分布式ID生成总结
1.数据库自增id
新建一个公共库,库里面新建一个序列表,主键id自增,每次请求增加数据都往这个表中插入数据,然后获取到id,然后使用即可。
优点:方便简单
缺点:单库生成自增id,高并发下,会有瓶颈
适用场景:
并发很低,几百/s,不会出现性能瓶颈
2.UUID
优点:本地生成,不基于任何第三方
缺点:
- 太长,作为数据库主键性能太差,不适合作为主键
- 不具有有序性,会导致B+树索引在写的时候有过多的随机写操作(连续的id可以产生部分顺序写)
- 写的时候不能产生有顺序的 append 操作,而需要进行 insert 操作,将会读取整个 B+ 树节点到内存,在插入这条记录后会将整个节点写回磁盘,这种操作在记录占用空间比较大的情况下,性能下降明显
适用场景:
随机生成文件名、编号,生成token等。
3.系统时间+拼接业务字段值
例如:当前时间戳 + 用户id + 业务含义编码,并发高的时候,会有重复,此时就不行了,不建议使用。
4.Redis
Redis是单线程的,所以也可以用生成全局唯一的ID。可以用Redis的原子操作 INCR和INCRBY来实现。
优点:
- 不依赖于数据库,灵活方便,且性能优于数据库。
- 数字ID天然排序,对分页或者需要排序的结果很有帮助。
缺点:
- 由于redis是内存的KV数据库,即使有AOF和RDB,但是依然会存在数据丢失,有可能会造成ID重复。
- 依赖于redis,redis要是不稳定,会影响ID生成。
5.snowflake算法
twitter开源的分布式id生成算法,把一个64位的long型的id,1个bit是不用的,用其中的41 bit作为毫秒数,用10 bit作为工作机器id,12 bit作为序列号,理论上最多支持1024台机器每秒生成4096000个序列号。
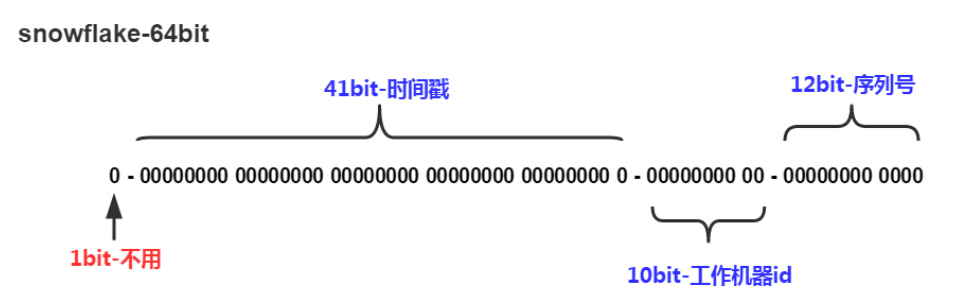
- 1 bit:不用
因为二进制里第一个bit为如果是1,那么都是负数,但是我们生成的id都是正数,所以第一个bit统一都是0 - 41 bit:表示的是时间戳,单位是ms
41 bit可以表示的数字多达2^41 - 1,也就是可以标识2 ^ 41 - 1个毫秒值,换算成年就是表示69年的时间 - 10 bit:记录工作机器id
代表的是这个服务最多可以部署在2^10台机器上哪,也就是1024台机器,但是10 bit里5个bit代表机房id,5个bit代表机器id。意思就是最多代表2 ^ 5个机房(32个机房),每个机房里可以代表2 ^ 5个机器(32台机器)。 - 12 bit:记录同一个毫秒内产生的不同id
12 bit可以代表的最大正整数是2 ^ 12 - 1 = 4096,也就是说可以用这个12bit代表的数字来区分同一个毫秒内的4096个不同的id
缺点:
依赖于系统时钟的一致性。如果某台机器的系统时钟回拨,有可能造成ID冲突,或者ID乱序、ID重复
优点:
- 生成ID时不依赖于数据库,完全在内存生成,高性能高可用
- 容量大,每秒可生成几百万ID
- ID呈趋势递增,后续插入数据库的索引树的时候,性能较高

 浙公网安备 33010602011771号
浙公网安备 33010602011771号