Elasticsearch索引与mapping映射
索引操作
创建索引
es创建索引的请求方式如下:
PUT /<index>- 请求的方法用PUT。
- /后面直接跟索引的名称即可。
- 索引的设置和字段都放在Body中。
比如我们创建一个名字叫组织机构的索引,这个索引只有两个字段,一个id,一个name。并且这个索引设置为2个分片,2个副本。
我们使用Postman发送请求,如下:
http://localhost:9200/orgnization请求的方法选择PUT。然后在请求体(Body)中,写上索引的字段名称,索引的分片数和副本数,如下:
{
"settings":{
"number_of_shards":2,
"number_of_replicas":2
},
"mappings":{
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"text"
}
}
}
}我们观察一下,请求体中分为两个部分:settings和mappings。在settings中,我们设置了分片数和副本数。
- number_of_shards:分片的数量;
- number_of_replicas:副本的数量;
在mappings中,我们设置索引的字段,在这里,我们只设置了id和name,id的映射类型是long,name的映射类型是text。
请求体写完后,我们点击发送,es返回的结果如下:
{
"acknowledged": true,
"shards_acknowledged": true,
"index": "orgnization"
}说明索引创建成功,索引的名字正是我们在请求中设置的orgnization。
然后,我们通过elasticsearch-head插件观察一下刚才创建的索引
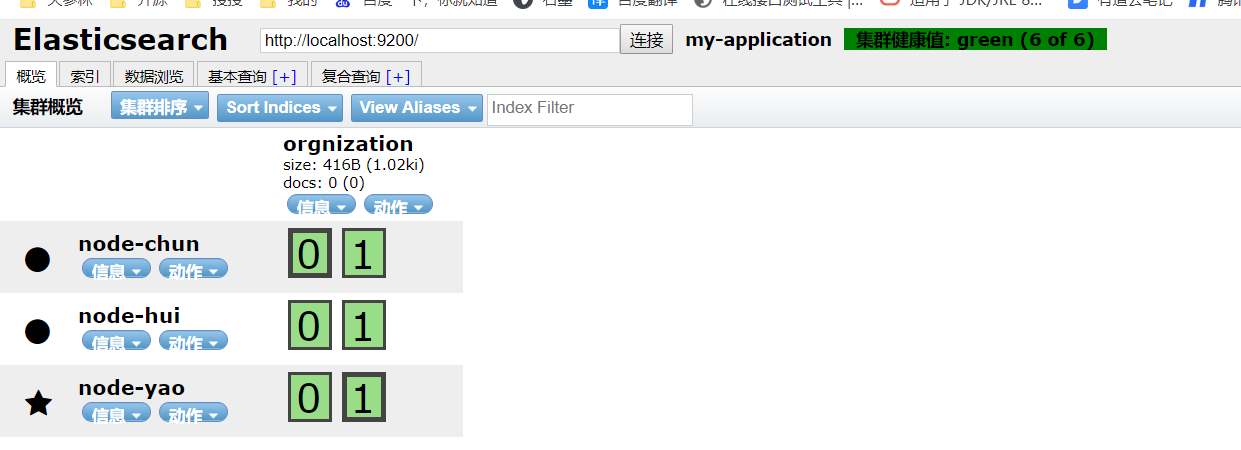
我们可以看到索引orgnization已经创建好了,它有2个分片,分别是0和1,并且每个分片都是两个副本。如果我们仔细观察这个图,可以看出node-chun节点中的0分片,和node-yao节点中的1分片,它们的边框是加粗的,这说明它们是主节点,而边框没有加粗的节点是从节点,也就是我们说的副本节点。
查看索引
如果我们要查看一个索引的设置,可以通过如下请求方式:
GET /<index>在我们的例子中,查看orgnization索引的设置,我们在Postman中发送如下的请求:
{
"orgnization": {
"aliases": {},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text"
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "2",
"provided_name": "orgnization",
"creation_date": "1636182188268",
"number_of_replicas": "2",
"uuid": "93U8-D3FSf2ZsVveV6uPUw",
"version": {
"created": "7100299"
}
}
}
}
}我们可以看到索引的具体设置,比如:mapping的设置,分片和副本的设置。这些和我们创建索引时候的设置是一样的。
修改索引
索引一旦创建,我们是无法修改里边的内容的,比如说修改索引字段的名称。但是我们是可以向索引中添加其他字段的,添加字段的方式如下:
PUT /<index>/_mapping然后在我们的请求体中,写好新添加的字段。比如,在我们的例子当中,新添加一个type字段,它的类型我们定义为long,请求如下:
http://localhost:9200/orgnization/_mapping请求类型要改为PUT,请求体如下:
{
"properties": {
"type": {
"type": "long"
}
}
}添加索引字段成功,我们再使用GET查看一下索引,如图:
{
"orgnization": {
"aliases": {},
"mappings": {
"properties": {
"id": {
"type": "long"
},
"name": {
"type": "text"
},
"type": {
"type": "long"
}
}
},
"settings": {
"index": {
