Introduction to Computer Systems
Hardware Architectures of Von Neumann
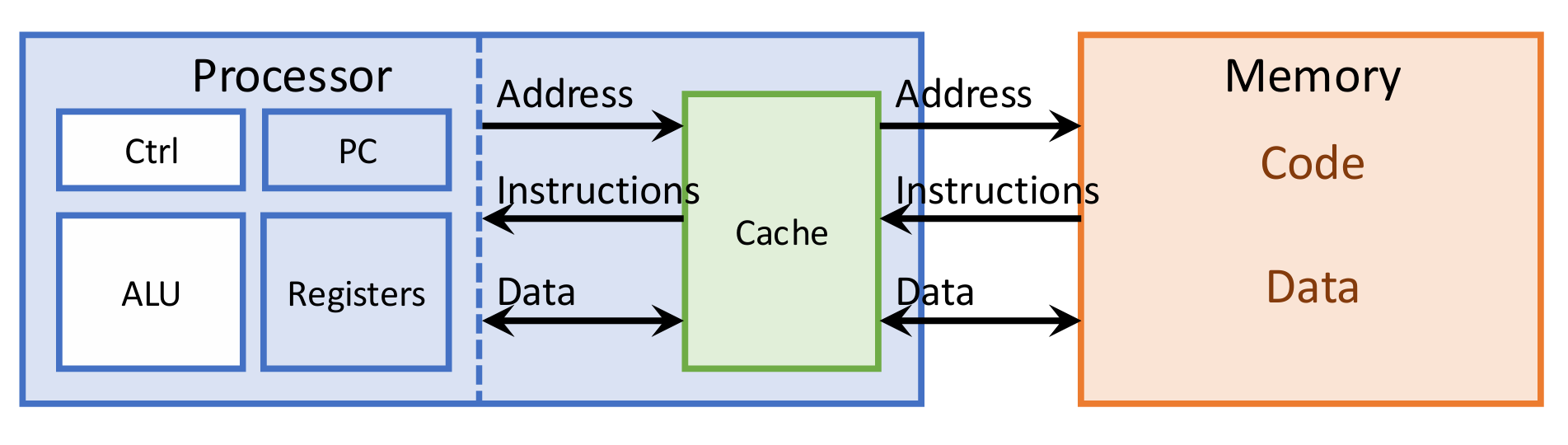
Processors and Assembly Code
Processors
state:
- Program counter (PC): address of the next instruction
- memory
- registers: local store of heavily used data in the processor (fsater than memory)
Break instruction execution into stages and implement them into hardware modules
- Fetch an instruction specified by PC and update the PC
- Decode the instruction and read operands from registers
- Execute an arithmetic/logic operation
- Load/store a value from/to memory if needed
- Write back the result to a register

Optimization 1: Pipelining
instruction-level parallelism

Optimization 2: Superscalar
also instruction-level parallelism

Optimization 3: Multi-Core
multiple levels of parallelism

Specialized/Customized Hardware
High efficiency but inflexible.
RISC-V
State
- PC: 32-bit
- Registers: x0-x31, each 32-bit. x0 is always 0
- Memory: 4-byte aligned
Instruction (32-bit long)
- Basic compute: arithmetic/logic/shift/compare
- Memory access: load/store
- Control flow: branch/jump




ISA (instruction set architecture)
software program -> ISA -> hardware processor. (abstraction)
two types:
- General-purpose/programmable processors: x86
- Specialized/customized accelerators: AI accelerators
ISA defines states and instructions.
two style:
- RISC: reduced instruction set computer. E.g. RISC-V.
- CISC: complex instruction set computer. E.g. x86.
ISA Support for Parallelism
SIMD (single-instruction, multiple-data)
Data-level parallelism
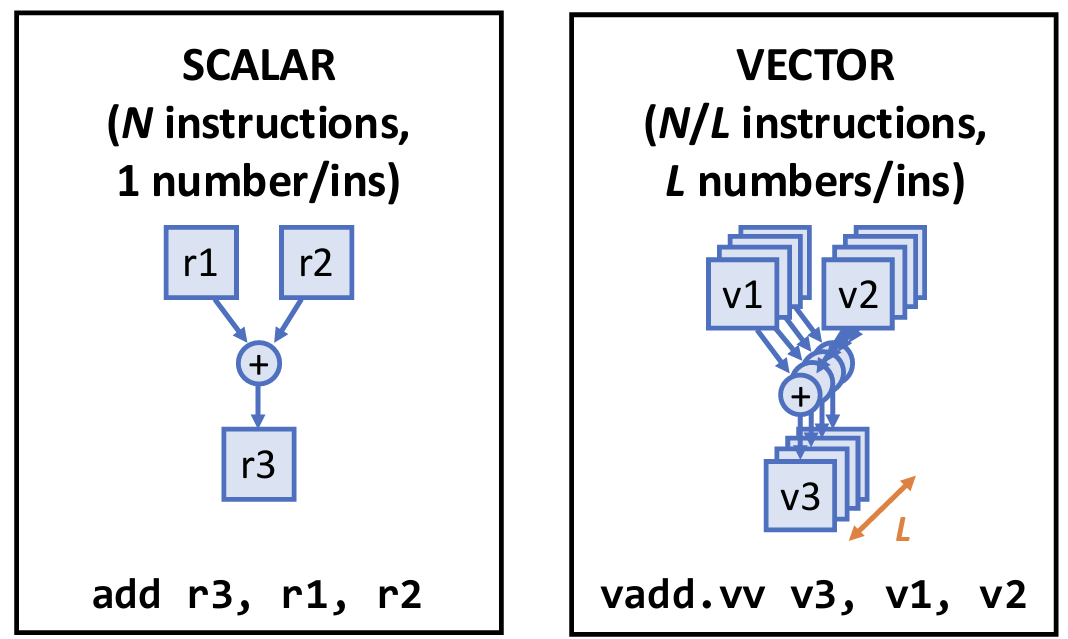
Multiple Levels of Parallelism

ISA Support for Synchronization
Avoid data races by synchronization of loads/stores to shared data
Atomic instructions
- Test and set
- Compare and swap
- Fetch and add/sub

Memory layout of a program


Memory Hierarchy
SRAM & DRAM
RAM = able to access any address
2D array and row/column address
S (static) RAM
- Use same technology as processors, on the same chip
- Similarly fast access speed as processors
- Each cell is large (6T) → small capacity
D (dynamic) RAM
- Different from processor technology; separate chips
- Slower access due to charge and discharge
- Each cell is small (1T1C) → large capacity
- Cell access is destructive; need extra complex circuits
Locality
Principle: predict data accessed
- temporal locality
- spatial locality
Exploiting Locality: Memory Hierarchy

Caches
AMAT (average memory access time) = hit latency + miss rate × miss penalty
Cache organization
Fully Associative Caches
Use any available location to store a block
low miss rate but high hit latency
Direct-Mapped Caches
Each block has a designated location, which is fully determined by its memory address
low hit latency but high miss rate
Index of a block = block address % #(blocks in cache) = lower bits in block address
Block address = (byte) address / block size
Set-Associative Caches
A block can go to one of \(N\) (associativity of the cache) locations
Middle ground between direct-mapped (\(N=1\)) and fully associative (\(N=\#(\text{blocks})\))
Set index = block address % #(sets) = ((byte) address / block size) % #(sets)
A cache entry = data block + tag + valid bit + (more metadata)

