分布式事务?咱先弄明白本地事务再说 - 可用性和速度(锁和并发)的博弈
在上文《分布式事务?咱先弄明白本地事务再说 - ACID》中,我们讲解了数据库的事务及事务的特性ACID,了解到一个数据库要支持事务,就需要实现完备的事务的规范,我们才能说这是一个支持事务的数据库,例如Mysql、Oracle等。
本文就来讨论一下数据库实现事务的几个关键阶段,背后都经历了哪些曲折的技术变迁。
数据库的事务,本质上是解决数据库并发的问题,处理多个数据操作时相互不干扰,都能得到正确的执行结果,这个问题在应用层是无法解决的,因为你完全不知道同时可能有另一个程序(进程)也在操作相同的数据项,所以,这个问题必须由数据库来解决。
完全顺序执行
最简单的思路,就是完全顺序执行所有的数据库操作,不需要加锁,简单的说就是全局排队,序列化进行所有的事务单元,数据库同时只处理一个事务,特点是强一致性,处理性能低。
这种模式适应于早期的C/S开发模式,单机系统,一个系统,一个数据库(例如Access数据库),完全本地用户+本地系统+本地事务。
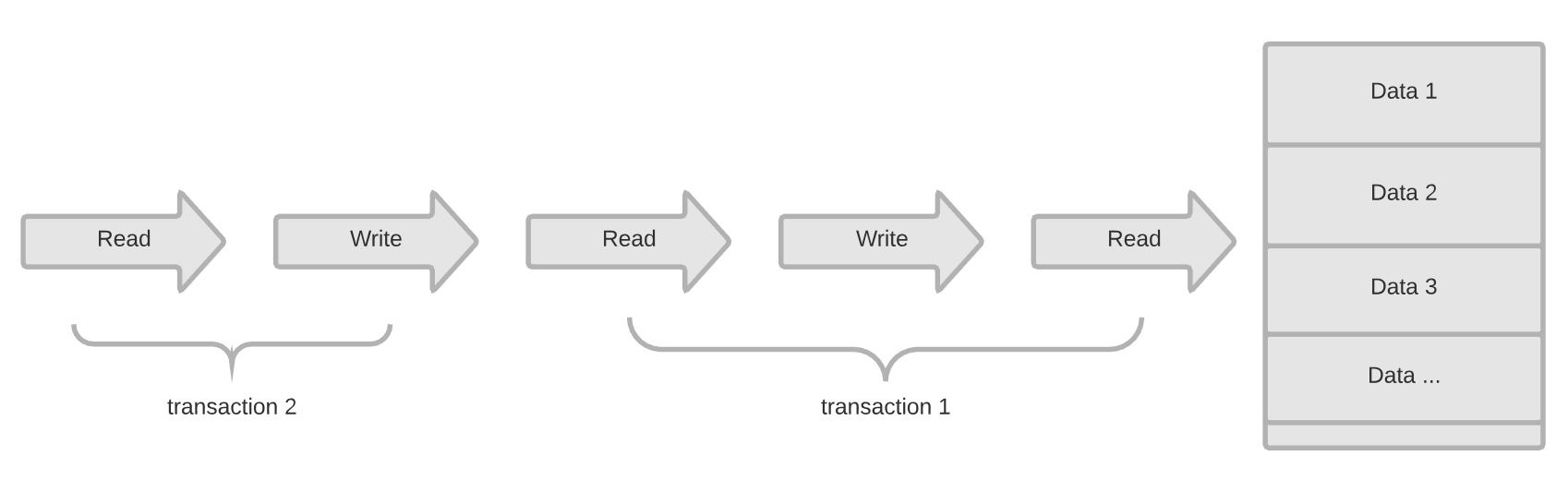
并行+排他锁
开始支持并行处理事务,如果事务之间涉及到相同的数据项时,会使用排他锁,或叫互斥锁,先进入的事务独占数据项以后,其他事务被阻塞,等待前面的事务释放锁。
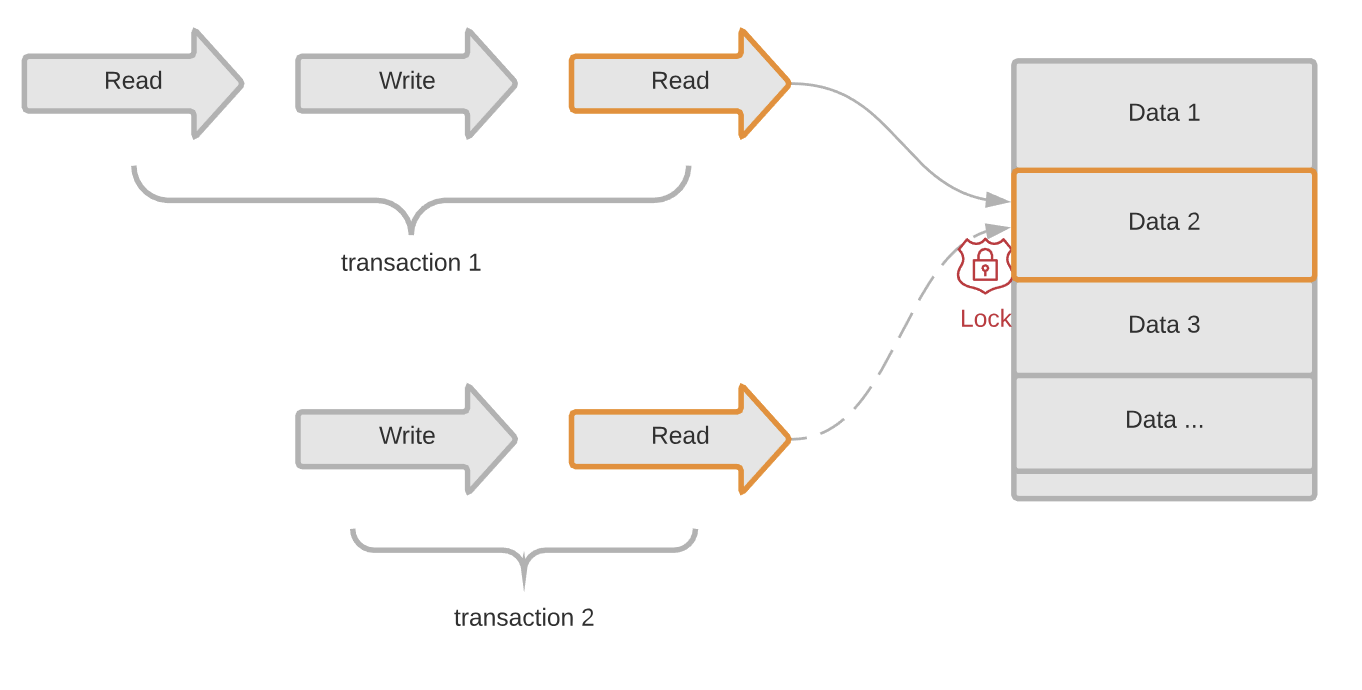
注意,在整个事务1结束之前,锁是不会被释放的,所以,事务2必须等到事务1结束之后开始。
并行+读写锁
采用了 并行+排他锁 以后,大幅提升了数据库事务处理效率,如果几个事务之间没有共享数据项,完全可以并行被处理,但,一些数据库大牛们显然对这个性能还不满足,进一步研究细化发现,所有的事务当中,对数据的操作无非是读和写排列组合的几种结果, 读读、写写、读写、写读 这4种情况的不断重复。
哪些操作之间可以相互兼容,或者共享呢?例如,读的时候为什么要阻止读呢?
