
进行OCR的时候,同一个字符,通常需要很多字符小图,这样图片多了,才能训练出健壮的分类器。如何自动化地执行该过程呢?我提供一种思路。
待训练的图片集如下:
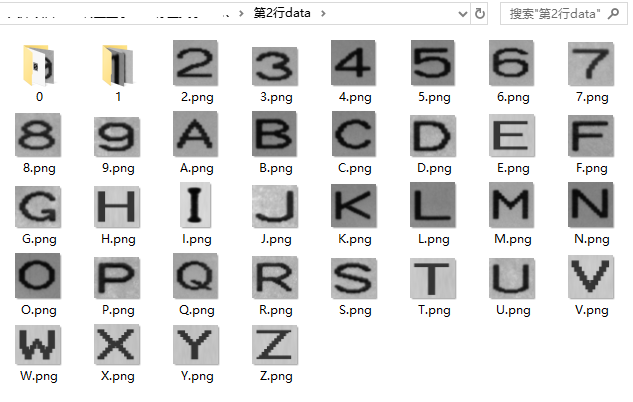
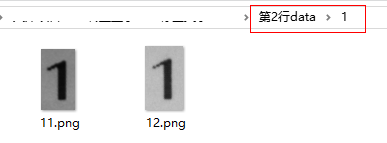
其中,“文件夹0”和“文件夹1”中有多张图片,例如“文件夹1”中的图片是这样的(图片名称第一个字符都是“1”):
训练OCR分类器的完整代码如下:
1 set_font (200000, 'Arial'+'-Bold-20')
2 dev_set_draw ('margin')
3
4 ImageFolder := '第2行data'
5
6
7 list_files (ImageFolder, ['files','follow_links','recursive'], ImageFiles)
8 tuple_regexp_select (ImageFiles, ['\\.(tif|tiff|gif|bmp|jpg|jpeg|jp2|png|pcx|pgm|ppm|pbm|xwd|ima)$','ignore_case'], ImageFiles)
9
10 gen_empty_obj (Images)
11 gen_empty_obj (RegionChars)
12 Chars := []
13
14 for Index := 0 to |ImageFiles| - 1 by 1
15 read_image (Image, ImageFiles[Index])
16 parse_filename (ImageFiles[Index], BaseName, Extension, Directory)
17 count_channels (Image, Channels)
18 if (Channels != 1)
19 rgb1_to_gray (Image, Image)
20 endif
21
22 *取文件名的第一个字符(例如字符1可能有多张图片,图片原始名字可能为11.bmp、12.bmp、13.bmp……)
23 tuple_substr (BaseName, 0, 0, BaseNameReal)
24
25 *增强图像对比度
26 scale_image_max (Image, Image)
27 emphasize (Image, Image, 11, 11, 1)
28
29 if (BaseNameReal == '.')
30 BaseNameReal := '.'
31 endif
32
33 threshold (Image, Region, 0, 152)
34 * binary_threshold (Image, Region, 'max_separability', 'dark', UsedThreshold)
35 opening_circle (Region, Region, 1)
36 fill_up_shape (Region, Region, 'area', 1, 100)
37
38 *将字符图像、字符区域、字符文本分别添加到Images、RegionChars、Chars中
39 concat_obj (Images, Image, Images)
40 concat_obj (RegionChars, Region, RegionChars)
41 Chars := [Chars,BaseNameReal]
42
43 dev_display (Image)
44 dev_display (Region)
45 endfor
46
47 *1.1创建训练文件
48 TrainFile:='Line2_Words.trf'
49 * delete_file(TrainFile)
50
51 *1.2将字符区域、字符图像与字符文本关联,保存到.trf训练文件中
52 for i:=1 to |Chars| by 1
53 select_obj(RegionChars, SingleWord, i)
54 select_obj(Images, SingleImage, i)
55 append_ocr_trainf(SingleWord,SingleImage,Chars[i-1],TrainFile)
56 endfor
57
58
59 ***********************************************************************
60
61 *2.1确定字体分类器文件名
62 FontFile:='Line2_Words.omc'
63
64 *2.2得到字符标识名(这一步非必须)
65 read_ocr_trainf_names(TrainFile, CharacterNames, CharacterCount)
66
67 *2.3确定神经网络隐藏层节点数
68 NumHidden := 80
69
70 *2.4创建神经网络分类器
71 create_ocr_class_mlp(42, 67, 'constant', 'default', CharacterNames, NumHidden, 'none', 10, 42, OCRHandle)
72
73 *2.5训练神经网络
74 trainf_ocr_class_mlp(OCRHandle, TrainFile, 200, 1, 0.9, Error, ErrorLog)
75
76 *2.6保存训练结果
77 write_ocr_class_mlp(OCRHandle, FontFile)
78
79 *2.7清除句柄
80 clear_ocr_class_mlp(OCRHandle)
作者:xh6300
--------------------------------------------
本文系原创,转载请注明出处。
如果文章对您有帮助,可以点击下方的【好文要顶】或【关注我】;如果您想进一步表示感谢,可通过网页右侧的【打赏】功能进行打赏。
感谢您的支持,我会继续写出更多的相关文章!文章有不理解的地方欢迎跟帖交流,博主经常在线!^_^

 浙公网安备 33010602011771号
浙公网安备 33010602011771号