Replacement Policy
determine whether to evict and which entry to evict
Typical Replacement Policies
- Random
- Least Recently Used (LRU)
- Least Frequently Used (LFU)
Write policy
- write-hit: simply writes data only to cache, need a dirty bit in metadata, delay writes to memory until eviction.
- write-miss: first treated as a read-miss (fetching block from memory into cache), and then writes to cached block
The 3Cs of Cache Misses
- Compulsory/cold -> associativity
- Conflict -> block size
- Capacity -> capacity
Multi-level cache hierarchy and multi-core caches
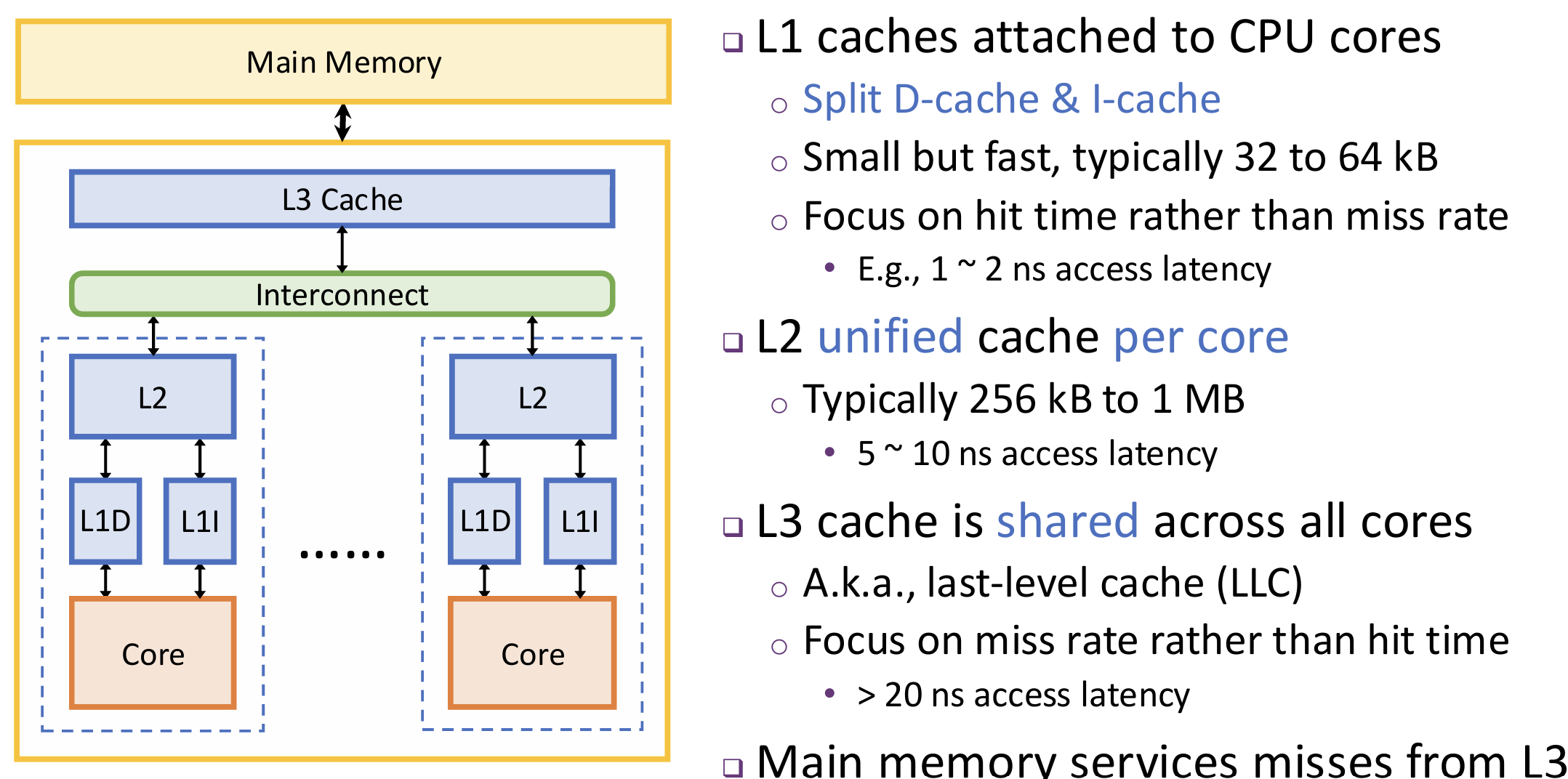
Use coherence protocols to solve coherence problem.

I/O Devices
I/O challenge:
-
Thousands of devices, different from each other. Need new and standardized interface and mechanisms
-
Devices are slow and with unpredictable behaviors. Need new access approaches different from memory loads/stores
Operational Parameters:
-
Data granularity: byte vs. block
-
Access pattern: sequential vs. random
-
Device speed rates vary over many orders of magnitude
General Techniques
Memory-Mapped I/O
Assign an unused range of physical address to each I/O device, which is called its I/O address
I/O address space is protected by the virtual memory mechanism:
- Method 1: use
syscallsto access I/O addresses - Method 2: ask OS to map I/O addresses to virtual addresses
Standardizing I/O Interface
Provide uniform interfaces for wide range of different devices.
-
Abstract all I/O devices to fit in several standard types
-
Use device driver to both
- Expose the standard abstract interface to the OS
- Internally translate to low-level actions to perform on the device.
I/O Types
By Access Granularity/Pattern:
- Block device: Access blocks of data; can randomly address a location
- Stream device: Sequential interface, no addressing; just read/write next block or character/byte
By Timing:
-
Blocking interface: "wait"
-
Non-blocking interface: “do not wait”
-
Asynchronous interface: “tell me later”
I/O Notification
How does the OS and user programs know that something interesting happened in the I/O device, if events are infrequent, and occur at any time unexpectedly?
Two approaches:
-
Polling: The I/O device places information in a status register; the OS periodically checks the status register (may be memory-mapped).
- Advantages: Simple to implement; processor is in control and manages the work
- Disadvantages: Difficult to determine how frequently to poll
- Works best for frequent and predictable events
-
Interrupts: When I/O device needs attention, it interrupts the processor; the OS finds out the reason from specific places.
- Advantages: CPU is free to do other computation
- Disadvantages: Software overhead (e.g., context switch); implementation complexity
- Work best for infrequent and unpredictable events
Direct Memory Access (DMA)
DMA is a custom hardware engine for data movement. Use it, we can transfer blocks of data to or from memory without CPU intervention. CPU can sends a data transfer task to it, and gets notified when task is done. DMA engine itself is an I/O device.
Processor sets up DMA by supplying: identity of the device and the operation (read/write), memory address for source/destination, and number of bytes to transfer. Each task will generate a data transfer descriptor: source, destination, length.
DMA accepts data transfer descriptor from processor. Can keep multiple transfer descriptors in a queue, and serve them one after one. DMA engine starts transfer when data is ready and notify processor when complete or on error, typically with interrupts.
Design issues:
-
OS may swap pages out to disk
Solution: memory pinning
-
contiguous virtual addresses may not be physically contiguous!
Solution 1: chain series of single-page requests; single interrupt at the end
Solution 2: DMA engine uses virtual addresses
- data involved in DMA may reside in processor cache
Solution 1: software flushes the cache or forces writebacks before I/O
Solution 2: hardware routes memory accesses for I/O through cache
Disks, SSDs and GPUs
Magnetic Hard Disk
Structure and Performance
Long-term, non-volatile, large, inexpensive. But... slow.
Usage: virtual memory, file system.
Organization: disk-> platter->surface->track->sector; aligned tracks form a cylinder. Software always transfers groups of sectors together, as blocks.
Access time breakdown:
- Controller overheads
- Queuing delay if other accesses are pending
- Seek time: move heads to the track
- Rotational latency: wait for target sector in the track
- Data transfer time: the whole sector passes under the heads

