006-python各类数据函数用法
每个数据类型都有自己独有的“魔法”,即,每个数据数据类型都是自己独有的算法函数。不同类型数据函数的用法具有相通性,可类比学习和记忆。
一、数字
1. 1、int(x):将字符串格式的数据转换成整形,函数格式:int(x, base=10)
- x -- 需要进行转换字符串或数字。
- base -- 进制数,默认十进制。
示例展示:


#!/user/bin/env python #-*-coding:utf-8-*- # python3,数字只有整形,int #数据格式转换。将字符串x转换成整形。 a = '123' b = int(a) print(a,type(a)) print(b,type(b))
运行结果:
123 <class 's'>
123 <class 'int'>
1.2、x.bit_length():计算数字至少用几位二进制数来表示,函数格式:x.bit_length()
- x -- 需要进行转换字符串或数字。
示例展示:
age = 100 #将整形转化二进制 r = bin(age) #函数的大意:计算整形的二进数的位数(至少用几位来表示) v = age.bit_length() print(r) print(v)
运行结果:
0b1100100
7
1.3、bin(x):将整形转换成二进制数表示,函数格式:bin(x)
- x -- int 或者 long int 数字
示例展示:
age = 100 #将整形转化二进制 r = bin(age) print(r)
运行结果:
0b1100100
二、字符串
可迭代对象:通俗的理解是能够被for进行循环获取的对象。
1.重要且经常使用的函数(“6个基础魔法”+“4个灰魔法”)
***************基础常用魔法****************
1.1、s.join():用于将序列中的元素以指定的字符连接生成一个新的字符串,函数格式:s.join(sequence)
- sequence--是要连接的字符串或者元素序列
(有两种编写方式)
#!/user/bin/env python # -*-coding:utf-8-*- test2 = 'admin' v1 = '*'.join(test2) v2 = str.join(test2,'111') print(v1) print(v2)
运行结果:
a*d*m*i*n
1admin1admin1
1.2、s.lower():将字符串中所有的大写字母转化成小写格式,函数格式:lower(self)
(备注:lower() 方法只对ASCII编码,也就是‘A-Z’有效)
- 参数:无
1.3、s.upper():将字符串中所有的字母转化成大写格式,函数格式:lupper(self)
- 参数:无
1.4、s.split():将字符串以指定的分隔符进行切片处理,函数格式:s.split(self,sep,maxsplit)
- sep -- 作为分隔符的元素,包括空格、换行(\n)、制表符(\t)等。
- maxsplit -- 分割次数。默认为 -1, 即分隔所有。
1.5、s.find():检测字符串中是否包含子字符串 sub ,如果指定 start(开始) 和 end(结束) 范围,那在指定的范围内搜索该子字符串。如果有,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。函数格式:s.find(self, sub, start=None, end=None)【index的用法与其一样,只是sub搜索不到会报异常】
- sub -- 指定检索的字符串
- start -- 开始索引,默认为0。
- end -- 结束索引,默认为字符串的长度。
s.rfind():从字符串的右边开始检测字符串中是否包含子字符串 sub ,如果指定 start(开始) 和 end(结束) 范围,那在指定的范围内搜索该子字符串。如果有,返回的是索引值在字符串中的起始位置。如果不包含索引值,返回-1。函数格式:s.rfind(self, sub, start=None, end=None)【rindex的用法与其一样,只是sub搜索不到会报异常】
- sub -- 指定检索的字符串
- start -- 开始索引,默认为0。
- end -- 结束索引,默认为字符串的长度。
1.6、s.sip():【删首尾】去除字符串首尾的指定字符串chars,机理是从字符串s两侧向中心搜索子字符串chars,并去掉,当遇到第一次到不是chars就结束。函数格式:s.sip(self,chars)
- chars -- 用于搜索并且去除的子字符串
s.lsip():【删左】去除字符串左边的指定字符串chars,机理是从字符串s左侧向右侧搜索子字符串chars,并去掉,当遇到第一次到不是chars就结束。函数格式:s.ltrip(self,chars)
- chars -- 用于搜索并且去除的子字符串
s.rsip():【删右】去除字符串右边的指定字符串chars,机理是从字符串s右侧向左侧搜索子字符串chars,并去掉,当遇到第一次到不是chars就结束。函数格式:s.rtrip(self,chars)
- chars -- 用于搜索并且去除的子字符串
***************灰魔法(其他数据类型也能用)****************
1.7、s[num]:【搜索】通过下标进行搜索,搜索字符串中的某一个字符,并且取出相对应的字符。函数格式:s[num]
- num -- 下标
1.8、s[num1:num2]:【切片】范围为>=num1 ;<num2,获取两个下标之间的字符串。函数格式:s[num1:num2]
- num1:num2 -- 为下标区间
1.9、len():计算字符串的字符长度。函数格式:len(s)
- s -- 用于统计的字符串
2.0、for 变量名 in 字符串:将字符串一个字一个字逐行展示。
