requests用法基础-进阶
-
模块的安装
-----------------------基础用法---------------------
-
GET用法、POST用法
-----------------------进阶用法--------------------
-
cookie处理、代理ip、session
一 模块安装:
1). 安装requests包还是很方便的,电脑中有python环境,打开cmd,输入pip install requests下载;
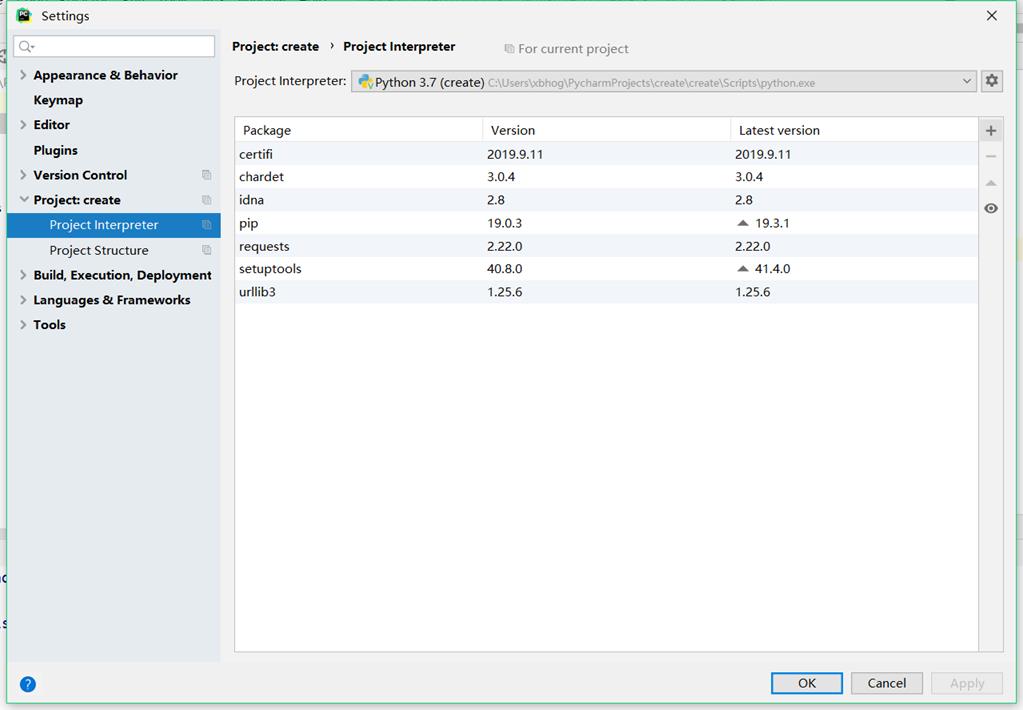
如果有同学使用pycharm的话,选择file-->setting-->Project interpreter-->右边"+"号点击--->输入模块名---->选中下载。
2). requests的作用、特点、以及使用流程
-
作用:模拟用户使用浏览器上网
-
特点:简单、高效
-
使用流程:
-
指定url;
-
发起请求(requests.get/post);
-
获取响应信息/数据(response);
-
持久化存储(保存csv、MySQL、txt等);
-
二基本用法:
1). get(url,headers,params):各用法
获取搜狗首页的页面数据:
1 import requests #引包 2 #1指定url 3 url = 'https://www.sogou.com/' 4 #2.发起请求 5 response = requests.get(url=url) 6 #3获取响应数据 7 page_text = response.text #text返回的是字符串类型的数据 8 #持久化存储 9 with open('./sogou.html','w',encoding='utf-8') as fp: 10 fp.write(page_text) 11 print('over!') 12 #也可以直接打印 13 print(page_text) #这就是服务器给我们返回的数据信息(response)
2). headers的使用:
如果没有伪装UA,你发送的请求中的UA是一个爬虫标识;而且现在大部分网站都是有UA检测(反爬机制),所以我们需要UA伪装(反反爬策略)骗过网站,
-
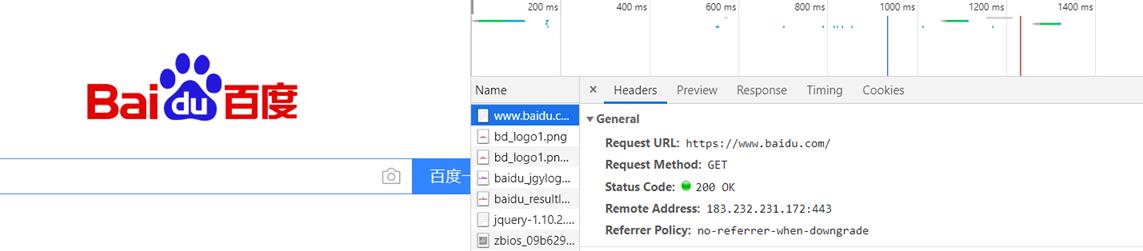
我们可以打开网站,F12,随意点击一个信息,找到Headers这个标签,翻到最下面有一个 User-Agent ,在python中我们需要对他进行构造。
-
python中有一个随机生成UserAgent的包----fake-useragent,它的安装方法也很简单,pip install fake-useragent。
3). 下面实现上面headers的构造:
1 #第一种方法 2 #user-agent放在字典中,不光useragent,后面我们讲到的cookie等都需要放入 3 import requests 4 headers== { 5 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' 6 } 7 #调用方法,get(传入了两个参数,url,headers) 8 response = requests.get("http://www.baidu.com",headers=headers)
使用fake-useragent获取并构造UA:
import requests from fake_useragent import UserAgent ua = UserAgent() headers = {'User-Agent': ua.random} url = '待爬网页的url' resp = requests.get(url, headers=headers)
4). params 参数
我们使用一个例子来融合headers与params,还是以搜狗为例:
1 import requests 2 wd = input('enter a word:') 3 url = 'https://www.sogou.com/web' 4 #参数的封装 5 param = { 6 'query':wd 7 } 8 #UA伪装 9 headers = { 10 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' 11 } 12 response = requests.get(url=url,params=param,headers=headers) 13 #手动修改响应数据的编码 14 response.encoding = 'utf-8' 15 page_text = response.text 16 fileName = wd + '.html' 17 with open(fileName,'w',encoding='utf-8') as fp: 18 fp.write(page_text) 19 print(fileName,'爬取成功!!!')