Disk Scheduling
Access to small data dominated by seek time and rotational latency. Disk scheduling that exploits data locality can improve performance!
Disk Scheduling Policies: (only consider track IDs)
-
FIFO: in the order of arrival
Pros: fair among requests; Cons: many seeks
-
Shortest seek time first (SSTF): pick the request that is closest to head
Pros: reduce seeks; Cons: may lead to starvation
-
SCAN: elevator algorithm, take the closest request in the travel direction
Pros: low seek, no starvation; Cons: still unfair as it favors middle tracks
-
C-SCAN (circular SCAN): like SCAN but only serves in one direction
Pros: more fair than SCAN; more consistent response time; Cons: longer seeks on the way back; lower throughput
Solid State Drive (SSD)
Structure and Performance
SSDs are usually made by NAND/NOR multi-level cell Flash memory. It contains an array of Flash chips, a DRAM buffer (a.k.a., cache), and a controller (which could be either a general-purpose core or specialized chip). Since there is no mechanical moving parts, seek and rotational latencies are eliminated. It contains two levels: 4 kB per page and 32 to 128 pages per block.
Reads are in units of pages, with latency in about 20 us; writes are complicated, with latency in 200 us– 1.7 ms (can only write to erased pages (about 200 us); erase must happen in units of blocks and are slow (e.g., 1.5 ms)).
Notice that no in-place modification in SSD/Flash. Must write data to a new page in an erased block; then let the address point to this page. Such management is handled by the Flash Translation Layer (FTL).
Flash Translation Layer (FTL)
Functionalities:
- Data address mapping
- Tracking physical block status
- Wear leveling
Data structures:
- Address mapping: logical to physical
- Block info table for each physical block: track block status, write pages in a block sequentially, wear leveling.
Wear Out: SSD has limited lifetime during which we can reliably store data, a block wears out after certain number of erases. So frequently written data may wear out their pages/blocks sooner. To solve it, FTL performs wear leveling to avoid hotspots. (To uniformly move and remap data to different physical pages/blocks.)
vs. disks
Advantages: No moving parts(faster, less power, more rugged), random access is only slightly slower than sequential access.
Disadvantages: Asymmetric performance between reads and writes, have the potential issue of wear-out.
GPUs
In system, GPU is connected as an I/O device to the CPU, but they have physically separate memories.
Performance overhead of data movements is significant, use overlapping computation and communication to optimize.
As management processor + accelerator, CPU is dedicated to GPU management and other auxiliary functions, while GPU is the workhorse of the application, offloaded with most computation. (Offloading computation.)
As cooperative co-processors, CPU and GPU work together on a problem.
Operating Systems: Manage Hardware Resources
Processes and Threads
Processes
A process is an instance of an executing program.
In multiprocessing, each process seems to have exclusive use of processor and memory.
A thread is a single unique execution context.
One process has one address space, which is shared by all threads of that process
A process = one or multiple threads + an address space
User vs. Kernel Mode
Kernel mode: high privilege
User mode: limited privilege
One bit in processor as the user/kernel mode bit.
Kernel Transition Mechanisms
System call
proactive
Syscalls offer a narrow waist as a portable interface
Interrupt
reactive; internal reasons
Exception and trap
reactive; external reasons
Context switch