函数格式:
for 变量名 in 字符串 print(变量名)
- 变量名 -- 随意的变量,值为对应下标的字符
- 字符串 -- 用于逐行展示的字符串
2.1、range():帮助创建连续的数字,也通过设置步长,来创建不连续的数字。函数格式:range(self,start,stop,step)
- start -- 开始创建的数字
- stop -- 结束创建的数字
- step -- 步长
test = range(0,100) test1 = range(0,100,5) for v in test: print(v) for v1 in test1: print(v1)
运行结果:逐行打印0到99。
*习题:将客户输入的内容的索引打印出来。【思路:计算输入字符串的长度(len函数),根据长度创建连续的数字(range函数),利用for循环函数以及字段搜索函数(s.[mum]),将他们打印出来。】
#!/user/bin/env python # -*-coding:utf-8-*- test = input('请输入相应的内容:') l = len(test) #计算字符的长度 r = range(l) #创建连续的索引 for item in r: print(item,test[item]) #通过下标搜索对应的字符
运行结果:
请输入相应的内容:admin 0 a 1 d 2 m 3 i 4 n
2.字母大小写切换相关函数
2.1、s.capitalize():将字符串的首字母(第一个)变成大写,函数格式:capitalize(self)
- 参数:无
s.title():将字符串中所有的单词拼写首字母变成大写,且其他字母都变为小写。s.title(self)
- 参数:无
2.2、s.casefold():将字符串中所有的大写字母转化成小写格式。函数格式:casefold(self)
(备注:对于所有字母均有效)
- 参数:无
2.3、s.lower():将字符串中所有的大写字母转化成小写格式,函数格式:lower(self)
(备注:lower() 方法只对ASCII编码,也就是‘A-Z’有效)
- 参数:无
1.4、s.upper():将字符串中所有的字母转化成大写格式,函数格式:lupper(self)
- 参数:无
2.5、s.swapcase():将字符串中的字符进行大小交换,即大写变成小写,小写变成大写。函数格式:swapcase(self)
- 参数:无
2.6、s.islower():判断字符串中所有字符串是否全为小写,如果全是小写,返回值为True,反之为Flase。函数格式:s.islower(self)
- 参数:无
2.7、s.isupper():用于判断字符串中所有字符是否全为大写。如果全为大写,返回值为True,反之为Flase。函数格式:s.isupper(self)
- 参数:无
填充对齐类型
3.1、s.center():设置宽度,并且将字符串内容居中显示,并且在空白处填内容或者无填充。函数格式:s.center(self,width,fillchar)
- width -- 表示宽度的大小,
- fillchar --- 表示空白处填充的内容,可以填入一个字符。
s.ljust(): 返回一个原字符串左对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。函数格式:s.ljust(self,width,fillchar)
- width -- 指定字符串长度。
- fillchar -- 填充字符,默认为空格。
s.rjust(): 返回一个原字符串右对齐,并使用空格填充至指定长度的新字符串。如果指定的长度小于原字符串的长度则返回原字符串。函数格式:s.rjust(self,width,fillchar)
- width -- 指定字符串长度。
- fillchar -- 填充字符,默认为空格。
s.zfill():返回指定长度的字符串,原字符串右对齐,前面填充0。函数格式:s.zfill(self,width)
- width -- 指定字符串长度。
统计编码
3.2、s.count():用统计字符sub在字符串中出现的次数, start(开始) 和 end(结束)用于指定 范围。函数格式:s.count(self, sub, start=None, end=None)
- sub -- 用于搜索统计的字符
- start -- 统计的开始,默认是0
- end -- 统计结束,默认是字符串的长度
3.3、s.encode():【编码】采用指定的编码格式,对字符串进行编码。函数格式:s.encode(self,encoding,errors)
- encoding -- 要使用的编码,如: UTF-8。
- errors -- 设置不同错误的处理方案。默认为 'sict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
3.4、s.decode():【解码】采用指定编码格式,对字符串进行解码。函数格式为:s.decode(self,encoding,errors)
- decoding -- 要使用的编码,如: UTF-8。
- errors -- 设置不同错误的处理方案。默认为 'sict',意为编码错误引起一个UnicodeError。 其他可能得值有 'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通过 codecs.register_error() 注册的任何值。
字符类型判断的函数
1)、s.startwith():判断字符串是否以指定字符或者字符序列开头,是的返回True,反之返回Flase。函数格式:s.startwith(self,prefix, start, end)
- prefix -- 字符串的前缀
- start -- 开始搜索,默认是0
- end -- 结束结束,默认是字符串的长度