上面的例子可以看出,如果需要将参数放在url中传递,可以利用 params 参数 。
5)post用法:我们访问网站的时候,有时候是需要提交数据给网页的,如果提交的数据中没有网站所认证的信息,那么网站将会返回给你错误或者其他信息。
最基本的POST请求:
1 response = requests.post("http://www.baidu.com/",data=data)
传入数据的之后就不需要使用urlencode进行编码了。
实例(实现百度翻译):
1 import requests 2 #破解百度翻译 3 url = 'https://fanyi.baidu.com/sug' 4 word = input('enter a English word:') 5 #请求参数的封装 6 data = { 7 'kw':word 8 } 9 #UA伪装 10 headers = { 11 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' 12 } 13 response = requests.post(url=url,data=data,headers=headers) 14 #text:字符串 json():对象 15 json_dict = response.json() 16 17 print(json_dict)#返回是一个json列表,进行数据提取即可
现在大部分的网站都是通过动态加载(Ajax)该技术加载信息,有的网站防止数据的泄露或者用户隐私安全,会设置js、css字体加密等等;后面有机会在介绍。再举个例子如下,爬取肯德基餐厅位置:
1 #爬取任意城市对应的肯德基餐厅的位置信息 2 #动态加载的数据 3 city = input('enter a cityName:') 4 url = 'http://www.kfc.com.cn/kfccda/ashx/GetStoreList.ashx?op=keyword' 5 #数据封装 6 data = { 7 "cname": "", 8 "pid": "", 9 "keyword": city, 10 "pageIndex": "2", 11 "pageSize": "10", 12 } 13 #UA伪装 14 headers = { 15 'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36' 16 } 17 #返回的数据 18 response = requests.post(url=url,headers=headers,data=data).text 19 print(response)#打印
有人会问怎么看我们需要传输什么参数呢?我们打开网站币乎网站,点击登录,打开开发者模式(谷歌浏览器),输入账号密码后,在标签为Network中的Headers中最下面的Request payload中。如图所示:

我们可以使用模拟参数进行登录(大部分网站进行加密);在后面会讲解谷歌的一些操作以及加密的数据的解决方式,这里暂时略过。
三 cookie、代理ip、session
(1). cookie的介绍:
学习之前简单的了解一下cookie是做什么的,有什么作用;我们在百度上搜索一下,会出来很多的关于cookie的介绍,我截取了一段:
Cookie的作用:
cookie的用途是存储用户在特定网站上的密码和 ID。另外,也用于存储起始页的首选项。在提供个人化查看的网站上,将利用计算机硬驱上的少量空间来储存这些首选项。这样,每次登录该网站时,浏览器将检查是否有cookie。如果有,浏览器将此 cookie 随网页的请求一起发送给服务器 ,有一个基础的概念就行;
接下来我们获取一下cookies:
1 import requests 2 #网址 3 url ="http:///www.baidu。com” 4 #返回响应 5 response = requests.get(url) 6 #获取请求网页的cookies 7 #打印出cookies 8 print(response.cookies)##RequestCookieJar类型,我们使用items方法将其转换成元组,遍历美每个cookie的的名称跟值。 9 #第一种方法 10 for k,v in response.cookies.items(): 11 print(k +"="+ v) 12 #第二种方法 13 print(resp.cookies.get_dict())