By an interrupt of a timer of a syscall to voluntarily yield the processor.
Management
Terminating Processes
A process is terminated for one of
- Returning from main function
- Calling
exitsyscall - Receiving a signal whose default action is to terminate
exit is called but never returns
Creating Processes
Parent process creates a new running child process by calling fork.
Child process is almost identical (i.e., a copy) to parent process
- Child gets an identical (but separate) copy of the parent's address space
- Child gets identical access permissions of the parent's I/O devices
- Child has a different PID than the parent
Parent and child processes execute concurrently. Cannot predict their execution order; may interleave in any way.
int fork(void):
- Return 0 to child process; return child's PID to parent process
- Or return negative value to indicate errors
fork is called once but returns twice.
Reaping Child Processes
pid_t wait(int* wstatus)
Loading and Running Programs
exec family: load and run in the current process
Reaping Child Processes
pid_t wait(int* wstatus):
-
Suspends current process until one of its children terminates
-
Return value is the PID of the child process that terminated
-
If
wstatus != NULL, then store the child exit status into that address
pid_t waitpid(pid_t pid, int* wstatus, int options):
- Suspends current process until the specific child process pid terminates
If any parent terminates without reaping a child, then the orphaned child is reaped by the special init process (whose PID is 1)
Loading and Running Programs
int execve(char* filename, char* argv[], char* envp[]):
-
With the executable
filename, argument listargv, and env variable listenvp -
Retain PID, but overwrite code, data, and stack
execve is called once and never returns, except if there is an error
The commonstyle: fork-then-exec
pid_t cpid = fork();
if (cpid == 0) { // Child Process
// Child loads and runs new program
char *args[] = {"ls", "-l", NULL};
execv("/bin/ls", args, NULL);
// execv only returns if failed
perror("execv");
exit(1);
} else if (cpid > 0) { // Parent Process
// Parent waits for child
pid_t tcpid = wait(&status);
}
Signals
A signal is small message to notify a process that some event has occurred. (Sent from the kernel (sometimes at the request of another process) to a process.)
Type:
| Signal ID | Name | Default Action | Event |
|---|---|---|---|
| 2 | SIGINT | Terminate | Ctrl-C |
| 9 | SIGKILL | Terminate | Kill program |
| 11 | SIGSEGV | Terminate | Segmentation violation |
| 14 | SIGALRM | Terminate | Timer |
| 17 | SIGCHLD | Ignore | Child terminated |
Sending a signal: Kernel detects a system event or another process calls the kill syscall to request kernel to send a signal. int kill(pid_t pid, int sig)
Receiving a signal: Terminate the process, or execute a user-level function called signal handler, or just ignore the signal.
Shell
A shell is a job control system that runs programs on behalf of user. For example:
- sh: original Unix shell (Stephen Bourne, AT&T Bell Labs, 1977)
- csh/tcsh: BSD Unix C shell
- bash: “Bourne-Again” shell (default Linux shell)
Shell is a process itself: fork itself, exec program, and wait (or not)
- Foreground jobs: shell waits and reaps
- Background jobs: not reaped by shell, and also not reaped by init because shell (typically) will not terminate
Scheduling policies
Life Cycle of Processes/Threads:
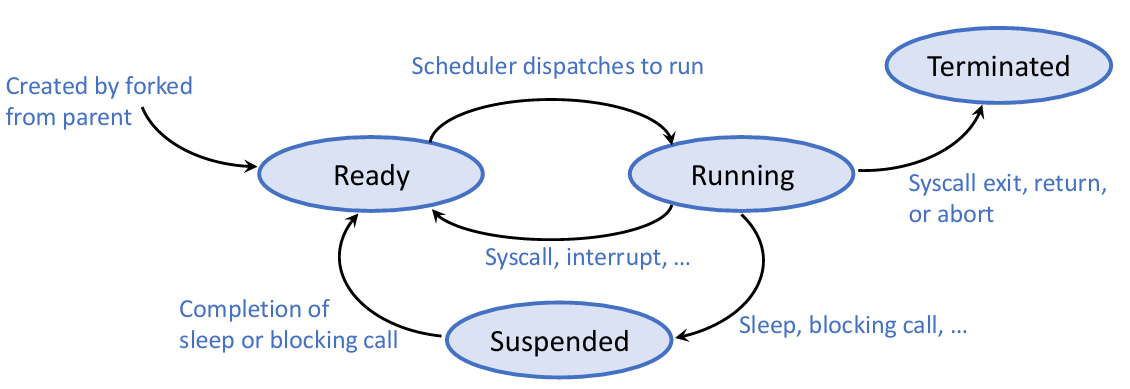
When there are more threads than hardware cores, active threads reside in a ready queue, waiting to be put onto the cores to run. OS decides which threads to run first, using a scheduling policy.
Classes:
- Non-preemptive: once giving a job some period of time to execute (not necessarily to completion), cannot take processor back before the period ends
- Preemptive: we can take processor back at any time, and use it for other jobs; preempted job goes back to ready queue and canresumelater
Metrics:
- Waiting time: time when the job waits in the ready queue
- Response time = waiting time + execution time. This is what the user sees
- Throughput: number of jobs completed per unit of time. Related to response time, but not always the same thing
- Fairness: all jobs use resource in some equal way
FCFS (First-Come, First-Served)
Run until done, non-preemptive
- Simple
- Depend on arrival orders
- Average wait/response time suffers from Convoy effect (short jobs are blocked behind long jobs)
Round Robin (RR)
Each job gets a small unit of time (time quantum, q) to execute, and then gets preempted and added back to end of queue
- More fair for short jobs than FCFS
- Context switch adds overheads
- Not easy to choose theright time quantum value
- Large q: Averagewait/response time suffers
- Small q: Throughput suffers
Typically choose q so that context switch overhead is small enough (e.g., 5%)
Optimal Scheduling: SJF/SRTF
SJF (shortest job first): run the job with the shortest execution time first
SRTF (shortest remaining time first): preemptive version of SJF. (If newjobarrives and has shorter remaining time than current one, preempt.) Also called STCF (shortest time to completion first))
- Optimal average response time
- Unfair, may lead to starvation if many short jobs come in; long jobs never run!
- Difficult to predict job execution time; sometimes impractical
Concurrency and Synchronization
Cooperating Threads
Advantages:
- shared resource
- speedup
- modularity
But... We need to consider Correctness Problems.
Some definitions:
-
Synchronization: using atomic operations to ensure cooperation between threads
-
Critical Section: piece of code that only one thread can execute at once
-
Mutual Exclusion: ensuring that only one thread executes critical section
-
Lock: prevents someone from doing something
-
Lock.Acquire() – wait until lock is free, then grab
-
Lock.Release() – unlock, waking up anyone waiting
-
Important idea: all synchronization involves waiting.
The big picture of synchronization: Hardware \(\to\) Higher-level API \(\to\) Programs
Semaphores
A Semaphore has a non-negative integer value and supports the following two operations:
- P(): an atomic operation that waits for semaphore to become positive, then decrements it by 1.
- V(): an atomic operation that increments the semaphore by 1, waking up a waiting P, if any
Application:
-
Mutual Exclusion (initial value = 1)
semaphore.P(); // Critical section goes here semaphore.V(); -
Scheduling Constraints (initial value = 0)
- Allow thread 1 to wait for a signal from thread 2, i.e.,
thread 2 schedules thread 1 when a given constrained
is satisfied
Initial value of semaphore = 0 ThreadJoin { semaphore.P(); } ThreadFinish { semaphore.V(); } - Allow thread 1 to wait for a signal from thread 2, i.e.,
-
Producer-consumer with a bounded buffer: producer->buffer->consumer
Semaphore fullSlots = 0; // Initially, no coke Semaphore emptySlots = bufSize; // Initially, num empty slots Semaphore mutex = 1; // No one using machine Producer(item) { emptySlots.P(); // Wait until space mutex.P(); // Wait until machine free Enqueue(item); mutex.V(); fullSlots.V(); // Tell consumers there is more coke } Consumer() { fullSlots.P(); // Check if there’s a coke mutex.P(); // Wait until machine free item = Dequeue(); mutex.V(); emptySlots.V(); // tell producer need more return item; }
Monitors and Conditional Variables
In the bounded buffer problem, semaphores are dual purpose for both mutex and scheduling constraints, may causes to deadlock.
Monitors: A synchronous object plus one or more condition variables.
Condition Variable: a queue of threads waiting for something inside a critical section
Operations:
- Wait(&lock): Atomically release lock and go to sleep. Re-acquire lock later, before returning.
- Signal(): Wake up one waiter, if any
- Broadcast(): Wake up all waiters
Application: synchronized queue
Lock lock;
Condition dataready;
Queue queue;
AddToQueue(item) {
lock.Acquire(); // Get Lock
queue.enqueue(item); // Add item
dataready.signal(); // Signal any waiters
lock.Release(); // Release Lock