"routing": {
"allocation": {
"include": {
"_tier_preference": "data_content"
}
}
},
"number_of_shards": "2",
"provided_name": "orgnization",
"creation_date": "1636182188268",
"number_of_replicas": "2",
"uuid": "93U8-D3FSf2ZsVveV6uPUw",
"version": {
"created": "7100299"
}
}
}
}
}我们可以成功的查询到新添加的索引字段了。
删除索引
如果我们要删除一个索引,请求方式如下:
DELETE /<index>假如我们要删除刚才创建的orgnization索引,我们只要把请求的方法改成DELETE,然后访问我们索引就可以
http://localhost:9200/orgnization关闭索引
如果索引被关闭,那么关于这个索引的所有读写操作都会被阻断。索引的关闭也很简单,请求方式如下:
POST /<index>/_close在我们的例子中,如果要关闭索引,将请求方法改成POST,然后发送如下请求:
http://localhost:9200/orgnization/_close打开索引
与关闭索引相对应的是打开索引,请求方式如下:
POST /<index>/_open在我们的例子中,如果要打开索引,将请求方法改成POST,然后发送如下请求:
http://localhost:9200/orgnization/_open冻结索引
冻结索引和关闭索引类似,关闭索引是既不能读,也不能写。而冻结索引是可以读,但是不能写。冻结索引的请求方式如下:
POST /<index>/_freeze对应我们的例子当中:
http://localhost:9200/orgnization/_freeze解冻索引
与冻结索引对应的是解冻索引,方式如下:
POST /<index>/_unfreeze对应我们的例子:
http://localhost:9200/orgnization/_unfreezeSetting配置
setting为ES索引的配置属性,索引的配置项按是否可以更改分静态(static)属性与动态配置。
静态配置即索引创建后不能修改,静态配置只能在创建索引时或者在状态为 closed index的索引(闭合的索引)上设置。
索引静态配置
index.number_of_shards 主分片数,默认为5。只能在创建索引时设置,不能修改。
index.shard.check_on_startup 是否在索引打开前检查分片是否损坏,当检查到分片损坏将禁止分片被打开。可选值:false:不检测;checksum:只检查物理结构;true:检查物理和逻辑损坏,相对比较耗CPU;fix:类同与false,7.0版本后将废弃。默认值:false。
index.codec 数据存储的压缩算法,默认算法为LZ4,也可以设置成best_compression,best_compression压缩比较好,但存储性能比LZ4差。
index.routing_partition_size 路由分区数,默认为 1,只能在索引创建时设置。此值必须小于index.number_of_shards,如果设置了该参数,如果设置了该参数,其路由算法为: (hash(_routing) + hash(_id) % index.routing_parttion_size ) % number_of_shards。如果该值不设置,则路由算法为 hash(_routing) % number_of_shardings,_routing默认值为_id。
索引动态配置
index.refresh_interval 执行刷新操作的频率,这使得索引的最近更改可以被搜索。默认为 1s。可以设置为 -1 以禁用刷新。
index.max_result_window 用于索引搜索的 from+size 的最大值。默认为 10000。
index.max_docvalue_fields_search 一次查询最多包含开启doc_values字段的个数,默认为100。
index.number_of_replicas 每个主分片的副本数,默认为 1,该值必须大于等于0
index.auto_expand_replicas 基于可用节点的数量自动分配副本数量,默认为 false(即禁用此功能)
