
分布式搜索引擎
分布式搜索引擎
一.特殊问题回顾
1.1特殊问题
从map中取值的时候,如果是数值默认转为Integer,Integer和Long都是包装类型,无法进行强转换,所以文中采用先转换String,后转Long的方式进行处理。
Long goodsId = Long.valueOf(map.get("goodsId").toString());

ps:两个版本需要一致
倒排索引:简单言之,就是从内容到文件,根据内容形成文件ID
1.2一些启动命令
1.2.1基础操作
创建网络:
docker network create es-net
运行docker命令,部署单点es
docker run -d \
--name es \
-e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \
-e "discovery.type=single-node" \
-v es-data:/usr/share/elasticsearch/data \
-v es-plugins:/usr/share/elasticsearch/plugins \
--privileged \
--network es-net \
-p 9200:9200 \
-p 9300:9300 \
elasticsearch:7.12.1
运行docker命令,部署kibana
docker run -d \
--name kibana \
-e ELASTICSEARCH_HOSTS=http://es:9200 \
--network=es-net \
-p 5601:5601 \
kibana:7.12.
1.2.2分词器相关
测试实例:

安装分词器插件:
先找到对应的数据卷所在位置
docker volume inspect es-plugins
对应位置拖入插件:
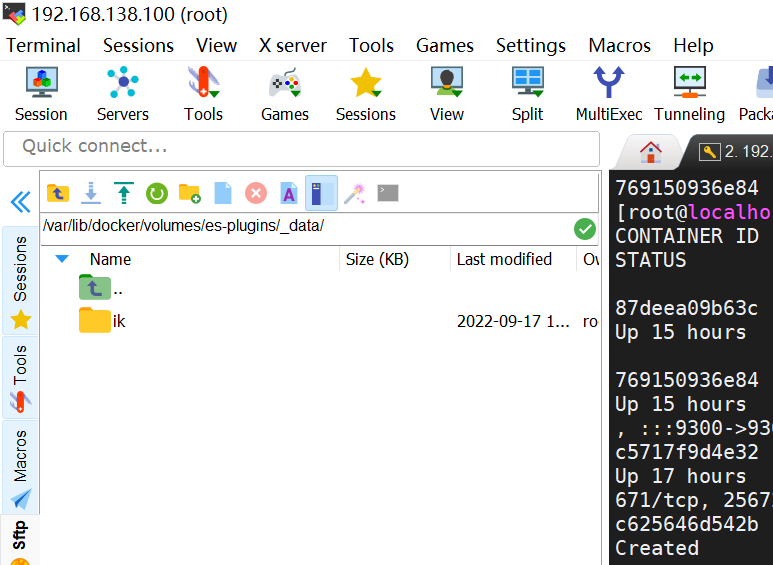
重启es启动:
docker restart es
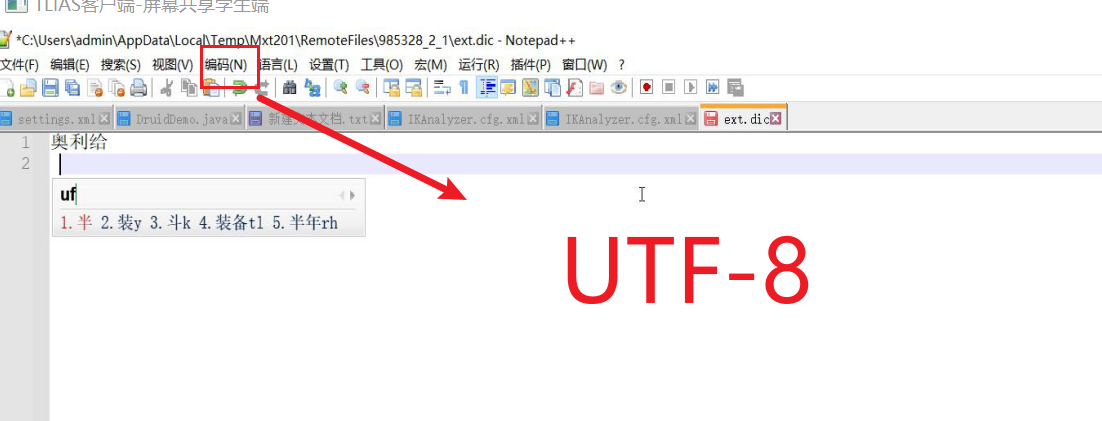
1.2.3额外事项:
添加新词汇与禁用词汇时,编码必须是UTF-8,一个词占一行(ext.dic扩展词在这里添加)
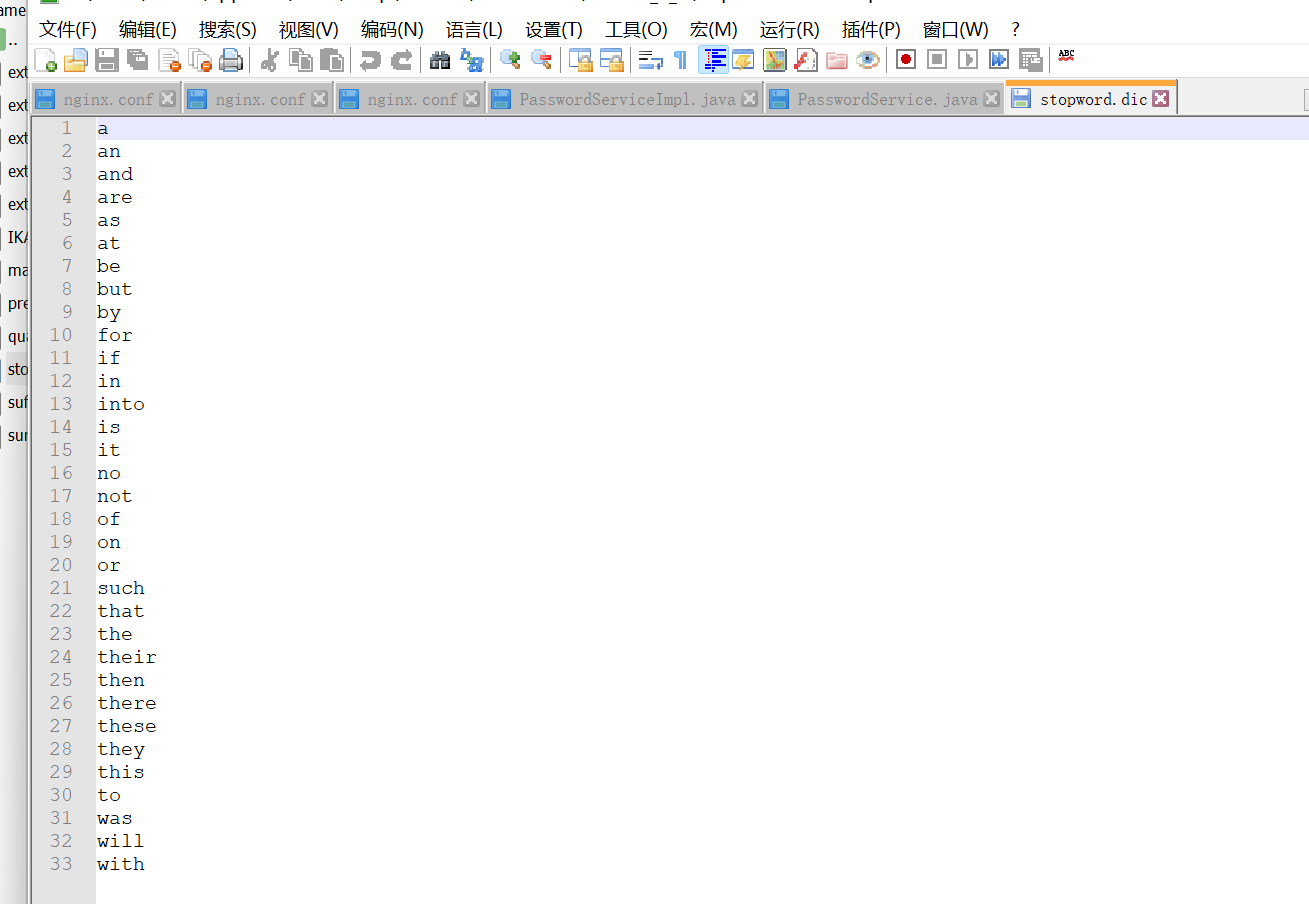
禁用词汇在这里更新:
二.索引库的操作
索引库操作有哪些?