}
RemoveFromQueue() {
lock.Acquire(); // Get Lock
while (queue.isEmpty()) {
dataready.wait(&lock); // If nothing, sleep
}
item = queue.dequeue(); // Get next item
lock.Release(); // Release Lock
return(item);
}
Reader / Writer Problem
Consider a shared database with two classes of users:
-
Readers: never modify database
-
Writers: read and modify database
Like to have many readers at the same time or only one writer at a time.
Correctness Constraints:
-
Readers can access database when no writers
-
Writers can access database when no readers or writers
-
Only one thread manipulates state variables at a time
State variables (Protected by a lock called “lock”):
-
int AR: Number of active readers; initially = 0
-
int WR: Number of waiting readers; initially = 0
-
int AW: Number of active writers; initially = 0
-
int WW: Number of waiting writers; initially = 0
-
Condition okToRead = NIL
-
Condition okToWrite = NIL
Reader() {
// First check self into system
lock.Acquire();
while ((AW + WW) > 0) { // Is it safe to read?
WR++; // No. Writers exist
okToRead.wait(&lock); // Sleep on cond var
WR--; // No longer waiting
}
AR++; // Now we are active!
lock.Release();
AccessDatabase(ReadOnly); // Perform actual read-only access
// Now, check out of system
lock.Acquire();
AR--; // No longer active
if (AR == 0 && WW > 0) // No other active readers
okToWrite.signal(); // Wake up one writer
lock.Release();
}
Writer() {
// First check self into system
lock.Acquire();
while ((AW + AR) > 0) { // Is it safe to write?
WW++; // No. Active users exist
okToWrite.wait(&lock); // Sleep on cond var
WW--; // No longer waiting
}
AW++; // Now we are active!
lock.release();
AccessDatabase(ReadWrite); // Perform actual read/write access
// Now, check out of system
lock.Acquire();
AW--; // No longer active
if (WW > 0){ // Give priority to writers
okToWrite.signal(); // Wake up one writer
} else if (WR > 0) { // Otherwise, wake reader
okToRead.broadcast(); // Wake all readers
}
lock.release();
}
Context Swith:
-
User->Kernel Context Switch
-
Acquire Lock
-
Kernel->User Context Switch
-
<perform critical section work>
-
User->Kernel Context Switch
-
Release Lock
-
Kernel->User Context Switch
Resource contention and deadlocks
Two types of resources:
-
Preemptable: can take it away. e.g. CPU, Embedded security chip
-
Non-preemptable: must leave it with the thread, e.g., Disk space, printer, chunk of virtual address space, Critical section
But... Resources may require exclusive access or may be sharable:
- Sharable: read-only files
- Non-shareable: printers
Def. Starvation: thread waits indefinitely. For example, low-priority thread waiting for resources constantly in use by high-priority threads.
Def. Deadlock: circular waiting for resources. For example, Thread A owns Res 1 and is waiting for Res 2, meanwhile Thread B owns Res 2 and is waiting for Res 1.
Rem. All deadlock are Starvation, but not vice versa.
Four requirements for Deadlock:
-
Mutual exclusion: Only one thread at a time can use a resource
-
Hold and wait: Thread holding at least one resource is waiting to acquire additional resources held by other threads
-
No preemption: Resources are released only voluntarily by the thread holding the resource, after thread is finished with it
-
Circular wait: There exists a set \(\{T_1, ..., T_n\}\) of waiting threads, and \(T_i\) is waiting for a resource that is held by \(T_{i\bmod n+1}\).
Handling Deadlocks:
- Allow system to enter deadlock and then recover
- Deadlock prevention: ensure that system will never enter a deadlock
- Ignore the problem and pretend that deadlocks never occur in the system
Preventing Deadlock:
- Infinite resources
- No Sharing of resources (totally independent threads)
- Don’t allow waiting
- Make all threads request everything they’ll need at the beginning
- Force all threads to request resources in a particular order preventing any cyclic use of resources
Behind the Scenes: Implementing a lock
Language support for synchronization
C: All locking/unlocking is explicit: you need to check every possible exit path from a critical section.
int Rtn() {
lock.acquire();
...
if (error) {
lock.release();// Needed!
return errReturnCode;
}
...
lock.release();
return OK;
}
C++: Languages that support exceptions are more challenging: exceptions create many new exit paths from the critical section.
void Rtn() {
lock.acquire();
try {
...
DoFoo();
...
}
catch (...) { // really three dots!
// catch all exceptions
lock.release(); // release lock
throw; // re-throw unknown exception
}
lock.release();
}
void DoFoo() {
...
if (exception) throw errException;
...
}
Alternative: Use the lock class destructor to release the lock.
class lock {
mutex &m_;
public:
lock(mutex &m) : m_(m) {
m.acquire();
}
~lock() {
m_.release();
}
};
mutex m;
...
{ //Critical Section
lock mylock(m);
...
...
... // no explicit unlock
}
Another way: Communicate to Share
-
Share no memory, if want to share, send a message!
-
Can use a queue to send message
Naïve use of Interrupt Enable/Disable
We know that dispatcher gets control in two ways.
-
Internal: Thread does something to relinquish the CPU
-
External: Interrupts cause dispatcher to take CPU
On a uniprocessor, can avoid context-switching by avoiding internal events (although virtual memory tricks) and preventing external events by disabling interrupts.
Consequently, naïve Implementation of locks:
LockAcquire { disable Ints; }
LockRelease { enable Ints; }
But... Consider following:
LockAcquire();
While(TRUE) {;}
Better Implementation of Locks by Disabling Interrupts
Key idea: maintain a lock variable and impose mutual exclusion only during operations on that variable
int value = FREE;
void Acquire() {
disable_interrupts();
if (value == BUSY) {
put_thread_on_wait_queue();
Go_to_sleep();
// Enable interrupts?
} else {
value = BUSY;
}
enable_interrupts();
}
void Release() {
disable_interrupts();
if (anyone_on_wait_queue()) {
take_thread_off_wait_queue();
Put_at_front_of_ready_queue();
} else {
value = FREE;
}
enable_interrupts();
}
Problems: Doesn’t work well on multiprocessor
Implementing with Atomic Instructions Sequences
Atomic Read-Modify-Write instruction: read a value from memory and write a new value atomically. Examples:
/* test&set - most architectures */
test&set (&address) {
result = M[address];
M[address] = 1;
return result;
}
/* swap - x86 */
swap (&address, register) {
temp = M[address];
M[address] = register;
register = temp;
}
/* compare&swap - 68000 */
compare&swap (&address, reg1, reg2) {
if (reg1 == M[address]) {
M[address] = reg2;
return success;
} else {
return failure;
}
}
Let's implement locks using test&set:
int guard = 0;
int value = FREE;
void Acquire() {
// Short busy-wait time
while (test&set(guard));
if (value == BUSY) {
put_thread_on_wait_queue();
go_to_sleep();
guard = 0;
} else {
value = BUSY;
guard = 0;
}
}
void Release() {
// Short busy-wait time
while (test&set(guard));
if (anyone_on_wait_queue()) {
take_thread_off_wait_queue();
place_on_ready_queue();
} else {
value = FREE;
}
guard = 0;
}
Virtual Memory
PTE and TLB
Base and bound (B&B) suggests to split the entire physical memory into contiguous ranges that are assigned to different processes. It has many drawbacks, such as restricted to contiguous address ranges, difficult to extend dynamically or to support shared regions across address spaces.
Virtual memory mechanism provides fine-grained and dynamic management of address spaces. Each process has its own virtual address space that is contiguous and linear, i.e., from \(0\) to \(N = 2^n\) (n is 32-bit or 48-bit). All virtual address spaces are mapped to the physical address space in a flexible way, in the unit of pages.
Page table is used to translate virtual address to physical address. Each process has its own page table; managed by OS; used by hardware. It's stored in main memory as an OS data structure. One page table entry (PTE) per virtual page, each PTE includes: valid bit, physical page number (a.k.a., frame number), metadata (e.g., R/W/X permissions)