index.blocks.read_only 设置为 true 使索引和索引元数据为只读,false 为允许写入和元数据更改。
index.max_rescore_window 在搜索此索引中 rescore 的 window_size 最大值
index.blocks.read_only_allow_delete 与index.blocks.read_only基本类似,唯一的区别是允许删除动作。
index.blocks.write 设置为 true 可禁用对索引的写入操作。
index.blocks.read 设置为 true 可禁用对索引的读取操作
index.blocks.metadata 设置为 true 可禁用索引元数据的读取和写入。
index.max_refresh_listeners 索引的每个分片上可用的最大刷新侦听器数。
对于已存在的索引,我们想要修改它的动态配置,可以使用_settings方法。
PUT /test_setting/_settings
{
"number_of_replicas": "0"
}mapping配置
通常索引的 Mapping 结构可以在创建索引时由 ElasticSearch 帮我们自动构建,字段类型由 ElasticSearch 自动推断,但这样做有一些问题,比如字段类型推断不准确,默认所有字段都会构建倒排索引等,自定义Mapping就可以解决上述这些问题。
我们创建了索引,在创建索引的时候,我们指定了mapping属性,mapping属性中规定索引中有哪些字段,字段的类型是什么。在mapping中,我们可以定义如下内容:
- 类型为String的字段,将会被全文索引;
- 其他的字段类型包括:数字、日期和geo(地理坐标);
- 日期类型的格式;
- 动态添加字段的映射规则;
字段的可用类型如下:
- 简单的类型,比如:text(分词),keyword(不分词),date,long,double,boolean,ip。我们可以看到,类型当中没有String,字符串的类型是text,所有text类型的字段都会被全文索引。数字类型有两个,long(长整型)和double(浮点型)。
- JSON的层级类型:Object(对象)和Nested(数组对象)。Object类型时,该字段可以存储一个JSON对象;Nested类型时,该字段可以存储一个数组对象。
- 复杂的类型:包括 geo_point、geo_shape和completion。
索引的创建需要配置mapping与setting两部分。基本格式:
{
"mappings":{
"_all":{
"enabled":false #默认情况,ElasticSarch自动使用_all所有的文档的域都会被加到_all中进行索引。可以使用"_all" : {"enabled":false} 开关禁用它。如果某个域不希望被加到_all中,可以使用"include_in_all":false关闭
},
"properties":{
"uuid":{
"type":"text",
"copy_to":"_search_all", #对应_search_all字段,可以对其进行全文检索
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":150 #ignore_above 默认值是256,当字段文本的长度大于指定值时,不做倒排索引。
}
}
},
"name":{
"type":"text",
"copy_to":"_search_all",
"analyzer":"ik_max_word", # ik_max_word 插件会最细粒度分词
"search_analyzer":"ik_smart", # ik_smart 粗粒度分词
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":150
}
}
},
"dt_from_explode_time":{
"type":"date",
"copy_to":"_search_all",
"format":"strict_date_optional_time||epoch_millis"
},
"_search_all":{
"type":"text"
}
},
"date_detection":false, #关闭日期自动检测,如果开启,会对于设置为日期格式的字段进行判断