2)、s.endtwith():判断字符串是否以指定字符或者字符序列开头,是的返回True,反之返回Flase。函数格式:s.endwith(self,suffix, start, end)
- suffix -- 字符串的后缀
- start -- 开始搜索,默认是0
- end -- 结束结束,默认是字符串的长度
s.istitle():检测字符串中所有的单词拼写首字母是否为大写,且其他字母为小写,是的话返回True,反之返回Flase。函数格式:s.istitle()
- 参数:无
2.6、s.islower():判断字符串中所有字符串是否全为小写,如果全是小写,返回值为True,反之为Flase。函数格式:s.islower(self)
- 参数:无
2.7、s.isupper():用于判断字符串中所有字符是否全为大写。如果全为大写,返回值为True,反之为Flase。函数格式:s.isupper(self)
- 参数:无
字符构成判断函数
s1 in s2:判断字符串s1是否在字符串s2中,在的话返回True,反之返回Flase。函数格式:s1 in s2
- s1 -- 用于检测判断的字符或者字符序列(下列示例中的“i”、“am”)
- s2 -- 用于检测判断的字符串。(下列示例中的“admin”)
test = 'admin' v = 'i' in test v1 = 'am' in test print(v) print(v1) #运行结果 True False
3)、s.isalnum():检测字符串是否由字母和数字组成。至少有一个字符并且所有字符都是字母或数字,是的话返回True,反之返回Flase。函数格式:s.isalnum()【这个函数感觉有点问题】
- 参数:无
4)、s.isalpha():检测字符串是否只由字母或文字组成,至少有一个字符并且所有字符都是字母或文字,是的话返回True,反之返回Flase。函数格式:s.isalpha()
- 参数:无
5)、s.isdigit():检测字符串是否只由数字组成,至少有一个字符并且所有字符都是数字,是的话返回True,反之返回Flase。函数格式:s.isdigit()
- 参数:无
6)、s.isnumeric():检测字符串是否只由数字组成,数字可以是: Unicode 数字,全角数字(双字节),罗马数字,汉字数字。
- 参数:无
7)、s.isspace():检测字符串是否只由空格组成,至少有一个字符并且所有字符都是空格,是的话返回True,反之返回Flase。函数格式:s.isspace()
- 参数:无
7)、s.isdecimal():检查字符串是否只包含十进制字符,是的话返回True,反之返回Flase。函数格式:s.isdecimal()
- 参数:无
不了解部分
s.isidentifier():标识符
s.isprintable():可打印
替换类型的函数
3.7、s.expandtabs():把字符串中的 tab 符号('\t')转为空格,tab 符号('\t')默认的空格数是 8。函数格式:s.expandtabs(self,tabsize)
- tabsize -- 指定转换字符串中的 tab 符号('\t')转为空格的字符数
srt.format():【字符串格式化】将{}以及其中的内容进行替换。函数格式:srt.format(sub1=‘admin’,sub2=‘alex’,..)
name = input('请输入您的名字:') site = input('请输入地点:') interest = input('请输入兴趣:') v1 = '敬爱可亲的{name1} ,喜欢在{site1}{interest1}' v2 = v1.format_map({'name1':name,'site1':site,'interest1':interest}) v3 = v2.format(name1 = name,site1 = site,interest1 = interest) print(v2) print(v3)
s.format_map():【字符串格式化】将{}以及其中的内容进行替换。函数格式:s.format_map({'sub1':‘admin’,'sub2':‘alex’,....})【相当于从字典中获取字段】
name = input('请输入您的名字:') site = input('请输入地点:') interest = input('请输入兴趣:') v1 = '敬爱可亲的{name1} ,喜欢在{site1}{interest1}' v2 = v1.format_map({'name1':name,'site1':site,'interest1':interest}) print(v2)
s.maketrans():【制作翻译表】用于创建字符映射的转换表,函数格式:s.maketrans(intab, outtab)
- intab -- 字符串中要替代的字符组成的字符串。
- outtab -- 相应的映射字符的字符串。
s.translate():【翻译】根据参数table给出的表(包含 256 个字符)转换字符串的字符,要过滤掉的字符放到 deletechars 参数中。
- table -- 翻译表,翻译表是通过 maketrans() 方法转换而来。
- deletechars -- 字符串中要过滤的字符列表。
s.maketrans()与s.translate()示例:
#!/usr/bin/python3 intab = "aeiou" outtab = "12345" trantab = str.maketrans(intab, outtab) # 制作翻译表 str = "this is string example....wow!!!" print (str.translate(trantab))
运行结果:
th3s 3s s3ng 2x1mpl2....w4w!!!