我们也可以使用cookie来维持我们在网站上的登录状态,以我学校的网站为例(可以自行找登录网站),首先登录网站,打开F12,进入network面板----headers中,将cookies复制下来放进我们构造的headers中;
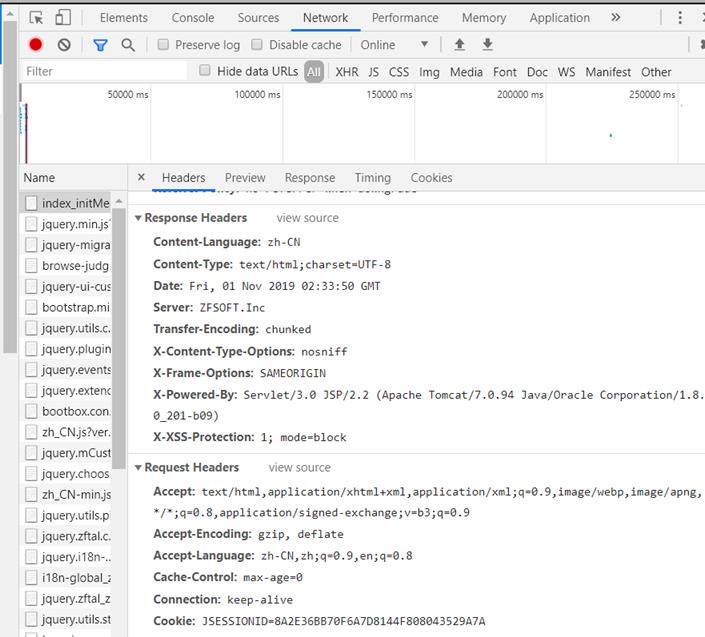
1 import requests 2 3 headers = { 4 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3941.4 Safari/537.36", 5 "Cookie": "JSESSIONID=加密字符串" 6 } 7 8 r = requests.get(url,headers=headers) 9 10 print(r.text)
运行以后就会发现返回来的信息中有登陆后的结果,证明登录成功。
(2)session(会话维持):
多个请求之间是可以共享cookie的。那么如果使用requests,也要达到共享cookie的目的,那么可以使用requests库给我们提供的session对象。注意,这里的session不是web开发中的那个session,这个地方只是一个会话的对象而已。
上面的解释可能有些抽象,打个比方你在爬取一个网站,第一次请求利用post登录了网站,第二次想获取登录成功后的信息,你再使用get方法请求个人信息页面,你发现请求不到,实际上上面的两个操作是打开了两个浏览器,是完全不同的。
所以有需求就有解决方案,这样我们就引出session对象,它可以维持同一个会话,也就是打开一个浏览器的新标签页;这样就防止我们登陆后获取不到信息的烦恼。
以登录人人网为例,使用requests来实现。示例代码如下:
1 import requests 2 3 url = "http://www.renren.com/PLogin.do" 4 data = {"email":"email",'password':"password"} 5 headers = { 6 'User-Agent': "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/62.0.3202.94 Safari/537.36" 7 } 8 9 # 登录 10 session = requests.session() 11 #提交参数信息 12 session.post(url,data=data,headers=headers) 13 14 # 访问大鹏个人中心 15 resp = session.get('http://www.renren.com/880151247/profile') 16 17 print(resp.text)
注:session通常用于模拟登录成功后进行下一步操作。
(3).代理ip的使用
代理ip的使用场合:对于某些网站,我们测试的时候请求几次可以获取网页内容,但是当大规模且频繁的请求,网站可能出现验证码、或者跳到登录认证页面,更有的会直接封掉客户端IP,导致一定的时间内无法访问。
为了防止这种情况的发生,我们需要进行代理操作,代理其实就是代理服务器,代理网站的话自行百度一下。
代理的详情:https://www.kuaidaili.com/doc/wiki/
代理分为下面几种类型:
-匿名度:
- 透明:对方服务器可以知道你使用了代理,并且也知道你的真实IP
- 匿名:对方服务器可以知道你使用了代理,但不知道你的真实IP
- 高匿:对方服务器不知道你使用了代理,更不知道你的真实IP。
- 类型:
- http:该类型的代理ip只可以发起http协议头对应的请求
- https:该类型的代理ip只可以发起https协议头对应的请求
设置代理的方式:
1 import requests 2 proxies = { 3 "http":"ip:端口", 4 "https":"ip:端口", 5 } 6 requests.get(url,proxies=proxies)
requests的get和post方法常用的参数:
-
url
-
headers
-
data/params
-
proxies
你可能看会了,但是你敲了吗?
初学者

 浙公网安备 33010602011771号
浙公网安备 33010602011771号