"dynamic_templates":[ #用于自定义在动态添加field的时候自动给field设置的数据类型
{
"strings":{
"match_mapping_type":"string",
"mapping":{
"type":"text",
"copy_to":"_search_all",
"fields":{
"keyword":{
"type":"keyword",
"ignore_above":150
}
}
}
}
}
]
},
"settings":{
"index":{
"number_of_shards":6, #分片数量
"number_of_replicas":1 #副本数量
}
}
}常用数据类型
text、keyword、number、array、range、boolean、date、geo_point、ip、nested、object。
- text:默认会进行分词,支持模糊查询(5.x之后版本string类型已废弃,请大家使用text)。
- keyword:不进行分词,默认开启doc_values来加速聚合排序操作,占用了大量磁盘io 如非必须可以禁用doc_values。
- number:如果只有过滤场景 用不到range查询的话,使用keyword性能更佳,另外数字类型的doc_values比字符串更容易压缩。
- range:对数据的范围进行索引,目前支持 number range、date range 、ip range。
- array:es不需要显示定义数组类型,只需要在插入数据时用’[]‘表示即可。[]中的元素类型需保持一致。
- boolean: 只接受true、false,也可以是字符串类型的“true”、“false”。
- date:支持毫秒、根据指定的format解析对应的日期格式,内部以long类型存储。
- geo_point:存储经纬度数据对。
- ip:将ip数据存储在这种数据类型中,方便后期对ip字段的模糊与范围查询。
- ested:嵌套类型,一种特殊的object类型,存储object数组,可检索内部子项。
- object:嵌套类型,不支持数组。
{
"mappings": {
"properties": {
"price": {
"type": "long"
},
"color": {
"type": "keyword"
},
"brand": {
"type": "keyword"
},
"sold_date": {
"type": "date", // 使用date类型时要指定format,否则在使用range查询+时间表达式now/d等时,会特别坑爹
"format":"yyyyMMdd"
}
}
}
}其他参数:
"field": {
"type": "text", //文本类型 ,指定类型
"index": "false"// ,设置成false,字段将不会被索引
"analyzer":"ik"//指定分词器
"boost":1.23//字段级别的分数加权
"doc_values":false//对not_analyzed字段,默认都是开启,analyzed字段不能使用,对排序和聚合能提升较大性能,节约内存,如果您确定不需要对字段进行排序或聚合,或者从script访问字段值,则可以禁用doc值以节省磁盘空间:
"fielddata":{"loading" : "eager" }//Elasticsearch 加载内存 fielddata 的默认行为是 延迟 加载 。 当 Elasticsearch 第一次查询某个字段时,它将会完整加载这个字段所有 Segment 中的倒排索引到内存中,以便于以后的查询能够获取更好的性能。
"fields":{"keyword": {"type": "keyword","ignore_above": 256}} //可以对一个字段提供多种索引模式,同一个字段的值,一个分词,一个不分词
"ignore_above":100 //超过100个字符的文本,将会被忽略,不被索引
"include_in_all":ture//设置是否此字段包含在_all字段中,默认是true,除非index设置成no选项
"index_options":"docs"//4个可选参数docs(索引文档号) ,freqs(文档号+词频),positions(文档号+词频+位置,通常用来距离查询),offsets(文档号+词频+位置+偏移量,通常被使用在高亮字段)分词字段默认是position,其他的默认是docs
