程序员必看:4种主流LLM微调手艺,轻松解决模型训练难题
,若数据量不足,模型还容易出现训练偏差,让预期效果大打折扣。就是作为一名开发程序员,当你手握功能强大的语言模型(LLM),期待用它搭建文本分类、搭建智能问答系统、提取文本关键信息等高质量任务时,现实往往会给你出几道难题:训练这类大模型需要海量计算资源和漫长时间,你手头的计算机可能不堪重负;更棘手的
别慌!
今天,我们就来拆解四种主流的LLM微调技术任务麻烦等问题,都能从这些技术中找到适配方案,高效优化模型,从容应对各类应用场景。就是。无论你是面临资源短缺、信息有限,还
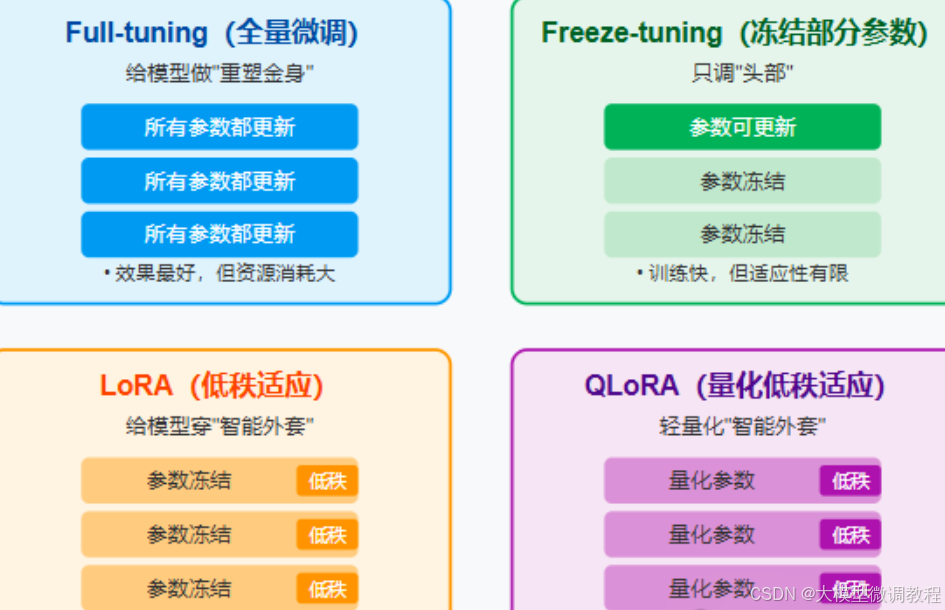
1、Full-tuning(全量微调):深度适配,追求极致效果
LLM优化中最经典的“彻底调整方案”。它的核心逻辑是就是全量微调完整加载预训练模型的所有参数,再用特定任务的标注材料(常见形式为“指令-回答”配对的监督微调数据,即SFT数据)继续训练,让模型的每一个权重参数都得到更新。这种方式就像给模型进行“全方位特训”,适合在你拥有大规模高质量材料、任务逻辑复杂,且配备高性能计算设备(如多块高端GPU)时使用。
实际场景举例:假设你需要开发一个面向精准医疗领域的LLM,用于辅助医生分析病例、生成诊断建议。此时,你可以收集海量的临床病例数据、医学文献解读、医患对话记录等,通过全量微调让通用大模型系统学习医疗领域的专业术语、诊断逻辑和治疗方案,最终形成一个深度适配医疗场景的专业模型,其输出的准确性和专业性能满足临床辅助需求。
1.1 优势
- 适配性极强:能深度挖掘特定任务的核心需求,充分学习任务素材中的规律,最终模型效果通常是四种技术中最出色的,尤其在复杂任务中优势明显。
- 作用扩展性好:由于所有参数都得到更新,模型在完成核心任务的同时,还能灵活应对该领域内衍生出的其他相关任务,比如上述医疗模型不仅能分析病例,还能生成患者随访话术。
1.2 劣势
- 资源消耗巨大:大模型参数规模动辄数亿、数百亿甚至千亿,全量微调需要多台搭载高端显卡(如A100、H100)的服务器协同工作,训练周期可能长达数天甚至数周,硬件成本和时间成本极高。
- 信息依赖度高:需要大量高质量的标注数据才能避免“灾难性遗忘”(即模型忘记预训练阶段学到的通用知识)和过拟合。若数据量不足或质量参差不齐,模型效果会大幅下降,甚至出现输出错误的情况。
- 部署成本高:每个经过全量微调的模型都需要单独存储完整的参数资料,当需要部署多个不同任务的模型时,会占用大量存储空间,且切换模型时操作复杂。
1.3 操作步骤
- 从模型仓库(如Hugging Face Hub)下载预训练完成的LLM权重文件,在本地或服务器环境中加载模型,并确保所有参数均可训练。
- 准备特定任务的标注素材集(如文本分类任务的“文本-类别”配对材料、问答任务的“挑战-答案”配对数据),并对数据进行清洗、格式转换(如转为模型支持的JSON或CSV格式)和划分(训练集、验证集、测试集)。
- 设定训练目标(如最小化交叉熵损失)、优化器(如AdamW)、学习率、 batch size 等超参数,启动训练流程。训练过程中,模型的每一个参数都会根据任务数据不断更新,直至在验证集上的性能达到预期。