Virtual memory as a tool for
- Memory management: Allocate & map pages in a virtual space.
- Memory protection: Process cannot access physical memory not mapped to its virtual space
- Data caching: Only a subset of allocated virtual pages are mapped, other pages are swapped out to external storage. Main memory (DRAM) only caches the most frequently accessed data. If a page fault (allocated but not mapped) occurs, the page is paged in on demand, by the page fault handler in OS kernel.
OS manages page table by allocating physical space to virtual space, while hardware looks up page table to translate virtual to physical address.
Translation Look-aside Buffer (TLB) is a hardware cache just for address translation entries, i.e., PTE. Each TLB entry consists of data: (a PTE, including physical page number and R/W/X bits) and valid bit, tag, etc. of itself. TLB as a cache for page table, can speed up translation.
If we miss in TLB, access PTE in memory; this is called page table walk.


Virtual address space is much larger than typical physical address space! Ideally, we only need PTEs of allocated pages, not all virtual pages. To save page table size, we introduce:
Multi-Level Page Tables: Use a hierarchical page table structure, i.e., a (sparse) radix tree. Only top level must be resident in memory, remaining levels can be in memory or on disk. For example, Intel x86-64 four-level page table is a 512-ary radix tree, with span of 9 bits:

Memory Allocation
Memory Mapping
Inter-Process Sharing are allowed. Different processes can share a page by setting their virtual addresses to point to the same physical address.
Copy-on-Write (CoW): When copying pages, just make destination virtual address point to the same physical page as source virtual address, and mark the page as write-protected in PTE. When writing to either virtual address, trigger a permission fault and do actual copy, i.e., allocate a new physical page.
Memory Mapping is about how to associate a virtual memory area with a file object. It is a unified way to deal with all following cases, i.e., all data sources to the memory area are treated as files:
- Get initial data from this file into memory: regular file on disk
- Swap the physical memory content from/to this file: special swap file
- For newly allocated space initialized to all zero values: special anonymous file
When doing memory mapping, OS only sets up PTE in page table. Wait until the first page fault (when data are actually accessed), and rely on demand paging to actually get data into memory. For anonymous file, physical page is only allocated at the time of the first write; before that, just return 0 for read accesses.
Recall: When fork, child gets an identical but separate copy of the parent’s address space.
- Create exact copies of the page table and other kernel structures
- Mark each PTE in both page tables as write-protected
- At this point, both processes have the identical contents in their address spaces
- Subsequent writes to either address space use CoW to create separate pages
To load and run a new program by execve, etc
-
Free the old page table and initialize a new page table
-
Memory map program and data
-
Set PC to the entry point of the program
User-Level Memory Mapping: mmap and mumap syscall
void* mmap(void* addr, size_t length, int prot, int flags, int fd, off_t offset): Accessing files as well as allocating new virtual address ranges (anonymous file). Map length bytes from the offset offset of the file specified by the descriptor fd, preferably to virtual address addr, with desired protection prot.
addris only a hint; it could also be NULL to let kernel choose the virtual address;flags: MAP_ANON, MAP_PRIVATE, MAP_SHARED, …
Return the mapped virtual address (may not equal to addr), or MAP_FAILED on error.
int munmap(void* addr, size_t length)
Dynamic Memory Allocation: Explicit Memory Management
A program can dynamically allocate memory at runtime using the dynamic allocator. The dynamic allocator manages an area of the process virtual address space, called the heap.
Allocator API:
void* malloc(size_t size): Get a pointer to a memory space of at least size bytes. Other variants: calloc, realloc, …
void free(void *p): Give up the memory space pointed by p, previously from malloc/calloc/…
C++ new and delete statements are similar.
Allocator Policy: Segregated Free Lists
- Organize free spaces into multiple linked lists for different sizes, e.g., one list for each power-of-two size.
- To allocate a block of \(n\) bytes, search the free list of size \(m>n\), until found a free space, use the first \(n\) bytes of it. If no space is available in all lists, grow heap from OS.
- When the requested size is smaller than the allocated free space, and the remaining space is wasted, then we need internal fragmentation, e.g., append remaining space of \((m-n)\) to its corresponding free list, which can be used for a future small-size request.
Good allocators should be fast, and minimize both external and internal fragmentation.
Garbage Collection: Implicit Memory Management
Garbage collection: automatic reclamation of heap-allocated storage.
A memory manager runs along with the user program. When a memory space is not needed, the memory manager frees it. So user programs never need to free allocated memory!
How does the memory manager know when a memory space can be freed? If for a memory object, there are no pointers anywhere that point to it, it can never be used any more. But still we may miss some opportunities to reclaim memory.
Model: View memory as a graph, where each each object is a node. An edge exists if a pointer in an object points to another object. Root nodes are the objects that are not dynamically allocated in the heap. Heap objects that are reachable from any root node is reachable nodes. So non-reachable nodes are garbage to be collected.
GC may start due to out-of-memory, or is periodically triggered. Classical GC Algorithm:
-
Mark-and-Sweep
- Mark: start from root nodes, traverse graph and mark a bit in each reachable object; non-reachable objects are not visited and not marked.
- Sweep: scan all objects in the memory, and free unmarked objects.
-
Reference Counting
- Each object maintains a reference counter, which keeps the number of other pointers that point to this object.
- When the reference counter becomes zero, we free the object.
- Problem: does not work for circular cases
File Systems
File system is a component in OS that transforms block interface into high-level interface like files and directories. A file system mainly consists of two parts:
- A collection of files, each storing relevant data in a group of disk blocks;
- A directory structure, organizing files and mapping names to files.
File, Directory and Links
File Basic
Files must be stored durably, i.e., persist even after the creating process is terminated and even after system is shutdown. Files are named, and referred by the names. When a file is named, it becomes independent of the process, the user, and even the system that created it. From a user’s perspective, a file is the smallest granularity of logical secondary storage; that is, data cannot be written to secondary storage unless they are within a file.
File descriptor (a.k.a., inode) is a OS data structure about a file’s metadata information. It's kept in kernel memory when file is open: for convenient operations. Consists of
- File size;
- File location (e.g., sectors on disk);
- Access timestamps (e.g., create, last read, last write);
- Protection info (e.g., access permissions (R/W/X), owner ID, group ID);
- ...
File Operations:
- Open: use name to search a file in the directory, i.e., resolve file name. First, translate file name into a file number, which is used to locate the file descriptor on disk. Then copy file descriptor from disk to OS kernel memory space. Finally, return a file handle (usually an integer) to user process.
- Later read/write/seek/sync operate on file handles. OS internally uses file handle to locate file descriptor, and to find data blocks
- Close: when no longer operating on the file.
Two levels of open-file tables: per-process and system-wide. Multiple processes may open the same file at the same time. The second process simply adds an entry to its per-process table, pointing to the already existing entry in the system-wide table. System-wide table entries have reference counters, automatically remove entry when the last process closes the file.
File Access Patterns:
- Sequential: data are processed in order, one byte after another;
- Random: can address any byte in the middle of a file directly;
- Keyed (or indexed): search for blocks with particular contents (Most OSes do not support this; instead, build a database)
Directory
Directory is used to map names to file numbers. Modern systems support hierarchical directory structures:
- Each directory is a collection of files and other directories
- Names have slashes “/” separating the levels, i.e., a path
- Each directory, like a file, has name and attributes, and “data”
Let focus on Unix/Linux directory structures.
Directories are just like regular files, e.g., with a file descriptor, except that file descriptor has a special bit indicating it is a directory. "Data" of a directory is an unordered list of <name,pointer> pairs, each pair is for a child file or a sub-directory, pointer is a file number that points to its file descriptor. A special directory called the root has no name, and has i-number of \(2\). i-number \(0\) is null; i-number \(1\) means bad blocks.
User programs can read directories just like regular files. Usually only OS can write directories.
Links
Hard link: set another directory entry to the file number for a file. Make directory structure a DAG (directed acyclic graph), not a tree.
Soft or symbolic link: special file whose content is another name (path). Stored as regular files, but with a flag set in file descriptor.
Current Working Directory is remembered by OS per process. The inode of the working directory is kept in the PCB. If a path starts without “/”, then look up starting from the working directory
Space Management
Data Block Organization
How to allocate disk blocks of a file? Principle:
- Most files are small (a few kB or less): per-file overheads must be low
- Most of the disk space is in large files
- Performance must be good for large files even for random accesses
- File sizes may grow unpredictably over time
Contiguous allocation: allocate contiguous blocks all at once.
-
Pros: Simple; easy to access; few disk seeks;
-
Cons: Harder and harder to allocate large files (due to external fragmentation); Hard to grow file sizes.
Linked Files: keep a linked list of all blocks of a file. In file descriptor, only need to keep a pointer to the first block, to randomly access a specific position, just from file descriptor, follow linked list until reaching the block. E.g., Windows FAT.
-
Pros: No external fragmentation; high utilization of disk space; easy to allocate new blocks; file size can grow, and may even grow in the middle;
-
Cons: More disk seeks, even for sequential accesses (poor locality); overheads of tracking pointers.
Indexed Files: keep the set of pointers to data blocks. E.g., 4.3 BSD Unix (Multi-Level Index).
- Pros: Have pros of both contiguous and linked: support direct access; fast random access; no external fragmentation。
- Cons: Still some amount of seeks; File size is limited, or, many unused pointers
Free Space Management
Many early systems use a linked list of free blocks, which is similar to free space tracking in dynamic heap allocators.
4.3 BSD Unix approach: bitmap. During allocation, search for a block close to the previously last block of the file, so that seek distance is minimized and locality is improved. When disk is full, search takes long time and locality is not improved. Solution: do not let disk fill up!
Performance optimization: Buffer Cache
Buffer Cache use part of main memory to retain recently accessed disk blocks. It's implemented entirely in OS software; can cache inodes, data blocks for directories and files, indirect blocks, free bitmaps, etc. Managed in unit of blocks; replacement policy is usually LRU. Many OSes now unify buffer cache and VM page pool, in order to avoid double caching issue for memory-mapped files.
What happens when a block in the buffer cache is modified?
Synchronous writes: immediately write through to disk. Safe but slow.
Delayed writes: do not immediately write to disk, e.g., wait for a while. Fast but dangerous.
Protection
Protection: prevent accidental and malicious misuse.
Authentication: identify a responsible party (principal).
Authorization: determine what actions can be performed by a principal on an object
Access enforcement: combine authentication and authorization to control access
Authentication is typically done with passwords. System store one-way hash results instead of plaintext passwords, and concatenate with random salts.
Once authenticated, e.g., user log in, the identity of the principal, e.g., user ID, is attached to every process executed under that login. After authentication, the authenticated identity of the principal must be protected from tampering, since other parts of the system rely on it.
In Authorization, authorization information can be represented as access matrix, one row per principal and one column per object. Such a full matrix is too large, we need to compress it. There are two ways:
Access control lists (ACL): Organized by columns. With each object, store info about which principals are allowed to perform what operations. Users can be organized into groups, and a single ACL entry for a group.
- Pros: all info close to object; easy to know who is allowed
- Cons: hard to store if cannot grouped; hard to know everything one can access
Capabilities: Organized by rows. With each principal, indicate which objects may be accessed and in what ways. Capabilities must be unforgeable and revocable.
- Pros: easy to know all resources one can access; combined with access
- Cons: hard to know everyone allowed to access one object; capability list is long
Networking and Data Systems
Networking
Basic Network Functionalities:
-
Delivery: deliver packets between any two hosts in the Internet without a large number of physical wires
-
Reliability: tolerate packet losses
-
Flow control and congestion control: avoid overflowing the receiver + avoid overflowing the routers
Deliver on Network
Multiplexing
Links (wires) is the basic building block of network. But we can't build direct links for all hosts. When sharing network resources among hosts, we need multiplexing, it's about how to efficiently utilizing the wires.
Packet Switching: Source sends information as self-contained packets that have an address. Source may have to break up single message into multiple, each packet travels independently to the destination host. Switches use the address in the packet to determine how to forward the packets.
Addressing
Addresses
Network (interface) card/controller (NIC): hardware that physically connects a computer to the network.
-
MAC address: 48-bit unique identifier assigned by card vendor
-
IP Address: 32-bit (or 128-bit for IPv6) address assigned by network administrator or dynamically when computer connects to network
Use IP address for routing.
Connection: communication channel between two processes. Each endpoint is identified by a port number: 16-bit identifier assigned by app or OS. Globally, an endpoint is identified by (IP address, port number).
-
DNS (Domain Name System): Domain name to IP address.
-
ARP (Address Resolution Protocol): IP to MAC
LANs and WANs
How to find the destinations in networks?
Local Area Network (LAN): all hosts in can share the same physical communication media (wire).
-
Hubs: forward from one wire to all the others.
-
Switches: forward frames only to intended recipients. "Learning switch": remembers which MAC is connected to which port.
Wide Area Network (WAN): network that covers a broad area (e.g., city, state, country, entire world). WAN connects multiple datalink layer networks (LANs). Datalink layer networks are connected by routers.
- Routers: forward each packet received on an incoming link to an outgoing link based on packet’s destination IP address (towards its destination). Packets are buffered before being forwarded. Record the mapping between IP address and the output link in the forwarding table.
- read the IP destination address of the packet
- consults its forwarding table to get the output port
- forwards packet to corresponding output port
Reliability and flow control
Parameters of a communication channel:
- Latency: how long does it take for the first bit to reach destination
- Capacity: how many bits/sec can we push through? (often termed “bandwidth”)
- Jitter: how much variation in latency?
- Loss / reliability: can the channel drop packets?
Common problems:
- Lost. Solution: Timeout and Retransmit.
- Corrupted. Solution: Add a checksum.
- Out of order. Solution: Add Sequence Numbers.
- Overloaded. Solution: Buffering and Congestion Control.
Packet delay consists of:
- Propagation delay on each link, proportional to the length of the link.
- Transmission delay on each link, proportional to the packet size and 1/(link speed).
- Processing delay on each router, depends on the speed of the router.
- Queuing delay on each router, depends on the traffic load and queue size.
How to design reliable protocol?
Stop & Wait Protocol: Accomplished by using acknowledgements (ACK) and timeouts.
TCP protocol: sent more packets before waiting for an ACK.
- Retransmit lost packets: Keep a sequence number on each packet
- Figuring out the rate by AIMD (additive increment multiplicative decrement): Slow start until detect overflow, then slowdown quickly, and increase slowly until overflow again.
Layering
Different applications (Skype, SSH, NFS, HTTP) have different transmission media. We need layering to adapting them.
Layering is a modular approach in networking. It introduce intermediate layers that provide set of abstractions for various network functionality & technologies. Each layer solely relies on services from layer below and solely exports services to layer above. Interface between layers defines interaction and it hides implementation details.
A protocol is a set of rules and formats that specify the communication between network elements. It specify how the layer is implemented between machines.
OSI Layering Model: seven layers as follows
Application \(\to\) Presentation \(\to\) Session \(\to\) Transport \(\to\) Network \(\to\) Datalink \(\to\) Physical
Internet Protocol (IP): only five layers, the functionalities of the missing layers (i.e., Presentation and Session) are provided by the Application layer.
Physical Layer
Service: move information between two systems connected by a physical link
Interface: specifies how to send and receive bits
Protocol: coding scheme used to represent a bit, voltage levels, duration of a bit
Datalink Layer
Service: Enable end hosts to exchange frames (atomic messages) on the same physical line or wireless link
Interface: send frames to other end hosts; receive frames addressed to end host
Protocols: Addressing ARP; Media Access Control (MAC). Each frame has a header which contains a source and a destination MAC address, use broadcast ARP to address.
Network Layer
Service: Deliver packets to specified network (IP) addresses across multiple datalink layer networks
Interface: send packets to specified network address destination; receive packets destined for end host
Protocols: define network addresses (globally unique); construct forwarding tables; packet forwarding
Examples : IP (Internet Protocol) is the network layer of Internet. It service it provides: “Best-Effort” Packet Delivery.
Transport Layer
Service: Port (end-to-end communication between processes); Multiple processes on the same hosts communicating simultaneously
Interface: send message to specific process at given destination; local process receives messages sent to it
Protocol: port numbers, perhaps implement reliability, flow control, packetization of large messages, framing
Examples: TCP (Reliable, in-order delivery) and UDP (Datagram service, No-frills extension of “best-effort” IP).
Application Layer
Service: any service provided to the end user
Interface: depends on the application
Protocol: depends on the application
Examples: Skype, SMTP (email), HTTP (Web), BitTorrent…
Summary
Lower three layers implemented everywhere; Ideally, top two layers implemented only at hosts.