"norms":{"enable":true,"loading":"lazy"}//分词字段默认配置,不分词字段:默认{"enable":false},存储长度因子和索引时boost,建议对需要参与评分字段使用 ,会额外增加内存消耗量
"null_value":"NULL"//设置一些缺失字段的初始化值,只有string可以使用,分词字段的null值也会被分词
"position_increament_gap":0//影响距离查询或近似查询,可以设置在多值字段的数据上火分词字段上,查询时可指定slop间隔,默认值是100
"store":false//是否单独设置此字段的是否存储而从_source字段中分离,默认是false,只能搜索,不能获取值
"search_analyzer":"ik"//设置搜索时的分词器,默认跟ananlyzer是一致的,比如index时用standard+ngram,搜索时用standard用来完成自动提示功能
"similarity":"BM25"//默认是TF/IDF算法,指定一个字段评分策略,仅仅对字符串型和分词类型有效
"term_vector":"no"//默认不存储向量信息,支持参数yes(term存储),with_positions(term+位置),with_offsets(term+偏移量),with_positions_offsets(term+位置+偏移量) 对快速高亮fast vector highlighter能提升性能,但开启又会加大索引体积,不适合大数据量用
}常用的有:
- type:field的类型。
- index:该field是否会被索引。
- analyzer:指定的分词器。
- doc_values:开启后对聚合入分组或排序有增益,默认开启。
mapping之date date_nanos
JSON没有date数据类型,但我们可以把以下类型的数据作为日期时间存入ES。
在ES的内部,这些数据都是按照毫秒数(长整型)存储的,只是它们展现形式有如下多种。
| 类型 | 说明 |
|---|---|
| 字符串 | 日期格式的字符串,如"2015-01-01"或"2015/01/01 12:10:30" |
| 长整型 | 从开始纪元(1970-01-01 00:00:00 UTC)开始的毫秒数 |
| 整型 | 从开始纪元(1970-01-01 00:00:00 UTC)开始的秒数 |
上面的UTC(Universal Time Coordinated) 叫做世界统一时间,中国大陆和 UTC 的时差是 + 8 ,也就是 UTC+8。在ES内部,时间以毫秒数的UTC存储。
1、日期格式
date的格式可以被指定的,如果没有特殊指定,默认格式是"strict_date_optional_time||epoch_millis"
这段话可以理解为格式为strict_date_optional_time或者epoch_millis
(1)什么是epoch_millis?
epoch_millis就是从开始纪元(1970-01-01 00:00:00 UTC)开始的毫秒数-长整型。
如下图,2020/8/31 14:57:56是我们常用的日期格式,它距离1970-01-01 00:00:00 有 1598857076000豪秒。所以可以用长整型1598857076000表示2020/8/31 14:57:56。

(2)什么是strict_date_optional_time?
strict_date_optional_time是date_optional_time的严格级别,这个严格指的是年份、月份、天必须分别以4位、2位、2位表示,不足两位的话第一位需用0补齐。
常见的格式有如下:
- yyyy
- yyyyMM
- yyyyMMdd
- yyyyMMddHHmmss
- yyyy-MM
- yyyy-MM-dd
- yyyy-MM-ddTHH:mm:ss
- yyyy-MM-ddTHH:mm:ss.SSS
- yyyy-MM-ddTHH:mm:ss.SSSZ
工作常见到是"yyyy-MM-dd HH:mm:ss",但是ES是不支持这格式的,需要在dd后面加个T,这个是固定格式。上面最后一个里大写的"Z"表示时区。
你就是想用yyyy-MM-dd HH:mm:ss?
