
TensorFlow文本分类
参考文章:https://zhuanlan.zhihu.com/p/59506402
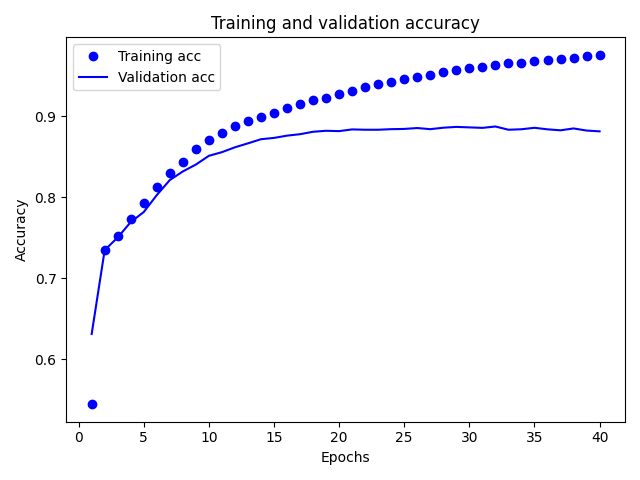
import tensorflow as tf import matplotlib.pyplot as plt import tensorflow.keras.layers as layers # 加载数据 imdb = tf.keras.datasets.imdb (train_x,train_y),(test_x,test_y) = tf.keras.datasets.imdb.load_data(num_words=10000) #了解IMDB数据 print(train_x[0]) print('len:',len(train_x[0]),len(train_x[1])) #创建id和词的匹配字典 word_index = imdb.get_word_index() word2id = {k:(v+3) for k, v in word_index.items()} word2id['<PAD>'] = 0 word2id['<START>'] = 1 word2id['<UNK>'] = 2 word2id['<UNUSED>'] = 3 id2word = {v:k for k, v in word2id.items()} def get_words(sent_ids): return ' '.join([id2word.get(i,'?') for i in sent_ids]) sent = get_words(train_x[0]) print(sent) #准备数据 train_x = tf.keras.preprocessing.sequence.pad_sequences(train_x,value=word2id['<PAD>'],padding='post',maxlen=256) test_x = tf.keras.preprocessing.sequence.pad_sequences(test_x,value=word2id['<PAD>'],padding='post',maxlen=256) print(train_x[0]) print('len:',len(train_x[0]),len(train_x[1])) #构建模型 vocab_size = 10000 model = tf.keras.Sequential() model.add(layers.Embedding(vocab_size,16)) model.add(layers.GlobalAveragePooling1D()) model.add(layers.Dense(16,activation='relu')) model.add(layers.Dense(1,activation='sigmoid')) model.summary() model.compile(optimizer='adam',loss='binary_crossentropy',metrics=['accuracy']) #模型训练与验证 x_val = train_x[:10000] x_train = train_x[10000:] y_val = train_y[:10000] y_train = train_y[10000:] history = model.fit(x_train,y_train,epochs=40,batch_size=512,validation_data=(x_val,y_val),verbose=1) result = model.evaluate(test_x,test_y) print(result) #查看准确率时序图 history_dict = history.history history_dict.keys() acc = history_dict['accuracy'] val_acc = history_dict['val_accuracy'] loss = history_dict['loss'] val_loss = history_dict['val_loss'] epochs = range(1,len(acc)+1) plt.plot(epochs,loss,'bo',label='train loss') plt.plot(epochs,val_loss,'b',label='val loss') plt.title('Train and val loss') plt.xlabel('Epochs') plt.xlabel('loss') plt.legend() plt.show() plt.plot(epochs, acc, 'bo', label='Training acc') plt.plot(epochs, val_acc, 'b', label='Validation acc') plt.title('Training and validation accuracy') plt.xlabel('Epochs') plt.ylabel('Accuracy') plt.legend() plt.show()


 浙公网安备 33010602011771号
浙公网安备 33010602011771号