提供了高可靠性的底层存储支持,Hadoop MapReduce为HBase提供了高性能的计算能力,Zookeeper为HBase提供了稳定服务和failover机制。Pig和Hive还为HBase提供了高层语言支持,使得在HBase上进行数据统计处理变的非常简单。 Sqoop则为HBase提供了方便的RDBMS(关系型数据库)数据导入功能,使得传统数据库数据向HBase中迁移变的非常方便。6.理解并描述Hbase的三级寻址。
- 从.META.表里面查询哪个Region包含这条数据。
- 获取管理这个Region的RegionServer地址。
- 连接这个RegionServer, 查到这条数据。
7.假设.META.表的每行(一个映射条目)在内存中大约占用1KB,并且每个Region限制为2GB,通过HBase的三级寻址方式,理论上Hbase的数据表最大有多大?
(-ROOT-表能够寻址的.META.表的Region个数)×(每个.META.表的 Region可以寻址的用户数据表的Region个数)
一个-ROOT-表最多只能有一个Region,也就是最多只能有2GB,按照每行(一个映射条目)占用1KB内存计算,2GB空间可以容纳2GB/1KB=2048KB*1024/1KB=2097152=2^21行,也就是说,一个-ROOT表可以寻址2^21个.META.表的Region。
同理,每个.META.表的 Region可以寻址的用户数据表的Region个数是2GB/1KB=2048KB*1024/1KB=2097152=2^21。
最终,三层结构可以保存的Region数目是(2GB/1KB) × (2GB/1KB) = 2^42个Region8.MapReduce的架构,各部分的功能,以及和集群其他组件的关系。
9.MapReduce的工作过程,用自己词频统计的例子,将split, map, partition,sort,spill,fetch,merge reduce整个过程梳理并用图形表达出来。

