

分布式系统的核心问题一致性与共识
区块链系统是一个分布式系统,而分布式系统的首要问题是一致性的保障。
一致性
定义:一致性(consistency),早期也叫agreement,是指对于分布式系统中的多个服务节点,给定一系列操作,在约定协议的保障下,试图使得他们对处理结果达成“某种程度”的认同。
一致性并不代表结果正确与否,而是系统对外呈现的状态一致与否;例如,所有节点都达成失败状态也是一种一致。
将可能引发不一致的并行操作进行串行化 是现代分布式系统处理一致性问题的的基础思路。
事件的先后顺序十分重要,这也是解决分布式系统领域很多问题的核心秘诀:把多件事情进行排序,并且这个顺序还得是大家都认可的。
共识算法
共识(consensus)在很多时候会与一致性(consistency)术语放在一起讨论。严谨地讲,两者的含义并不完全相同。
一致性往往指分布式系统中多个副本对外呈现的数据的状态。共识则描述了分布式系统中多个节点之间,彼此对某个状态达成一致结果的过程。因此,一致性描述的是结果状态,共识则是一种手段。达成某种共识并不意味着就保障了一致性。
在实践中,要保障系统满足不同程度的一致性,核心过程往往需要通过共识算法来达成。共识算法解决的是对某个提案(proposal)大家达成一致意见的过程。
提案的含义在分布式系统中十分宽泛,比如多个事件发生的顺序、某个键对应的值、谁是领导等等。可以认为任何可以达成一致的信息都是一个提案。
对于分布式系统来讲,各个节点通常都是相同的确定性状态机模型,从相同的初始状态开始接收的相同顺序的指令,则可以保证相同的结果状态。因此,系统中多个节点最关键的是对多个事件的顺序进行共识,即排序。
问题
可惜的是现实中不存在这样的“理想”系统,问题一般包括:(1)出现故障(crash或fail-stop,即不响应)但不会伪造信息的情况称为“非拜占庭错误”(non-byzantine fault)或“故障错误”(Crash Fault);(2)伪造信息恶意响应的情况称为“拜占庭错误”(Byzantine Fault)。
常见算法
根据解决的是非拜占庭错误,共识算法可以分为Crash Fault Tolerance(CFT)类算法和Byzantine Fault Tolerance(BFT)类算法。
针对非拜占庭错误,有一些经典解决算法,包括Paxos、Raft及其变种等。这类容错算法性能比较好,容忍不超过一半的故障节点。
对于要能容忍拜占庭错误的情况,一般包括PBFT(Practical Byzantine Fault Tolerance)为代表的确定性系列算法、PoW为代表的概率算法等。对于确定性算法,一旦达成了对某个结果的共识就不可逆转,即共识的是最终结果;而对于概率类算法,共识结果则是临时的,随着时间的推移或某种强化,共识结果被推翻的概率越来越小,成为事实上的最终结果。拜占庭类容错算法往往性能比较差,容忍不超过1/3的故障节点。
FLP不可能原理
FLP不可能原理:在网络可靠,但允许节点失效(即便只有一个)的最小化异步模型系统中,不存在一个可以解决一致性问题的确定性共识算法。
先说一下什么是“同步”“异步”,同步是指系统中的各个节点的时钟误差存在上限;并且消息传递必须在一定时间内完成;否则认为失败;同时各个节点完成处理消息的时间是一定的。同步系统很容易判断消息是否丢失。异步是指系统中的各个节点可能存在较大的时钟差异,同时消息传输时间是任意长的,各个节点对消息进行处理的时间也可能是任意长的,就无法判断收不到消息响应式节点故障还是传输故障。
FLP不可能原理是否意味着研究共识算法没有意义?这只是学术界研究的最极端情形。
科学告诉你什么是不可能的;工程则告诉你,付出一些代价,可以把它变成可行。
在付出一些代价的情况下,我们在共识的达成上,能做到多好?回答这个问题的一个很有名的原理:CAP原理。