s.replace():把字符串中的 old(旧字符串) 替换成 new(新字符串),如果指定第三个参数count,则替换不超过 count次。函数格式:s.replace(self,old,new,count)
- old -- 将被替换的子字符串。
- new -- 新字符串,用于替换old子字符串。
- count -- 可选字符串, 替换不超过 count 次,该字符串中,被替换的字符的个数有多少个,默认是全部替换。
分隔分块的函数
s.partiton():用指定的分隔符将字符串进行分割,如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。函数格式:s.patiion(self,sep)
- sep -- 指定的分隔符
s.rpartiton():从右边开始搜索分隔符,用指定的分隔符将字符串进行分割,如果字符串包含指定的分隔符,则返回一个3元的元组,第一个为分隔符左边的子串,第二个为分隔符本身,第三个为分隔符右边的子串。函数格式:s.rpatiion(self,sep)
- sep -- 指定的分隔符
s.split():将字符串以指定的分隔符进行切片处理,函数格式:s.split(self,sep,maxsplit)
- sep -- 作为分隔符的元素,包括空格、换行(\n)、制表符(\t)等。
- maxsplit -- 分割次数。默认为 -1, 即分隔所有。
s.splitlines():按照行('\r', '\r\n', \n')分隔,返回一个包含各行作为元素的列表,如果参数 keepends 为 False,不包含换行符,如果为 True,则保留换行符。函数格式:s.splitlines(self,keepends)
- keepends -- 在输出结果里是否去掉换行符('\r', '\r\n', \n'),默认为 False,不包含换行符,如果为 True,则保留换行符。
s.rsplit():将字符串以指定的分隔符进行切片处理,函数格式:s.rsplit(self,sep,maxsplit)【具体的作用还有待考证】
- sep -- 作为分隔符的元素,包括空格、换行(\n)、制表符(\t)等。
- maxsplit -- 分割次数。默认为 -1, 即分隔所有。
三、表格 list
1、列表基本概念
- 列表格式:所有元素都用中括号[ ]括起来,[1,2.'admin']
- 列表元素:列表中的元素可以是任何数据类型,数字、字符串、布尔值、列表....等。所有都可以放进去。
- 元素分隔符:所有元素之间用“,”分隔,(英文格式)【根据经验最后一个元素后面也要加“,”】
- 列表特性:列表中的元素可以修改。
***重要猜想概念:列表的构成与for循环是密不可分的。某个对象转换成列表,相当于先进行for循环,然后再将对应的元素放进去。
列表类型数据存储的链表原理示意图
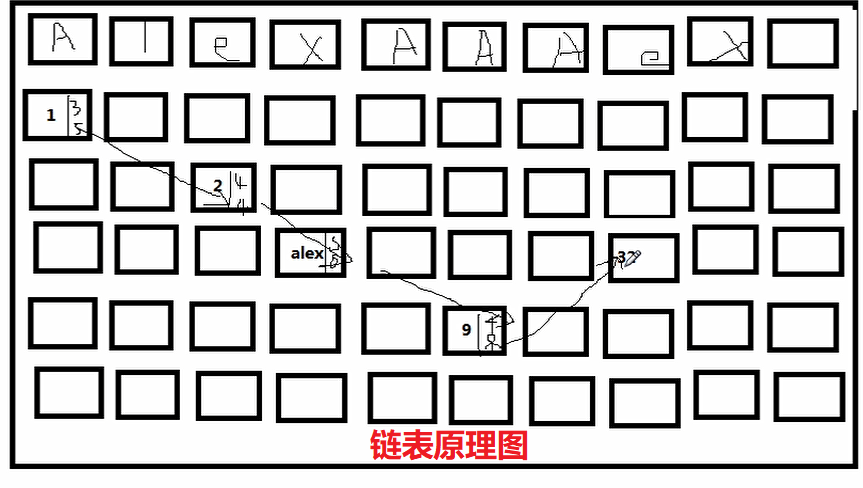
2、基础功能(取值、修改、删除)
1、列表取值方法
1.1、li[num]:【索引取值】通过下标进行搜索,搜索列表中的某一个元素,并且取出相对应的元素。函数格式:li[num]
- num -- 下标
**特殊:li[num][num1][num2]..[numn]:找到列表某个元素列表中的某个元素(备注:主要用来列表中嵌套着多次层列表)
#!/user/bin/env python # -*-coding:utf-8-*- # 获取多种列表嵌套的列表li中的“12” li = [1, 2, ['admin', [6, 7, 8, [11, 12, 13]], 4, 5]] li1 = li[2][1][3][1] print(li1)
1.2、li[num1:num2]:【切片取值】范围为>=num1 ;<num2,获取两个下标之间的列表子序列。函数格式:li[num1:num2]
- num1:num2 -- 为下标区间
1.3、for 变量名 in 列表名:【for循环取值】将列表元素一个元素一个元素逐行展示。
函数格式:
for 变量名 in 列表名 print(变量名)
- 变量名 -- 随意的变量,值为表格中对应下标的元素
- 列表名 -- 用于逐行展示的列表,展示列表元素
1.4、li.inder():找到对应的值或元素的索引位置,函数格式:li.inder(self,object,start,stop)
- object -- 指定查找的元素
- start -- 指定查找的开始位置
- stop -- 指定查找的结束位置
2、修改列表元素
2.1、li[num] = [ num]:【索引修改】通过下标进行搜索,搜索列表中的某一个元素,并且取出相对应的元素。函数格式: li[num] = [ sub]
- num -- 下标
- sub -- 替换的元素,可以是任何数据类型,数字、字符串、布尔值、列表....等。所有都可以放进去。
2.2、li[num1:num2] = [num,s,list,...]:【切片修改】范围为>=num1 ;<num2,获取两个下标之间的列表子序列。函数格式:li[num1:num2] = [num,s,list,...]