The Internet Hourglass: There is just one network-layer protocol, IP. The “narrow waist” facilitates interoperability.

End-to-End Argument: If you have to implement a function end-to-end anyway, don’t implement it inside the communication system.
Remote procedure calls
Communication mode:
-
Clients and Servers
-
Peer to Peer: Each host is both server and client
A protocol is an agreement on how to communicate, includes
-
Syntax: how a communication is specified & structured (Format, order messages are sent and received)
-
Semantics: what a communication means (Actions taken when transmitting, receiving, or when a timer expires)
IPC mechanisms (Socket API) share raw bytes. Can be wrapped into an RPC as the underlying communication mechanism.
Remote Procedure Call (RPC): Encapsulates network communication and simulates local function calls. Looks like a local procedure call on client. Translated automatically into a procedure call on remote machine (server).
Marshalling involves converting values to a canonical form, serializing objects, copying arguments passed by reference, etc. Client and server use “stubs” to glue pieces together. Also called “serialize” / “de-serialize”.
Databases and Transactions
Databases and Queries
A data model is a collection of entities and their relationships.
A schema is an instance of a data model.
A relational data model organizes data into tables (relations) with rows and columns, where each table's schema defines its structure and fields.
A Database Management System (DBMS) is a software system designed to store, manage, and facilitate access to databases. A DBMS provides: Data Definition Language (DDL) and Data Manipulation Language (DML), guarantees about durability, concurrency, semantics, etc. System handles query plan generation & optimization; ensures correct execution.
Transactions
A transaction is an atomic sequence of database actions (reads/writes). It takes DB from one consistent state to another.
The ACID properties of Transactions:
-
Atomicity: all actions in the transaction happen, or none happen.
-
Consistency: transactions maintain data integrity, e.g.,
-
Balance cannot be negative;
-
Cannot reschedule meeting on February 30.
-
-
Isolation: execution of one transaction is isolated from that of all others; no problems from concurrency.
-
Durability: if a transaction commits, its effects persist despite crashes.
By Log
Log is stored in non-volatile storage (Flash or on Disk), used to seal the commitment to a whole series of actions. For example, creating a file:
-
Start a transaction.
-
Write metadata changes to the log (not yet applied to disk), contains: write map (i.e., mark used); write inode entry to point to block(s); write dirent to point to inode.
-
Commit the transaction.
-
"Redo Log": First looks in log, then copy changes to the actual file system.
-
Free log space.
When the system crashes, upon recovery: scan the log; detect transaction start with no commit; discard log entries.
Cons: expensive, writing all data twice.
By Lock
Serial schedule: A schedule that does not interleave the operations of different transactions.
Equivalent schedules: For any storage/database state, the effect (on storage/database) and output of executing the first schedule is identical to the effect of executing the second schedule.
Serializable schedule: A schedule that is equivalent to some serial execution of the transactions
Goals of Transaction Scheduling: find a serializable schedule that maximize concurrency.
Anomalies with interleaved execution:
- Write-write conflict (overwriting uncommitted data)
- Read-Write conflict (Unrepeatable reads)
- Write-read conflict (Reading uncommitted data)
Two operations conflict if they belong to different transactions, are on the same data, and at least one of them is a write.
Two schedules are conflict equivalent iff they involve same operations of same transactions and every pair of conflicting operations is ordered the same way.
Schedule \(S\) is conflict serializable if \(S\) is conflict equivalent to some serial schedule.
If you can transform an interleaved schedule by swapping consecutive non-conflicting operations of different transactions into a serial schedule, then the original schedule is conflict serializable.
Dependency graph is a graph with transactions represented as nodes and edges are from \(T_i\) to \(T_j\) such that an operation of \(T_i\) conflicts with an operation of \(T_j\) and \(T_i\) appears earlier than \(T_j\) in the schedule.
Thm. Schedule is conflict serializable if and only if its dependency graph is acyclic.
We know that Conflict Serializability \(\Rightarrow\) Serializability but Serializability \(\not\Rightarrow\) Conflict Serializability. Actually, deciding whether a schedule is serializable (not conflict-serializable) is \(\mathsf{NP}\)-complete.
Locks are used to control access to data. There are two types of locks:
-
Shared (S) lock – multiple concurrent transactions allowed to operate on data;
-
Exclusive (X) lock – only one transaction can operate on data at a time.
Two-Phase Locking (2PL):
-
Each transaction must obtain:
- S (shared) or X (exclusive) lock on data before reading,
- X (exclusive) lock on data before writing
-
A transaction can not request additional locks once it releases any locks
Thus, each transaction has a “growing phase” followed by a “shrinking phase”.
Thm. 2PL-compatible schedules are conflict serializable.
Distributed Systems
Distributed Systems overview
A Distributed System is a collection of independent computers that appears to its users as a single coherent system. Features:
-
No shared memory: message-based communication
-
Each runs its own local OS
-
Heterogeneity
A distributed system organized as middleware. The middleware layer runs on all machines, and offers a uniform interface to the system.

