

Oozie 慢慢退去,Airflow 来了。
一、Airflow 核心价值解析
1. 什么是工作流编排?
- 传统痛点:手工执行脚本 → 缺乏调度监控 → 依赖管理混乱
- Airflow解决方案:可视化DAG → 自动重试机制 → 依赖拓扑管理
2. 核心特性矩阵
| 特性 | 说明 | 典型应用场景 |
|---|---|---|
| DAG可视化 | 图形化展示任务拓扑 | 复杂ETL流程监控 |
| 可扩展Operator库 | 200+官方/社区Operator | 跨平台任务集成 |
| 任务历史追溯 | 精确到每次运行的日志记录 | 故障根因分析 |
| 弹性调度策略 | Cron语法+时间窗口设置 | 避开业务高峰时段 |
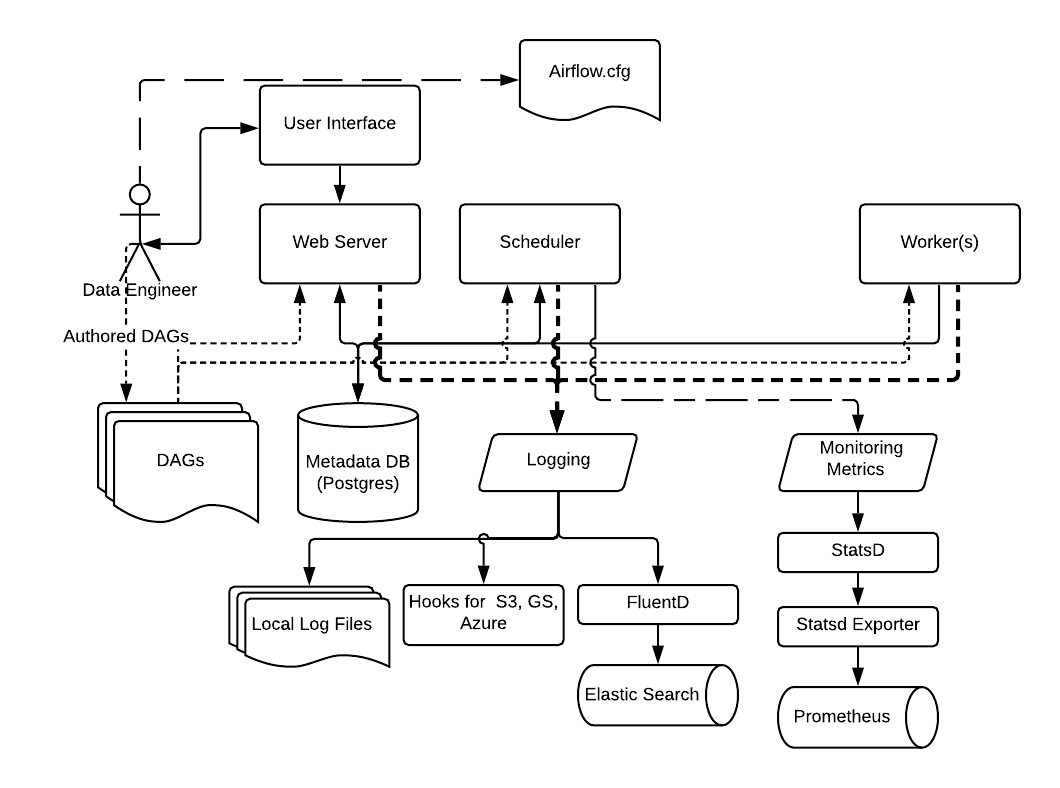
二、架构深度剖析
1. 组件协同原理
graph TD
A[Web Server] -->|元数据| B[Metadata DB]
C[Scheduler] -->|解析DAG| D[Worker Cluster]
B -->|存储状态| C
D -->|执行日志| B
E[Executor] -->|任务分发| D
2. 关键进程说明
- Scheduler:DAG解析引擎(使用BashOperator/PythonOperator时的代码解析器)
- Worker:任务执行容器(支持K8sExecutor/CeleryExecutor等分布式模式)
- Triggerer:事件驱动核心(2.3+版本新增的长时任务处理器)
三、实战开发指南
1. 环境快速部署
# 使用官方约束文件安装
pip install "apache-airflow[celery]==2.6.3" \
--constraint "https://raw.githubusercontent.com/apache/airflow/constraints-2.6.3/constraints-3.8.txt"
# 初始化元数据库
airflow db init
airflow users create --username admin --firstname John \
--lastname Doe --role Admin --email admin@example.com
# 启动服务集群
airflow webserver -D && airflow scheduler -D
2. 首个智能DAG开发
from datetime import datetime
from airflow import DAG
from airflow.operators.bash import BashOperator
from airflow.operators.python import PythonOperator
def _process_data(**context):
ti = context['ti']
raw_data = ti.xcom_pull(task_ids='extract')
return f"Processed {raw_data} at {datetime.now()}"
with DAG('data_pipeline',
schedule_interval='@daily',
start_date=datetime(2023, 1, 1),
catchup=False) as dag:
extract = BashOperator(
task_id='extract',
bash_command='echo "Raw data $(date)" > /tmp/raw.txt'
)
transform = PythonOperator(
task_id='transform',
python_callable=_process_data
)
load = BashOperator(
task_id='load',
bash_command='echo {{ ti.xcom_pull(task_ids="transform") }} > /tmp/final.txt'