- num1:num2 -- 为下标区间
- num,s,list,... -- 替换的多个元素
3、删除列表元素
3.1、del li[num] :【索引删除】通过下标进行搜索,搜索列表中的某一个元素,并且取出相对应的元素。函数格式:del li[num]
- num -- 下标
3.2、del li[num1:num2] :【切片删除】范围为>=num1 ;<num2,获取两个下标之间的列表子序列。函数格式:del li[num1:num2]
- num1:num2 -- 为下标区间
3.3、li.pop():移除指定索引位置的元素,并且获取被删除的值,函数格式:list.pop(inder)
- inder -- 需要删除的索引位置
3.4、li.remove():移除指定的元素,函数格式:list.remove(sub)
- sub -- 需要删除的列表元素
3.5.li.clear():清空列表的元素。函数格式:list.clear()
- 参数 -- 无
4、元素构成判断
li in list1:判断列表元素li是否在列表list1中,在的话返回True,反之返回Flase。函数格式:li in list1
- li -- 用于检测判断的字符或者字符序列(下列示例中的“i”、“am”)
- list1 -- 用于检测判断的字符串。(下列示例中的“admin”)
list1 = [1,2,'admin',[0,1],True]#列表 v = 1 in list1 v1 = 20 in list1 print(v) print(v1) #运行结果 True False
5、转换功能(字符串转成列表)
5.1、li():将其他数据类型转换成列表类型。函数类型:li(s)
- s -- 用于转换的元素(该元素所对应的数据类型要支持for循环)
test = "admin" new_li = list(test) print(new_li) #运行结果 ['a', 'd', 'm', 'i', 'n'] test1 = 123 new_li1 = list(test1) print(new_li1) #运行结果 new_li1 = list(test1) TypeError: 'int' object is not iterable
6、元素增加功能
6.1、li.append():在列表最后插入对应的元素。函数格式:li.append(self,object)
- object -- 用于添加的元素,包括数字、字符串、列表、元组、字典。
6.2、li.extend():扩展原表,参数为可迭代对象。li.extend(self,sterable)
- sterable -- 用于扩展原表的元素,元素必须可迭代的对象。
6.3、li.insert():在指定的索引位置插入指定的元素。函数格式:li.insert(self,inder,object)
- inder -- 指定的索引位置
- object -- 指定的元素,可以为任何数据格式的值
7、其他功能
7.1、li.copy():复制指定表格的内容。函数格式:li.copy()
- 参数 -- 无
7.2、li.count():统计计算列表中某个元素出现的次数,函数格式:li.count(self,object)
- object -- 指定的元素,可以为任何数据格式的值
7.3、len():计算列表的字符长度(总个数)。函数格式:len(li)
- li -- 用于统计的列表
8、元素排序功能
8.1、li.reverse():将列表元素前后调换(翻转),重新排列。函数格式:li.reverse(self)
- 参数 -- 无
8.2、li.sort():对列表中的元素进行排序(只对数字有效)。函数格式:li.sort(self,key,reverse)
- key--
- reverser -- 布尔值(True为从小到大,Flase为从大到小)
四、元组
1、元组基本概念
- 元组格式:所有元素都用中括号()括起来,(1,2.'admin')
- 元组元素:元组中的元素可以是任何数据类型,数字、字符串、布尔值、列表....等。所有都可以放进去。
- 元素分隔符:所有元素之间用“,”分隔,(英文格式)
- 元组特性:元组中的第一级元素不能进行修改、添加、删除。
- 元组的元素是有序排列的。
2、函数功能
1、列表取值方法
1.1、tu[num]:【索引取值】通过下标进行搜索,搜索元组中的某一个元素,并且取出相对应的元素。函数格式:tuple[num]
- num -- 下标
**特殊:tu[num][num1][num2]..[numn]:找到列表某个元素列表中的某个元素(备注:主要用来列表中嵌套着多次层列表)
#!/user/bin/env python # -*-coding:utf-8-*- # 获取多种数据嵌套的元组tu中的“12” tu = (1, 2, ['admin', [6, 7, 8, [11, 12, 13]], 4, 5]) tu1 =tu[2][1][3][1] print(tu1)
1.2、tu[num1:num2]:【切片取值】范围为>=num1 ;<num2,获取两个下标之间的元组子序列。函数格式:tu[num1:num2]
- num1:num2 -- 为下标区间
1.3、for 变量名 in 元组名:【for循环取值】将元组元素一个元素一个元素逐行展示。
函数格式:
for 变量名 in 元组名 print(变量名)
- 变量名 -- 随意的变量,值为表格中对应下标的元素
- 列表名 -- 用于逐行展示的列表,展示列表元素
1.4、tu.inder():找到对应的值或元素的索引位置,函数格式:tu.inder(self,object,start,stop)
- object -- 指定查找的元素
- start -- 指定查找的开始位置
- stop -- 指定查找的结束位置
2、统计功能