CAP原理
CAP原理:分布式计算系统不可能同时确保以下三个特性:一致性(consistency)、可用性(availability)和分区容忍性(partition)。
1)分区容忍性:网络可能发生分区,即节点之间的通信不可保障。
大多数分布式系统都分布在多个子网络。每个子网络就叫做一个区(partition)。比如,一台服务器放在中国,另一台服务器放在美国,这就是两个区,它们之间可能无法通信。

上图中,G1 和 G2 是两台跨区的服务器。G1 向 G2 发送一条消息,G2 可能无法收到。系统设计的时候,必须考虑到这种情况。
一般来说,分区容错无法避免,因此可以认为 CAP 的 P 总是成立。CAP 定理告诉我们,剩下的 C 和 A 无法同时做到。
2)一致性:任何操作应该都是原子的,发生在后面的事件能看到前面事件发生导致的结果,这指的是强一致性。
写操作之后的读操作,必须返回该值。举例来说,某条记录是 v0,用户向 G1 发起一个写操作,将其改为 v1。
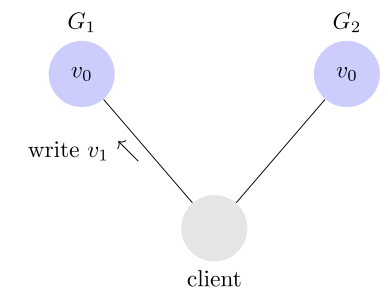
接下来,用户的读操作就会得到 v1。这就叫一致性。
问题是,用户有可能向 G2 发起读操作,由于 G2 的值没有发生变化,因此返回的是 v0。G1 和 G2 读操作的结果不一致,这就不满足一致性了。
为了让 G2 也能变为 v1,就要在 G1 写操作的时候,让 G1 向 G2 发送一条消息,要求 G2 也改成 v1。
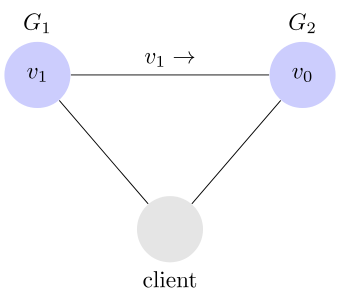
这样的话,用户向 G2 发起读操作,也能得到 v1。
3)可用性:在有限时间内,任何非失败节点都能应答请求。
只要收到用户的请求,服务器就必须给出回应。用户可以选择向 G1 或 G2 发起读操作。不管是哪台服务器,只要收到请求,就必须告诉用户,到底是 v0 还是 v1,否则就不满足可用性。
一致性和可用性,为什么不可能同时成立?答案很简单,因为可能通信失败(即出现分区容错)。
如果保证 G2 的一致性,那么 G1 必须在写操作时,锁定 G2 的读操作和写操作。只有数据同步后,才能重新开放读写。锁定期间,G2 不能读写,没有可用性不。
如果保证 G2 的可用性,那么势必不能锁定 G2,所以一致性不成立。
综上所述,G2 无法同时做到一致性和可用性。系统设计时只能选择一个目标。如果追求一致性,那么无法保证所有节点的可用性;如果追求所有节点的可用性,那就没法做到一致性。
应用场景
弱化一致性的场景,例如网站静态页面内容,实时性较弱的查询类数据库等对一致性不敏感的。
弱化可用性的场景,例如银行取款机,对一致性很敏感。
弱化分区容忍性,某些关系型数据库及ZooKeeper主要考虑这种设计。网络可以通过双通道等机制增强可靠性,达到高稳定的网络通信。
ACID原则
ACID原则指的是:Atomicity(原子性)、Consistency(一致性)、Isolation(隔离性)、Durability(持久性)。
这是比较有名的描述一致性的原则,通常出现在分布式数据库领域。满足一致性需求,但是允许付出可用性的代价。
A:每次操作是原子的,要么成功,要么不执行;
C:数据库的状态是一致的,无中间状态;
I:各种操作之间互不影响;
D:状态的改变是持久的,不会失效。
与ACID相对的一个原则是BASE(Basic Availability, Soft-state, Eventual Consistency)原则,牺牲对一致性约束(但实现最终一致性),来换取一定的可用性。
该文主要摘自:
《区块链原理、设计与应用》
http://www.ruanyifeng.com/blog/2018/07/cap.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号