所以,读写锁就应用而生了,进一步细化锁的颗粒度,区分读和写,让读和读之间不加锁,这样下面的俩个事务就可以同时被执行了。
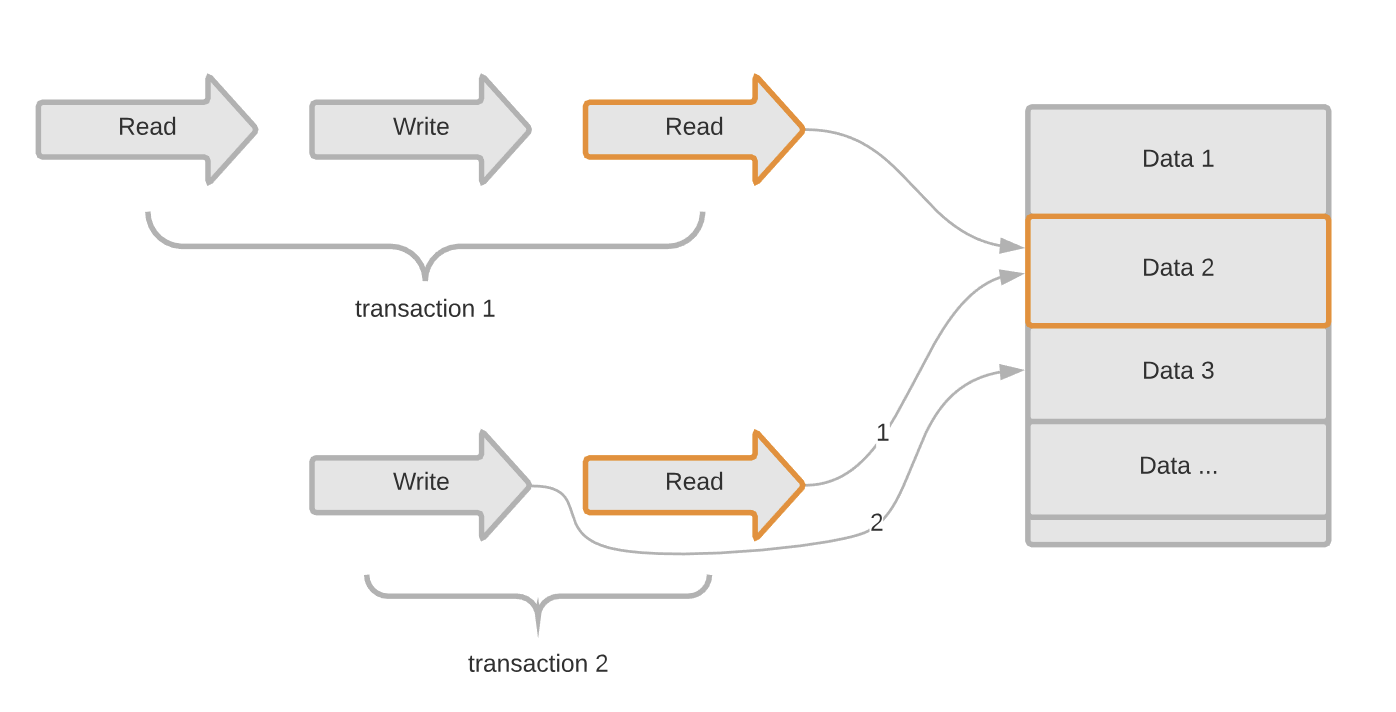
读写锁,可以让读和读并行,而读和写、写和读、写和写这几种之间还是要加排他锁。
MVCC
有人可能要说,优化到这个份上,已经差不多了吧,还有空间?
大牛们用行动告诉世人,答案是肯定的。
往往,确定一个模型不是最难的,难的是对这个模型实现的境界,大牛们会把自己的实现往死里优化,并行+读写锁 解决了读和读的并行,大牛们接下来要解决的是写和读、读和写,甚至写和写是否都可以并行!
这个技术就是现在大部分数据库在使用的事务处理技术,MVCC(Multi Version Concurrency Control),也就是Copy on Write的思想,对数据项进行多版本控制,一个精妙的想法,用空间换时间,进一步优化锁,减少锁。
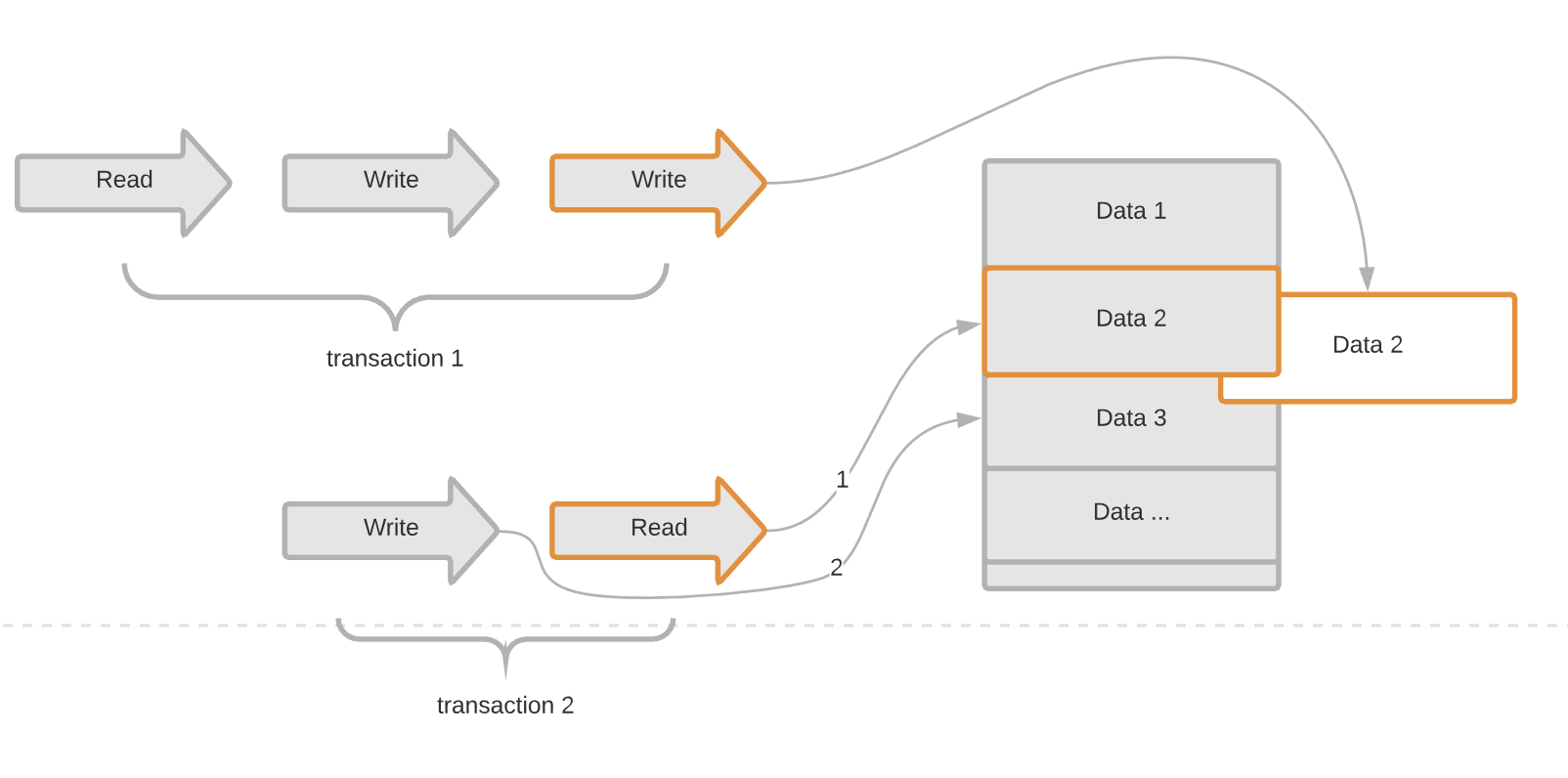
给每条记录增加版本号和删除俩个字段,在事务开始的时候copy一个新的版本,此时事务操作的实际上是一个副本,因此不会影响其他事务对此数据项的读操作,选择版本号最大的记录读取。
MVCC的好处,
- 除了支持读和读并行意外,可用让读和写并行、写和读并行,但,为了保证一致性,写和写是无法并行的。
- 大事务支持较好,之前的所有方案,因为锁的普遍存在,如果一个事务执行的时间太长,意味着后面的事务要长期等待,甚至超时,所以在之前,数据库一直建议不要维持大的数据库事务。
另外,MVCC支持读已提交 和 重复读俩种隔离级别,串行和读未提交都没有意义,一个必须要求排队执行,另一个要求必须读取最新数据。
小结
人类对速度的激情是没有最快,只有更快。
所以,以上方案的演变,本质是速度上的逐步提升的过程,到目前MVCC为止,在数据库层面能做的事情已经不多了。
进一步,如何解决写和写冲突的问题,这里提供俩个思路
- 乐观锁,适合于资源争抢不太严重的场景,由业务层控制,增加一个字段记录读取时的状态,更新是判断是否与读取时的状态一致,决定是否进行写操作,避免发生写操作冲突;
- BASE理论(Basically Available[基本可用],Soft State[软状态]和Eventually Consistent[最终一致]),数据库完全放开一致性要求,出现冲突,由用户决定,类似于Git Merge合并冲突的解决机制,我们后面单独撰文解读。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号