But...coordination is more difficult. It has:
-
Worse availability: depend on every machine being up
-
Worse reliability: can lose data if any machine crashes
-
Worse security: anyone in the world can break into system
Goals:
-
Resource sharing
-
Transparency
-
Openness
-
Scalability
Remote procedure calls: Looks like a local procedure call on client; Translated automatically into a procedure call on remote machine (server). Use marshalling to converting values to a canonical form, serializing objects, copying arguments passed by reference, etc.
With RPC a failure within a procedure call means remote machine crashed, but local one could continue working. However, performance: Cost of Procedure call << same-machine RPC << network RPC
Network File System (NFS) and Andrew File System (AFS)
File access consistency
| Method | Comment |
|---|---|
| UNIX semantics | Every operation on a file is instantly visible to all processes |
| Session semantics | No changes are visible to other processes until the file is closed |
| Immutable files | No updates are possible; simplifies sharing and replication |
| Transactions | All changes occur atomically |
In UNIX local file system, concurrent file reads and writes have “sequential” consistency semantics: Each file read/write from user-level app is an atomic operation; Each file write is immediately visible to all file readers. Such "One Copy Semantics" is provided by neither NFS nor AFS.
Network File System
Distributed file systems require transparent access to files stored on a remote disk.
Intuitively, use RPC to support EVERY read and write gets forwarded to server. Bu the performance is bad. Consider use caching to reduce network load. That is, if open/read/write/close can be done locally, don’t need to do any network traffic. Although it can be fast, may leads to cache consistency problem.
Write-through cache and NFS protocol
Write-through cache. With a write-through caching policy, the system's processor writes data to the cache first and then immediately copies that new cache data to the corresponding memory or disk. The application that's working to produce this data holds execution until the new data writes to storage are completed. Write-through caching ensures data is always consistent between cache and storage, though application performance could see a slight penalty because the application must wait for longer input/output operations to memory or even to disk.
Network File System protocol: Client polls server periodically to check for changes. It has a weak consistency, since if multiple clients write to same file, it becomes completely arbitrary.
Failures Handling
NFS servers are stateless; each request provides all arguments require for execution.
Idempotent: Performing requests multiple times has same effect as performing it exactly once
With stateless + idempotent, if server crashes and restarted, requests can continue where left off (in many cases).
Failure Model: Transparent to client system. Options to failures handling: hang until server comes back up or return an error.
Andrew File System
Andrew File System: Global distributed file system. The goal is to minimize / eliminate work per client operation.
Assumption: Client machines have disks; write/write and write/read sharing are rare; access from local disk is faster and cheaper than from LANs.
AFS Cell/Volume Architecture:
- Cells correspond to administrative groups
- Cells are broken into volumes (miniature file systems): one user's files, project source tree, ...
- Client machine has cell-server database: protection server, volume location server
Write-back cache and AFS protocol
AFS caching: More aggressive caching, caches on disk in addition to just in memory
- Prefetching (On open, AFS gets entire file from server, making later ops local & fast).
- Callbacks (Clients register with server that they have a copy of file; server tells them: “Invalidate!” if the file changes)
Session semantics: A file write is visible to processes on the same box immediately, but not visible to processes on other machines until the file is closed. When a file is closed, changes are visible to new opens, but are not visible to “old” opens. Last writer (i.e. the last close()) wins.
Write-back cache. With a write-back caching policy, the processor writes data to the cache first, and then application execution is allowed to continue before the cached data is copied to main memory or disk. Cache contents are copied to storage later as a background task -- such as during idle processor cycles. This allows the processor to continue working on the application sooner and helps to improve application performance. However, this also means there could be brief time periods when application data in cache differs from data in storage, which raises a possibility of application data loss in the event of application disruption or crashes. For example, in AFS, dirty data are buffered at the client machine until file close, then flushed back to server, which leads the server to send “break callback” to other clients.
Failures Handling
If server crashes, it lose all callback state! Must reconstruct callback information from client: go ask everyone “who has which files cached?”
If client crashes, it may have missed callback! Must revalidate any cached content it uses.
Disconnected operation (Coda): “Optimistic Replica Control”
- Hoarding: Whenever the client is connected to the network, it is in hoarding mode. In this mode, the client does aggressive caching, that is, hoard useful data for disconnection. Need to balance the needs of connected and disconnected operation.
- Emulation: Whenever the client is disconnected, it makes a transition into the emulation mode. In this mode, all the file requests are serviced by the local cache and the version vectors get updated. The local cache file acts just like the actual file. Attempts to access files that are not in the client caches appear as failures to application. All changes are written in a persistent log, the client modification log.
- Reintegration: On reconnection, the client goes to the reintegration mode. Resynchronization and version vector comparisons are made in this mode. Only care about write/write conflict, in practice, it won't happen.
Practical Skills
Command line
wc -l # Count the number of lines
ps # Show the status of current process
tail –f # Track file changes in real time
sort -nk1,1
-n use numeric order
-k start/stop of a column (1, 1)
uniq # Works only on sorted data
sed -E 's/.*Disconnected from (invalid |authenticating )?user (.*) [^ ]+ port [0-9]+( \[preauth\])?$/\2/' # Second capturing group is the username
$0 # Name of the script
$1 to $9 # Arguments to the script. $1 is the first argument and so on.
$@ # All the arguments
$# # Number of arguments
$? # Return code of the previous command (argument to the exit() function in C)
$$ # Process identification number (PID) for the current script
!! # The entire previous command line
Permissions: Owners/Groups/Others
drwxr-xr-x #d: directory. rwx:read/write/execute
stdin 0 / stdout 1 / stderr 2
ls -l / | tail -n1 # tunnel
Ctrl-C = SIGINT
Ctrl-\=SIGQUIT
kill -TERM
Ctrl-Z=SIGSTOP
# Find files by extension:
find root_path -name '*.ext'
# Find files matching multiple path/name patterns:
find root_path -path '**/path/**/*.ext' -or -name '*pattern*'
# Find directories matching a given name, in case-insensitive mode:
find root_path -type d -iname '*lib*'
# Find files matching a given pattern, excluding specific paths:
find root_path -name '*.py' -not -path '*/site-packages/*'
# Find files matching a given size range:
find root_path -size +500k -size -10M
# Run a command for each file (use `{}` within the command to access the filename):
find root_path -name '*.ext' -exec wc -l {} \;
# Find files modified in the last 7 days and delete them:
find root_path -daystart -mtime -7 -delete
# Find empty (0 byte) files and delete them:
find root_path -type f -empty -delete
Regular expressions
. means “any single character” except newline
* zero or more of the preceding match
+ one or more of the preceding match
? zero or one of the preceding match
a{3} matches three a’s
[abc] any one character of a, b, and c
(RX1|RX2) either something that matches RX1 or RX2
^ the start of the line
$ the end of the line
\d{k} matches k digits

 浙公网安备 33010602011771号
浙公网安备 33010602011771号