- 训练结束后,在测试集上评估模型效果,若满足需求则保存模型权重,用于后续部署;若效果不佳,则需调整超参数或补充数据,重新进行训练。
2、Freeze-tuning(冻结部分参数微调):轻量优化,快速适配
一种“精打细算”的轻量级优化方案,就是冻结部分参数微调核心思路是只对模型的顶层结构(通常是最后2-3层)参数进行调整,而冻结底层和中间层的参数。这种方式就像给模型“局部补课”,不应该改动整体知识体系,因此更适合数据量较少(如仅数千条标注数据)、任务逻辑简单(如情感分析、关键词提取),或计算设备性能有限(如仅有单块中端显卡)的场景。
2.1 优势
- 资源消耗低:仅训练顶层少量参数,训练时的计算量和内存占用大幅降低,普通计算机或单块中端显卡就能支撑训练,训练周期通常只需数小时,时间和硬件成本远低于全量微调。
- 泛化能力强:模型底层和中间层保留了预训练阶段学到的通用语言知识(如语法规则、常识逻辑),不会因微调而丢失,因此在处理任务相关的陌生数据时,不易出现偏差,泛化效果更好。
- 操作门槛低刚接触LLM微调的开发者,也能快速上手操作。就是:无需复杂的参数调整策略,只需确定冻结的层数和训练的顶层结构,即使
2.2 劣势
- 任务适配上限低:由于仅调整顶层参数,模型无法深度学习任务的复杂逻辑和特殊规律。例如,在必须理解繁琐上下文关系的多轮对话任务中,冻结微调的模型往往难以准确捕捉对话意图,效果远不如全量微调或LoRA。
- 灵活性不足:若任务需求发生轻微变化(如情感分析任务从二分类(正面/负面)改为三分类(正面/中性/负面)),可能得重新确定冻结层数和训练结构,无法直接复用之前的微调成果,需要重新训练。
2.3 操作步骤
- 加载预训练LLM,查看模型结构(如Transformer架构的 encoder 或 decoder 层数),明确顶层结构的位置(如最后一个 decoder 模块)。
- 冻结模型底层和中间层的参数:通过代码设置这些层的“requires_grad”属性为False,使其在训练过程中参数不发生变化;同时将顶层结构的“requires_grad”属性设为True,确保参数可训练。
- 准备特定任务的小规模标注数据集,进行简单的数据预处理(如文本截断、tokenize)后,划分训练集和验证集。
- 设定简单的训练超参数(如较低的学习率,避免顶层参数更新过快导致过拟合),启动训练。训练过程中,仅顶层参数根据任务数据更新,底层参数保持不变。
- 训练完成后,在验证集上评估模型效果,若满足需求则保存模型;若效果不佳,可尝试增加解冻的层数(如从冻结最后1层改为冻结最后2层),重新训练。
3、LoRA(低秩适应):智慧调整,兼顾效果与成本
LoRA(Low-Rank Adaptation)是一种“四两拨千斤”的高效微调技术,核心原理是不在原模型参数上直接修改,而是在模型的关键模块(如Transformer的注意力层)中插入两组低秩矩阵(通常记为A矩阵和B矩阵),训练时仅优化这两组矩阵的参数,原模型参数保持冻结。此种方式就像给模型“加装智能插件”,既能让模型适配新任务,又无需大规模改动内部结构,适用于文本分类、问答平台、文本生成等绝大多数自然语言处理任务,尤其适合资源有限但追求较好效果的场景。