date类型,还支持一个参数format,它让我们可以自己定制化日期格式。
比如format配置了“格式A||格式B||格式C”,插入一个值后,会从左往右匹配,直到有一个格式匹配上。
{
"mappings":{
"properties":{
"birthday":{
"type":"date",
"format":"yyyy-MM-dd HH:mm:ss||yyyy-MM-dd||epoch_millis"
}
}
}
}(3)date_nanos类型,支持纳秒
date类型支持到毫秒,如果特殊情况下用到纳秒得用date_nanos这个类型。
为索引自定义Mapping
语法结构:
{
"mappings": {
"properties": {
"age": {
"type": "integer"
},
"email": {
"type": "keyword"
},
"name": {
"type": "text"
}
}
}
}PUT http://localhost:9200/users。请求的方法我们要使用PUT,路径是我们的索引名称,请求体当中是我们为索引添加的字段和字段的类型。
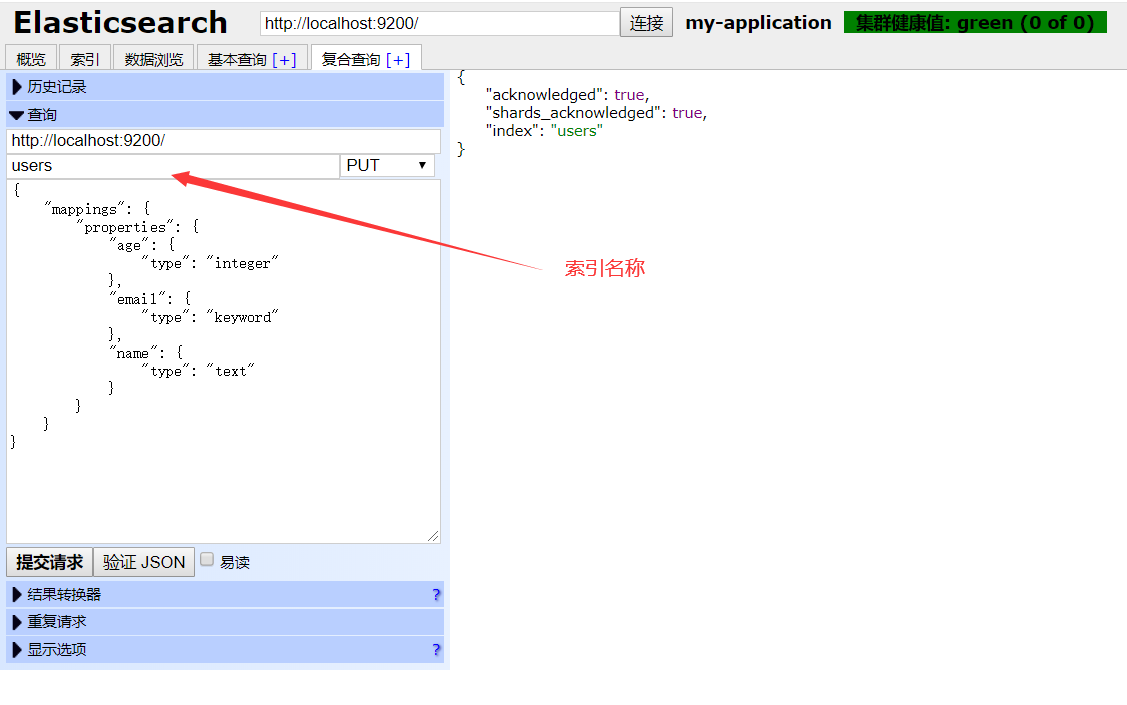
最佳实践
我们可以完全参考手册编写 Mapping ,但不建议这样做,容易出错,调试也麻烦,可以通过创建一个测试索引并插入测试文档,然后查看ElasticSearch为这个索引自动创建的Mapping,基于这个Mapping进行修改来构建我们自己的 Mapping。
在存在的映射中添加字段
正如上面所示,我们在一个索引中添加了字段,但是现在我们要补充额外的字段,这时,我们要怎么做呢?