2.1、tu.count():统计计算元组中某个元素出现的次数,函数格式:tu.count(self,object)
- object -- 指定的元素,可以为任何数据格式的值
2.2、len():计算元组的字符长度(总个数)。函数格式:len(tu)
- tu -- 用于统计的元组
3、转换
3.1、可迭代对象之间的转换
4、元素构成判断
4.1、tu in tuple1:判断列表元素li是否在列表list1中,在的话返回True,反之返回Flase。函数格式:tu in tuple1
- tu -- 用于检测判断的字符或者字符序列(下列示例中的“i”、“am”)
- tuple1 -- 用于检测判断的字符串。(下列示例中的“admin”)
tuple1 = (1,2,'admin',[0,1],True,)#元组 v = 1 in tuple1 v1 = 20 in tuple1 print(v) print(v1) #运行结果 True False
五、字典
1、字典基本概念
- 元组格式:所有元素都用中括号{ }括起来,{'1':'2','k1':admin'}
- 元组元素:由键key值对构成,
- “键key”中的元素只能是不能修改的元素,类型为数字、字符串、布尔值、元组。【键key必须是唯一,如果重复了只能保留一个】
- “值”中的元素可以是任何数据类型,数字、字符串、布尔值、列表....等。所有都可以放进去。
- 每个键key值(key=>value)对用冒号(:)分割,
- 元素分隔符:所有元素(键key值对)之间用“,”分隔,(英文格式)
- 字典的元素是无序排列的。
2、基础函数功能
1、字典取值方法
1.1、dic[key]:【索键key取值】:通过键key获取字典中对应的值。函数格式:dic[key]【如果输入的键key不存在,系统报错】
- key -- 键key值
**特殊:dic[num][num1][num2]..[numn]:找到字典中某个元素中的某个元素(备注:主要用来列表中嵌套着多次层数据类型)
1.2、for 变量名 in 字典名:【for循环取值】将字典中元素(键key值对)一个元素(键key值对)一个元素(键key值对)逐行展示。【不支持while循环】
函数格式:
for 变量名 in 字典名 print(变量名)
#字典默认的for循环,其实对键进行循环,依次输出键 for item in info(): print(item) #对键进行循环,依次输出键 for item in info.keys(): print(item) #对值进行循环,依次输出值 for item in info.values(): print(item) #对键值进行循环,获取对应键的值,输出键和值 for item in info.keys(): print(item,info[item]) #获取字典的键值进行循环,赋给v,以元组的形式展示 for v in info.items(): print(v,type(v)) #获取字典的键值进行循环,把键赋给k,把值发给v,输出k,v for k,v in info.items(): print(k,v)
- 变量名 -- 随意的变量,值为表格中对应键key值的元素
- 字典名 -- 用于逐行展示的列表,展示列表元素
1.3、dic.get(key):通过键key获取字典中对应的值。当查看的键key不存在的时候,默认赋的值为None。函数格式:dic.get(key,values)
- key -- 键key
- values -- 当查看的键key不存在的时候,赋的值。
dic = { 'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin' } v1 = dic.get('k1', 12345) v2 = dic.get('k1111', 12345) print('key存在的情况:',v1) print('key不存在的情况:',v2) #输出结果 key存在的情况: 12 key不存在的情况: 12345
1.4、获取字典的键key、值value、键值对item。详见例子
info = { 'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin' } v1 = info.keys() v2 = info.values() v3 = info.items() v4 = dict(info.items()) print('1获取key:', v1) print('2获取value:', v2) print('3获取键值对:', v3) print('4获取键值对:', v4) #运行结果 1获取key: dict_keys(['k1', 'k2', 'k3', 'k4']) 2获取value: dict_values([12, [12, 13, [1, 2, 3]], 12, 'admin']) 3获取键值对: dict_items([('k1', 12), ('k2', [12, 13, [1, 2, 3]]), ('k3', 12), ('k4', 'admin')]) 4获取键值对: {'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin'}
2、字典修改方法
2.1、dic[key] = sub:【索键key修改】通过键key进行搜索,搜索字典中的某一个键key值对,对该键key对应的值进行修改。函数格式:dic[key] = sub
- key -- 键key
- sub -- 替换的内容,可以是任何数据类型,数字、字符串、布尔值、列表....等。所有都可以放进去。
2.2、dic.update():通过键值对对字典进行更新,当键key存在时,对原有的值进行替换,当键不存在时,添加对应的键值对。函数格式如例子所见。
