


算法第二章上机实践报告
实践题目名称:两个有序序列的中位数
问题描述:
题意:
给定两个 大小相等(假设长度为N)的非降序序列S1和S2,求S1和S2的并集的中位数。这里的中位数是指:第⌊(N+1)/2⌋个数,(N为数字个数)。
输入格式:
三行。第一行:序列长度N(范围:0<N≤100000);第二行:S1;第三行:S2。数字间用空格隔开。
输出格式:
一行:S1和S2并集的中位数。结尾无空行。
输入样例:
5
1 3 5 7 9
2 3 4 5 6
输出样例:
4
算法描述:
·首先解读一下题意,不难想到,要找的中位数其实就是S1和S2的并集的第N个数。(N为S1/S2的序列长度)
》》》所以这道题就转化为求两个有序序列并集后的第N个数。
·算法:要得到第N个数,那就删掉前N-1个数。// 删除通过移动指针实现
·要有效实现这一过程:分治策略。(利用给定序列有序这一重要特征,假设当得知第k个数不可能是并集序列的第N个数,那第k个数及其前面的数就都删掉,它们都不可能是第N个数)
》》》分:假设要找第k个数,则分点设置为:k/2。
// 假设数组S1和S2的起始位置 p1 和 p2,则获取比较的数为:S1[p1 - 1 + k/2] 和 S2[p2 - 1 + k/2]。
》》》 治:比较获取到的两个值,若S1[p1 - 1 + k/2] 小于或等于S2[p2 - 1 + k/2],则删掉[p1, p1 - 1 + k/2],否则,删掉[p2, p2 - 1 + k/2]。
// 注意,删掉元素,移动对应指针的同时,还要将 k 不断变小(k -= k/2),k表示还要删掉多少个元素。
循环以上分和治的过程,循环退出条件是:k == 1时,此时,表明已经删了前 k - 1 个数。我们要找的第N个数(中位数)即为 p1 or p2 所指向的数,即 S1[p1] 或 S2[p2]。
解释一个点:
为什么要采取以上的分和治的方法?
答:对于两个有序序列而言,选取k/2作为分点,是因为当S1[p1 - 1 + k/2] 小于S2[p2 - 1 + k/2]时,S1[p1~p1 - 1 + k/2]这些数都不可能是要求得第N个数;而二者相等时的情况可以归入S1[p1 - 1 + k/2] 小于S2[p2 - 1 + k/2]的情况;当S1[p1 - 1 + k/2] 大于S2[p2 - 1 + k/2]时,则反之。