PUT /users/_mapping
{
"properties": {
"employee-id": {
"type": "keyword",
"index": false
}
}
}
我们使用PUT方法,后面跟随我们的索引名称,再接上_mapping,请求体中是我们新添加的映射字段,我们指定了字段的类型为keyword,index索引为false,说明这个字段只用于存储,不会用于搜索,搜索这个字段是搜索不到的。
我们在更新字段时候,是不能修改字段的类型的。如果我们要修改字段的类型,最好是新建一个新的字段,指定正确的类型,然后再更新索引,以后我们只需要查询这个新增的字段就可以了。
查看索引中的字段映射
如果我们要查看已知索引的字段映射,可以向ES发送如下的请求:
GET /users/_mapping
请求的方法是GET,请求的路径是我们索引的名称my-index,再加上一个_mapping,得到的返回结果如下:
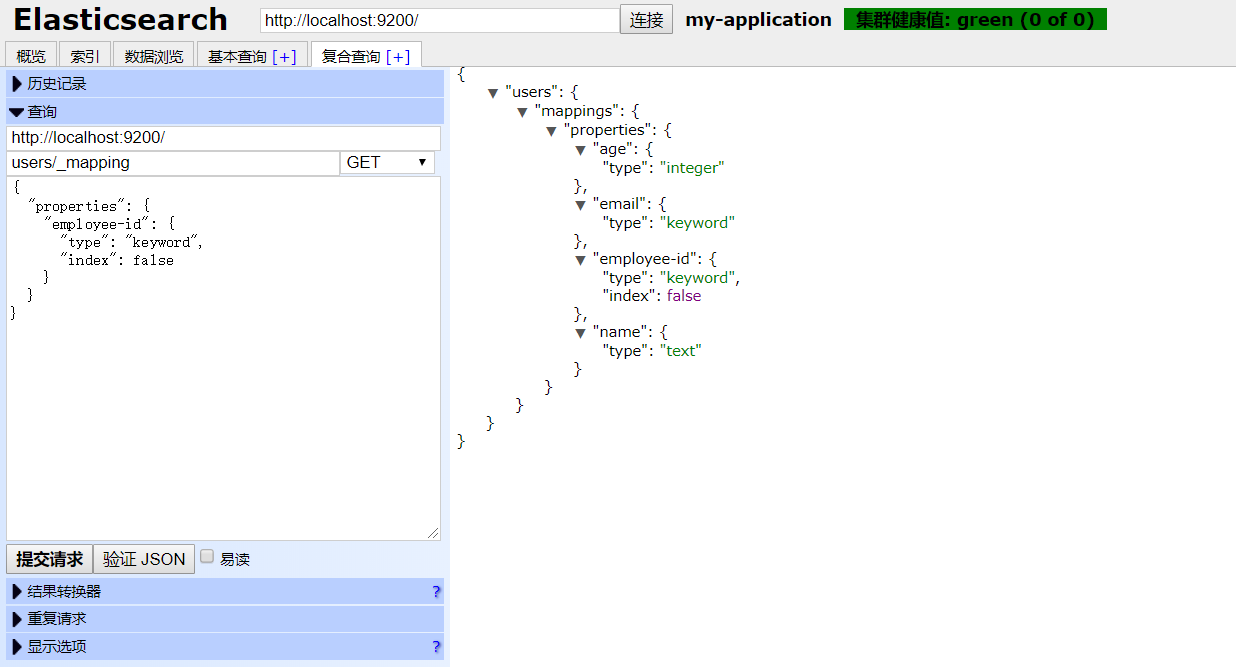
返回的结果中,我们可以看到索引的名称users,还有我们添加的字段,也包括后续补充的employee-id字段。
修改mapping中的字段类型
mapping中字段类型一旦设定后禁止直接修改。因为lucene实现的倒排索引生成后不允许修改,除非重建索引映射,然后做reindex操作。
以上面例子的索引orgnization为例。
(1)创建一个备份索引orgnization_bak
{
"settings":{
"number_of_shards":2,
"number_of_replicas":2
},
"mappings":{
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"text"
}
}
}
}(2) reindex操作
POST http://localhost:9200/_reindex请求体:
{
"source": {"index":"旧索引"},
"dest": {"index":"备份索引"}
}其中旧索引就是orgnization,备份索引是orgnization_bak。
(3)删除旧索引orgnization
(4)创建新索引orgnization,重新指定字段类型
{
"settings":{
"number_of_shards":2,
"number_of_replicas":2
},
"mappings":{
"properties":{
"id":{
"type":"long"
},
"name":{
"type":"keyword"
}
}
}
}(5)再reindex操作
POST http://localhost:9200/_reindex请求体为:
{
"source": {"index":"备份索引"},
"dest": {"index":"新索引"}
}此时的备份索引是orgnization_bak,新索引就是我们刚刚创建的orgnization。
注:在大数据量的情况,reindex操作不知道效率如何,慎用。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号