info = { 'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin' } # 第一种写法 info.update({'k1': 456, 'k5': 789}) print(info) # 第二种写法 info.update(k1=456, k5=789) print(info) #运行结果: {'k1': 456, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin', 'k5': 789}
3、字典删除操作
3.1、del dic[key] :【索键key删除】通过键key值进行搜索,删除字典中的某一个元素,并且取出相对应的元素。函数格式:del dic[key]
- key -- 键key
**特殊:del dic[num][num1][num2]..[numn]:找到字典中某个元素中的某个元素(备注:主要用来列表中嵌套着多次层数据类型)
3.2、dic.clear():清空列表的元素。函数格式:dic.clear()
- 参数 -- 无
3.3、dic.pop():通过指定的键key,删除对应的值,并且获取到该值。当指定的键key不存在时,默认获取d的值为None。函数格式:dic.pop(self, k, d=None)
- k -- 键key
- d -- 当查看的键key不存在的时候,赋的值,默认为None。
info = { 'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin' } v2 = info.pop('k1111', 12345) print('key不存在的情况:', info, v2) v1 = info.pop('k1', 12345) print('key存在的情况:', info, v1) #运行结果 key不存在的情况: {'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin'} 12345 key存在的情况: {'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin'} 12
3.4、dic.popitem():随机删除字典中的一个键值对,并且获取到这个键值对的值。函数格式:dic.popitem()
- 参数 -- 无
info = { 'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin' } v = info.popitem() print('字典:', info, ' 值:', v) #运行结果 字典: {'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12} 值: ('k4', 'admin')
4、元素(键key值对)增加
4.1、dic.setdefault():通过键key对字典内的值进行设置,当键key存在,不设置值,并且获取当前的值;当键key不存在,设置值value,添加一个键值对,并且获取值value。函数格式:dic.setdefault(self,k,value)
- k -- 键key
- value -- 当键key不存在的时候,赋的值,默认为None
info = { 'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin' } v = info.setdefault('k1',456) v1 = info.setdefault('k111',456) print('key存在的情况:', info, v) print('key不存在的情况:', info, v1) #运行结果 key存在的情况: {'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin', 'k111': 456} 12 key不存在的情况: {'k1': 12, 'k2': [12, 13, [1, 2, 3]], 'k3': 12, 'k4': 'admin', 'k111': 456} 456
5、数据类型转换功能
6、其他功能
6.1、len(dic) 【元素统计】计算字符串的键key值对(总数)。函数格式:len(dic)
- dic -- 用于统计的字典
6.2、dic.copy():复制指定字典中的内容。函数格式:dic.copy()
- 参数 -- 无
3、字典高级功能(直接用类来操作)
1、dict.fromkeys():根据指定的序列(可迭代对象),作为键key创建字典,并且赋上统一的值。函数格式:dict.fromkeys(seq,values)
- seq -- 可迭代对象,作为键key
- values -- 赋的值
七、集合
1.集合基本概念
- 元组格式:用{ }表示,{1,2,3,},
- 元组元素:
- 元素必须需不同
- 由不能改变的数据类型组成。数字、字符串、布尔值、元组
- 元素分隔符:所有元素之间用“,”分隔,(英文格式)
- 集合的元素是无序排列的。
- 集合特性:有去重的功能
2、集合基础功能
1、集合创建
1.1、可变集合的创建:se = {iterable}或者se = set(object)
- iterable -- 可迭代对象
#!/user/bin/env python # -*-coding:utf-8-*- se = {1, 2, 3, 'admin'} print(se) se1 = set('admin') print(se1) #运行结果 {1, 2, 3, 'admin'} {'m', 'd', 'i', 'n', 'a'}
注意: 创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