图解:
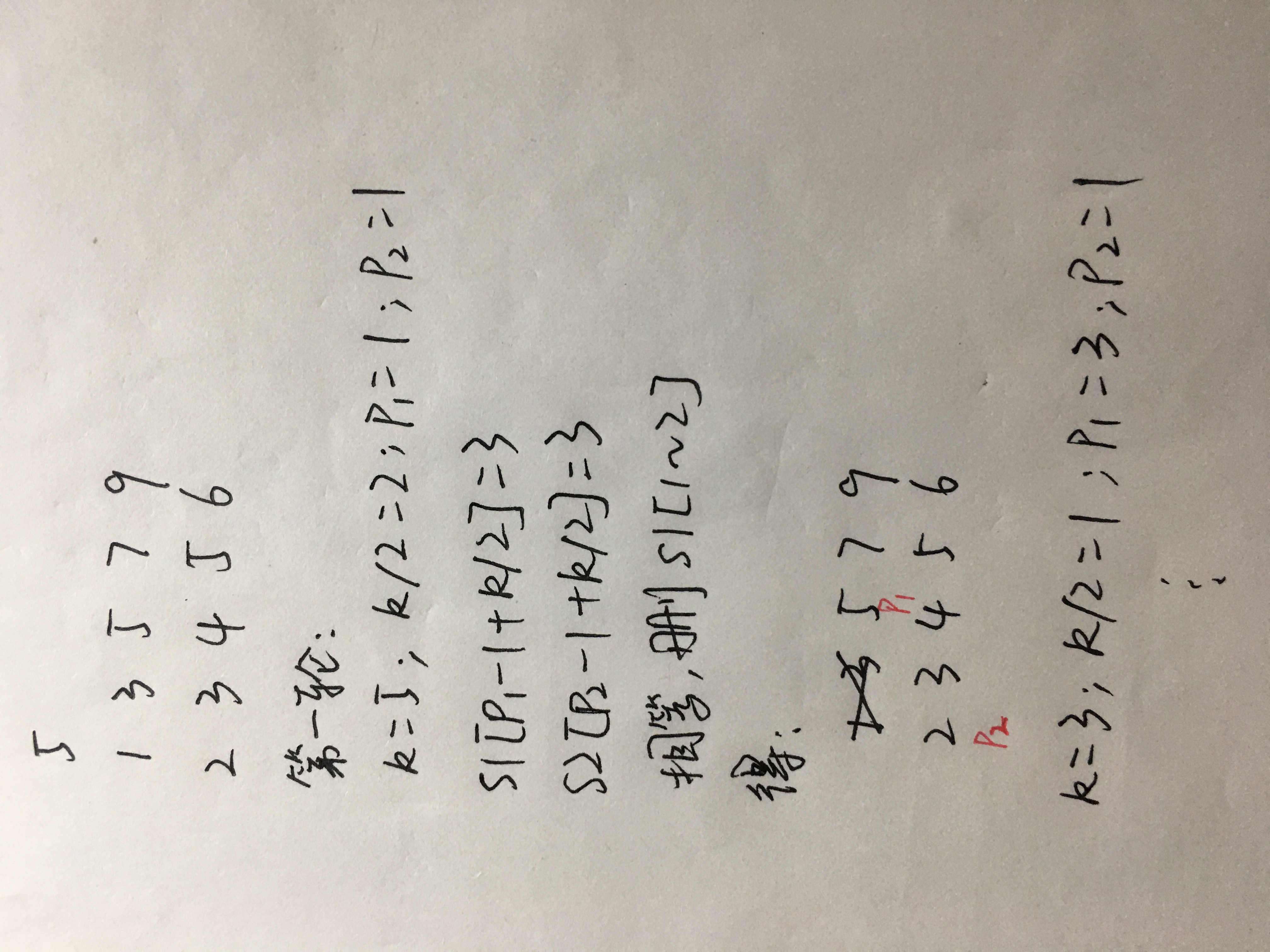
算法时间及空间复杂度分析:
算法的时间复杂度:O(log2N)
// 解释:由于每次都对半分解 N (N为要找的第N个数/数组S1/S2的长度)
算法的空间复杂度:O(1)
// 解释:所有的操作都是在原来的两个序列S1和S2上进行的,不需要开额外的辅助空间。
心得体会:
对于上面那道题,我觉得它的分治策略还是不大好想的。
即使我知道这道题可以用分治,但我最最开始的想法是:在S1中选一个数,然后在S2中寻找这个数所在的区间,以此判断选出来的数是不是要求的中位数。这种想法,我做到后面发现有好些细节不好处理,譬如说,要找的中位数可能在第二个数组中,觉得自己最初的想法切入点错了。然后我重新思考其他办法,自己还是没能想出来,所以就去网上搜了。我看到了力扣上也有类似的题,但是不完全一样(力扣那道我觉得更难些),它刚好有详细的题解,我是看了它的题解后,更新了自己之前愚笨的认知,我理解了它题解的思想后,然后应用到了这一题上,才最后完成这道题的。
以上算法的那种解法有带给我一些新的思考。感觉自己还是积累不够,仍需多磨炼。
分治法的个人体会和思考:
1.一般而言,要采用分治策略,要求处理对象是有序的(进一步说,处理对象是有一定规律特征的),基于这一点,我们才能从局部特征间接推断出其他部分的特征,由此,提高了求解效率。
2.在我看来,能采用分治策略的算法一般都是比较高效的算法。
3.我觉得,“分治”这一思想是不难理解的,老生常谈就是“分而治之”。可是,什么时候用分治以及怎么根据实际问题去应用这一思想,仍需要我们不断加深对分治的理解,多做一下题,不断训练和积累。
我目前自己积累到的可以用分治策略解的实际问题一般有以下特征:a.题目的处理对象或者说输入的数据有一定的规律特征。b.题目的数据规模比较大时,需要高效的算法,可以考虑分治策略。
附:
以上算法部分的参考资料为:4. 寻找两个正序数组的中位数 - 力扣(LeetCode) (leetcode-cn.com)


 浙公网安备 33010602011771号
浙公网安备 33010602011771号