

近年来,自然语言处理(NLP)领域因 BERT(Bidirectional Encoder Representations from Transformers)的横空出世迎来革命性突破。作为首个实现双向上下文建模的预训练语言模型,BERT 在多项 NLP 任务中刷新了记录,成为现代大模型的基石之一。
一、BERT 是什么?
BERT 是 Google 于 2018 年提出的预训练语言模型,其核心思想是通过大规模无监督预训练学习通用的语言表示,再通过微调(Fine-tuning)适配下游任务(如文本分类、问答等)。BERT 的关键突破在于:
- 双向上下文建模:传统模型(如 RNN、LSTM)只能单向编码文本,而 BERT 通过 Transformer 的注意力机制同时捕捉前后文信息。
- 预训练 + 微调范式:大幅减少针对特定任务的标注数据需求,实现“通用语言理解”。
二、核心原理与架构
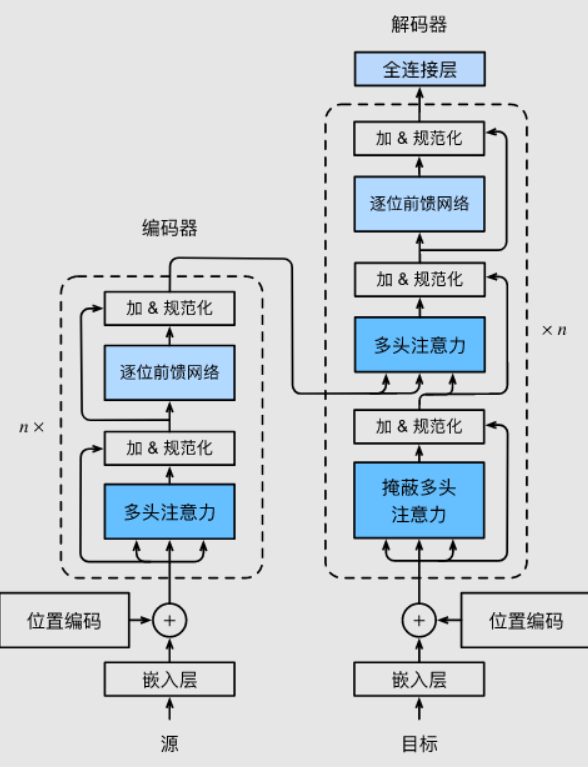
1. Transformer 编码器
BERT 完全基于 Transformer 编码器(舍弃解码器),其核心是多层自注意力(Self-Attention)机制:
- 自注意力层:计算词与词之间的关联权重,动态捕捉上下文依赖。
- 前馈网络(FFN):对每个位置的表示进行非线性变换。
- 残差连接与层归一化:缓解梯度消失,加速训练。
2. 预训练任务
BERT 通过两个无监督任务预训练模型:
- Masked Language Model(MLM):随机遮盖输入中 15% 的词汇,模型预测被遮盖的词(如:“我 [MASK] 北京” → “我 爱 北京”)。
- Next Sentence Prediction(NSP):判断两个句子是否为上下文关系(如:“句子A:今天天气好。句子B:适合去公园。” → 真)。
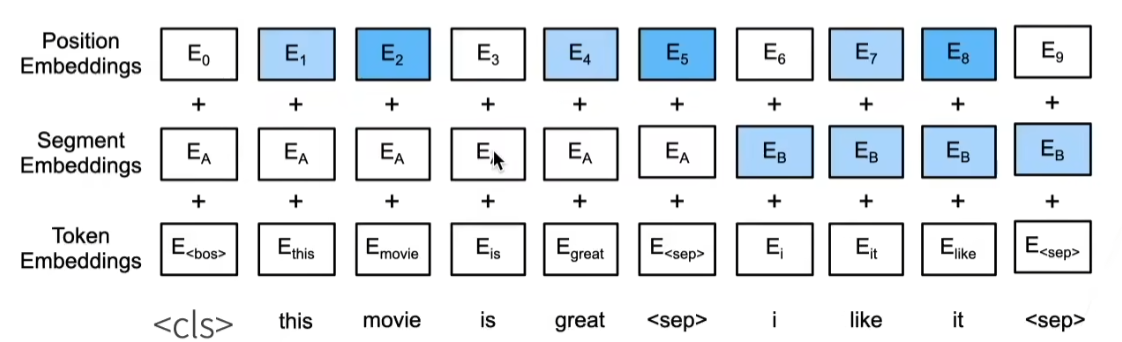
3. 输入表示
BERT 的输入由三部分嵌入拼接而成:
- 词嵌入(Token Embeddings):词汇的向量表示。
- 段嵌入(Segment Embeddings):区分句子对中的不同句子(用于 NSP 任务)。
- 位置嵌入(Position Embeddings):编码词汇的位置信息。
三、BERT 的核心优势
| 特性 | 说明 |
|---|---|
| 双向上下文建模 | 同时利用左右两侧的上下文信息,更准确理解语义(如“银行”指金融机构还是河岸)。 |
| 迁移学习能力 | 预训练模型可通过少量标注数据微调适配多种任务,降低训练成本。 |
| 多任务支持 | 统一处理分类、序列标注、问答等任务,无需定制化模型结构。 |
| 大规模语料训练 | 基于 Wikipedia 和 BooksCorpus(共 33 亿词)训练,覆盖广泛语言模式。 |
四、BERT 的应用场景
1. 文本分类
- 情感分析:判断评论的正负面情绪(如电商评价分类)。
- 垃圾邮件检测:识别垃圾邮件或恶意内容。
2. 问答系统(QA)
- 抽取式问答:从文本中定位答案(如 SQuAD 数据集任务)。
- 开放域问答:结合知识库生成答案。
3. 命名实体识别(NER)
- 识别文本中的人名、地点、组织等实体(如“马云是阿里巴巴的创始人” → 人名:马云,组织:阿里巴巴)。
4. 语义相似度计算
- 判断两句话是否表达相同含义(如“如何更换手机屏幕” vs “手机屏幕维修方法”)。
五、实践案例:基于 BERT 的文本分类
1. 环境准备
使用 Hugging Face 的 transformers 库快速调用预训练 BERT 模型:
pip install transformers torch
2. 加载预训练模型与分词器
from transformers import BertTokenizer, BertForSequenceClassification
tokenizer = BertTokenizer.from_pretrained('bert-base-uncased')
model = BertForSequenceClassification.from_pretrained('bert-base-uncased', num_labels=2) # 二分类
3. 数据预处理
texts = ["I love this movie!", "This film is terrible..."]
labels = [1, 0] # 1: 正面, 0: 负面
# 分词并编码为模型输入
inputs = tokenizer(texts, padding=True, truncation=True, return_tensors="pt")
labels = torch.tensor(labels)
4. 模型训练(简化示例)
import torch.optim as optim
optimizer = optim.AdamW(model.parameters(), lr=5e-5)
for epoch in range(3):
outputs = model(**inputs, labels=labels)
loss = outputs.loss
loss.backward()
optimizer.step()
optimizer.zero_grad()
print(f"Epoch {epoch}, Loss: {loss.item()}")
5. 推理预测
test_text = "This is an amazing experience!"
inputs_test = tokenizer(test_text, return_tensors="pt")
outputs = model(**inputs_test)
predicted_label = torch.argmax(outputs.logits).item() # 输出 1(正面)
六、BERT 的变体与演进
- RoBERTa:优化训练策略(更大批次、更长训练时间),移除 NSP 任务,性能显著提升。
- ALBERT:通过参数共享和嵌入分解减少模型体积,适合资源受限场景。
- DistilBERT:知识蒸馏技术压缩模型,保留 95% 性能的同时体积减小 40%。
- BERT 多语言版:支持 104 种语言,实现跨语言迁移学习。
七、BERT 的局限性
- 计算资源需求高:训练需大量 GPU 资源,实时推理延迟较高。
- 长文本处理缺陷:输入长度被限制(通常 512 Token),难以处理长文档。
- 领域适应性问题:通用预训练模型在专业领域(如医疗、法律)表现可能下降。
八、总结与展望
BERT 的诞生标志着 NLP 进入“预训练大模型”时代,其核心思想被后续模型(如 GPT、T5)继承并发展。尽管已有更强大的模型出现,BERT 仍因其平衡的性能与易用性,成为工业界和学术界的首选工具之一。未来,结合小样本学习、模型压缩和领域自适应的技术,BERT 的应用边界将进一步扩展。
进一步学习:
本文来自博客园,作者:茄子_2008,转载请注明原文链接:https://www.cnblogs.com/xd502djj/p/18879219

 浙公网安备 33010602011771号
浙公网安备 33010602011771号