se2 = set() #创建空集合 se3 = {} #创建空字典 print(se2, type(se2)) print(se3, type(se3)) #运行结果 set() <class 'set'> #空集合 {} <class 'dict'> #空字典
1.2、不可变集合创建:frozenset(iterable)
- iterable -- 可迭代对象
2、元素增加功能
2.1、se.add():在集合中添加对应的元素。函数格式:se.add(self,element)
- element -- 用于添加的元素(数字、字符串、布尔值、元组)
3、元素删减功能
3.1、se.clear():在集合中添加对应的元素。函数格式:se.clear(self)
- element -- 用于添加的元素(数字、字符串、布尔值、元组)
3.2、se.discard() :用于移除指定的集合元素,如果移除的元素存在,则进行移除操作,如果不存在,则无操作并不会报错。函数格式:se.discard(self,element)
- element -- 必需,要移除的元素
3.3、se.remove() :用于移除指定的集合元素,如果移除的元素存在,则进行移除操作,如果不存在,则无操作并会报错。函数格式:se.remove(self,element)
- element -- 必需,要移除的元素
3.3、se.pop():随机删除集合中的元素。函数格式:se.pop(self)
- 参数 -- 无
4、其他功能
4.1、se.copy():复制指定集合中的内容。函数格式:se.copy()
- 参数 -- 无
3、集合运算功能
1、集合差运算 【左边有,右边没有】
1.1、se.difference():【a-b】 用于返回集合的差集,即返回的集合元素包含在第一个集合中,但不包含在第二个集合(方法的参数)中,函数格式:se.difference(self,s)
- s -- 用于计算差集的集合(作为减数的部分)
1.2、se.difference_update(): 用于移除两个集合中都存在的元素。在原来的集合删掉与第二个集合的相同部分。(更新原来的集合),函数格式:se.difference_update(self,s)
- s -- 用于计算差集的集合(作为减数的部分)
***特殊备注:difference_update() 方法与 difference() 方法的区别在于 difference() 方法返回一个移除相同元素的新集合,而 difference_update() 方法是直接在原来的集合中移除元素,没有返回值。
2、集合交运算 【两边共有】
2.1、se.intersection():【a&b】 用于返回集合的交集【两个集合的公共部分】,即返回的集合元素包含在第一个集合中,也包含在第二个集合(方法的参数)中,函数格式:se.intersection(self,s)
- s -- 用于计算交集的集合
2.2、se.intersection_update(): 用于移除两个集合中都存在的元素。在原来的集合删掉与第二个集合的相同部分。(更新原来的集合),函数格式:se.intersection_update(self,s)
- s -- 用于计算交集的集合(作为减数的部分)
***特殊备注:intersection_update() 方法与 intersection() 方法的区别在于 intersection() 方法返回两集合共同部分组成的新集合,而 difference_update() 方法是直接在原来的集合中去掉两个集合公共部分以外的元素,没有返回值。
3、集合并集 【两边全部】
3.1、se.union():【a|b】计算两个集合的并集,以新集合方式返回。函数格式:se.union(self,s)
- s -- 用于计算并集的集合
3.2、se.update():计算两个集合的并集,更新原来的集合。函数格式:se.update(self,s)
- s -- 用于计算并集的集合
4、对称差分 【去同留异】【两集合的并集减去交集】
4.1、se.symmetric_difference():【a^b】用于移除两个集合中都存在的元素,将剩下的部分组成新的集合。函数格式:se.symmetric_difference(self,s)
- s -- 用于计算的集合
4.2、se.symmetric_difference_update(): 用于移除两个集合中都存在的元素,在原来的集合删掉与第二个集合的相同部分。(更新原来的集合),函数格式:se.symmetric_difference_update(self,s)
- s -- 用于计算的集合
***特殊备注:symmetric_difference_update() 方法与 symmetric_difference() 方法的区别在于 symmetric_difference() 方法返回一个移除两个集合公共部分,剩下元素组成的新集合,而 symmetric_difference_update() 方法是直接在原来的集合中去除两个集合公共部分,将剩下元素写入集合中,没有返回值。
5、运算判断
5.1、se.isdisjoint():【不相交】如果两个集合之间的交集为空集合,返回值为True,反之,返回值为Flase。函数格式:se.isdisjoint(self,s)
- s -- 用于判断的集合
5.2、se.issubset():【子集】用于判断该集合是否是其他集合的子集(被包含),如果是返回值为True,反之,返回值为Flase。函数格式:se.issubset(self,s)
- s -- 用于判断的集合
5.3、se.issuperset():【父集】用于判断该集合是否是其他集合的父集(包含),如果是返回值为True,反之,返回值为Flase。函数格式:se.issuperset(self,s)
- s -- 用于判断的集合



 浙公网安备 33010602011771号
浙公网安备 33010602011771号