!!!!(有空格隔开)
-
创建索引库:PUT /索引库名
- type:字段数据类型,常见的简单类型有:
- 字符串:text(可分词的文本)、keyword(精确值,例如:品牌、国家、ip地址)
- 数值:long、integer、short、byte、double、float、
- 布尔:boolean
- 日期:date
- 对象:object
- index:是否创建索引,默认为true
- analyzer:使用哪种分词器
- ik_smart:智能切分,粗粒度
- ik_max_word:最细切分,细粒度
- properties:该字段的子字段
- store:默认是true,是否展示给用户看
- type:字段数据类型,常见的简单类型有:
-
PUT /heima { "mappings": { "properties": { "info": { "type": "text", "analyzer": "ik_smart" } } } } -
查询索引库:GET /索引库名
-
删除索引库:DELETE /索引库名
-
添加字段:PUT /索引库名/_mapping
-
PUT /索引库名/_mapping { "properties": { "新字段名":{ "type": "integer" } } }
三.文档操作
文档操作有哪些?()
-
创建文档:POST /{索引库名}/_doc/文档id
-
(_doc此处是固定名称)
(无须所有字段都添加)
(如果不选定ID就是随机生成,post的底层逻辑,详见附post和put的区别)
POST /heima/_doc/1 { "info": "黑马程序员Java讲师", "email": "zy@itcast.cn", "name": { "firstName": "云", "lastName": "赵" } } -
查询文档:GET /{索引库名}/_doc/文档id
-
删除文档:DELETE /{索引库名}/_doc/文档id
-
修改文档:
-
全量修改:PUT /{索引库名}/_doc/文档id
就是把原来的删除,覆盖上新增的,如果没有原id,其实就是新增了
PUT /heima/_doc/1 { "info": "黑马程序员高级Java讲师", "email": "zy@itcast.cn", "name": { "firstName": "云", "lastName": "赵" } } -
增量修改:POST /{索引库名}/_update/文档id
修改指定部分
{
"文档名": {
字段: "内容"
}
-
}
java
POST /heima/_update/1
{
"doc": {
"email": "ZhaoYun@itcast.cn"
}
}
附:PUT和POST的区别 - 腾讯云开发者社区-腾讯云 (tencent.com)
四.引入RestAPI-索引操作
4.1选择Java High Level Rest Client的原因
网上摘录:
restHighLevelClient基于 low level rest client进行了更上层的封装,low level需要自己拼装http请求的url和body, high level有现成的api方法可以直接使用;两者都基于http协议, 性能上应该没有差异。
RestHighLevelClient在ES5.6版本之后引入的,通过HTTP接口访问ES,兼容性好,API更丰富,推荐使用。高并发应用场景,建议配置较大的连接数、配置连接超时时间。
RestHighLevelClient 教程
https://blog.csdn.net/paditang ... 02799
-
个人理解:
High是的对low的升级,更实用.