)
extract >> transform >> load
3. 高级功能实现
# 动态DAG生成
def create_dag(dag_id, schedule, default_args):
with DAG(dag_id, schedule_interval=schedule, default_args=default_args) as dag:
t1 = PythonOperator(
task_id='dynamic_task',
python_callable=lambda: print(f"Running {dag_id}")
)
return dag
# 批量生成季度报表DAG
for quarter in ['Q1', 'Q2', 'Q3', 'Q4']:
dag_id = f'report_{quarter}'
globals()[dag_id] = create_dag(
dag_id,
'@monthly',
{'start_date': datetime(2023, 1, 1)}
)
四、企业级最佳实践
1. 安全加固方案
# airflow.cfg 关键配置
[core]
security = RBAC
secure_mode = True
hide_sensitive_variable_fields = True
[webserver]
secret_key = your_secure_key_here
2. 性能优化技巧
- DAG优化:使用
@task装饰器替代传统Operator - 并行控制:合理设置
parallelism和max_active_runs - 资源隔离:为Worker配置cgroups限制
3. 监控告警集成
# 自定义SLACK告警
def alert_on_failure(context):
slack_msg = f"""
:red_circle: Task Failed.
*Task*: {context.get('task_instance').task_id}
*Dag*: {context.get('dag').dag_id}
*Execution Time*: {context.get('execution_date')}
"""
SlackWebhookOperator(
task_id='slack_alert',
message=slack_msg
).execute(context)
# 应用到DAG
default_args = {
'on_failure_callback': alert_on_failure
}
五、生态全景图
| 组件 | 功能说明 | 典型集成案例 |
|---|---|---|
| Airflow Kubernetes Operator | K8s任务调度 | 大数据作业调度 |
| Astronomer | 商业托管平台 | 企业级SaaS解决方案 |
| AWS MWAA | 全托管服务 | 云原生部署 |
| Great Expectations | 数据质量监控 | 数据管道验证 |
六、适用场景评估
✅ 推荐使用场景
- 需要人工干预的混合工作流(审批节点)
- 跨多系统的数据管道(DB → S3 → Snowflake)
- 机器学习模型的全生命周期管理
❌ 不适用场景
- 毫秒级实时处理(考虑Flink/Kafka)
- 简单cron任务调度(系统自带工具更轻量)
- 无状态任务执行(直接使用Lambda函数)
扩展阅读推荐:
掌握Airflow就像为数据工程团队配备了一位智能调度指挥官,它不仅规范了工作流管理流程,更为数据驱动的决策提供了可靠保障。建议从简单ETL开始实践,逐步探索其强大的扩展能力。
本文来自博客园,作者:茄子_2008,转载请注明原文链接:https://www.cnblogs.com/xd502djj/p/18714923

 浙公网安备 33010602011771号
浙公网安备 33010602011771号