4.2RestHighLevelClient创建索引时报错[299 Elasticsearch-7.12.1
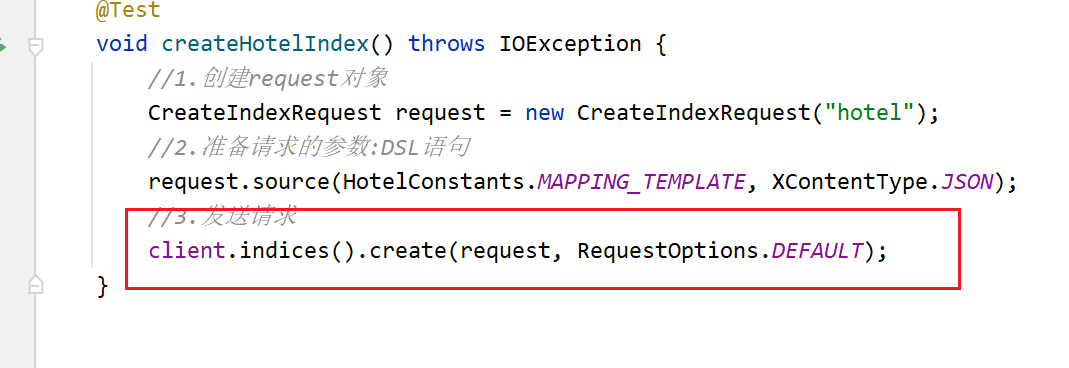
出现原因 : 这是因为在使用create方法时 , 会有两个选择 , 其中一个已经过时了
client.indices().create(request, RequestOptions.DEFAULT);
其中的create方法 , 有两个版本 , 有一个显示已经过时了 , 两个方法虽然名字一样 , 并且需要的参数也一样 , 但是两个的参数CreateIndexRequest是有区别的
导入这个包的时候 , 创建的CreateIndexRequest , 传入create方法中 , 使用的是那个已经过时的create方法 ,
import org.elasticsearch.action.admin.indices.create.CreateIndexRequest;
解决方法:
//导入这个包就可以正常运行了
import org.elasticsearch.client.indices.CreateIndexRequest;
**//查找是否存在时,也会遇到导包的问题
4.3.总结
JavaRestClient操作elasticsearch的流程基本类似。核心是client.indices()方法来获取索引库的操作对象。
索引库操作的基本步骤:
-
初始化RestHighLevelClient
![image-20220918085924980]()
-
创建XxxIndexRequest。XXX是Create、Get、Delete
![image-20220918090012554]()
-
准备DSL( Create时需要,其它是无参)
![image-20220918090034843]()
-
发送请求。调用RestHighLevelClient#indices().xxx()方法,xxx是create、exists、delete
![image-20220918090045918]()




五.RestAPI-文档操作
5.1一些事项
在主键字段id上使用@TableId (value = "id",type = IdType.INPUT),其中type = IdType.INPUT表示用户自定义输入类型,该类型可以通过自己注册自动填充插件进行填充。
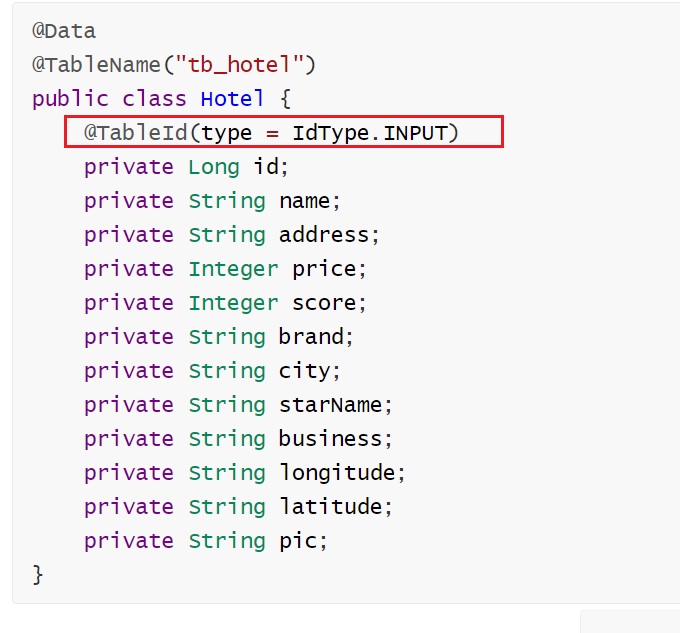
ps:可以再查看详细解释
参考链接:MybatisPlus 主键策略(type=IdType.ASSIGN_ID等详解) - 双间 - 博客园 (cnblogs.com)
mp-plus的注解:
@TableName("tb_hotel")高效开发:@TableName注解 - 掘金 (juejin.cn)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号