实际场景举例:假设你需要为电商平台开发一个商品评论分析模型,用于自动提取评论中的核心观点(如“物流快”“质量差”)并判断情感倾向。此时,你无需对通用大模型进行全量微调,只需在模型注意力层插入LoRA矩阵,用电商评论资料训练这些矩阵。训练完成后,原模型加上LoRA矩阵,就能精准分析商品评论——相当于给通用模型装上了“电商评论分析插件”,既节省资源,又能保证效果。
3.1 优势
- 成本极低:LoRA优化的参数规模仅为全量微调的几百分之一甚至几千分之一(例如,千亿参数模型的LoRA参数可能仅数百万),训练时的计算量和内存占用大幅降低,单块中端显卡就能在数小时内完成训练,效率比全量微调提升上百倍。
- 效果出色:在多数任务中,LoRA微调的效果能接近甚至部分超过全量微调,同时由于原模型参数冻结,不会丢失预训练阶段的通用知识,有效避免过拟合和“灾难性遗忘”。
- 部署灵活:原模型权重只需存储一份,不同任务的LoRA矩阵文件体积极小(通常仅几十MB到几百MB)。部署时,只需加载原模型和对应任务的LoRA矩阵,即可快速切换任务,大幅节省存储空间和部署成本。
3.2 劣势
- 极端复杂任务适配不足:在需要深度挖掘任务底层逻辑的极端繁琐场景(如高精度的法律文书生成、科学论文撰写),LoRA由于仅通过低秩矩阵调整模型输出,无法像全量微调那样彻底优化模型,效果可能略逊一筹。
- 低秩假设局限性:LoRA的核心假设是“任务适配所需的参数变化可通过低秩矩阵表示”,但并非所有任务都满足这一假设。若任务需要的参数变化无法用低秩矩阵近似,LoRA的效果会明显下降。
3.3 操作步骤
- 加载预训练LLM,分析模型结构,确定需要插入LoRA矩阵的关键模块(通常选择Transformer的注意力层中的query和value投影层)。
- 利用LoRA框架(如PEFT库中的LoRA实现),在选定模块中插入低秩矩阵A和B(A矩阵维度通常为“原参数维度×秩”,B矩阵维度为“秩×原参数维度”,秩的取值一般为8-64),并设置LoRA矩阵的参数可训练,原模型参数冻结。
- 准备特定任务的标注素材集,进行常规预处理后,划分训练集、验证集和测试集。
- 设定训练超参数(如学习率可略高于冻结微调,因LoRA参数规模小,需稍高学习率加速收敛),启动训练。训练过程中,仅LoRA矩阵的参数根据任务数据更新,原模型参数保持不变。
- 训练结束后,保存LoRA矩阵的权重文件。部署时,加载原模型和对应的LoRA矩阵,通过矩阵乘法将LoRA的影响融入原模型输出,即可建立任务适配。
4、QLoRA(量化低秩适应):极致压缩,适配边缘设备
QLoRA(Quantized LoRA)是LoRA技术的“轻量化升级版”,先将预训练模型的参数从高精度浮点数(如FP32、FP16)量化为低精度整数(如4-bit、8-bit),完成模型压缩,再在量化后的模型上应用LoRA技能进行微调就是核心。这种方式就像给模型“先瘦身再装插件”,进一步降低资源消耗,专门适合资源极度受限的场景,如智能手机、边缘计算设备(如工业传感器、智能摄像头)等,让LLM能在终端设备上实现本地化微调与部署。
4.1 优势
- 模型体积极小:通过4-bit或8-bit量化,模型体积可压缩至原模型的1/4或1/2(例如,10GB的FP16模型量化为4-bit后仅2.5GB),极大降低了存储需求,便于在存储空间有限的边缘设备上部署。
- 推理速度快:低精度整数运算的计算效率远高于高精度浮点数运算,量化后的模型在推理时能显著提升速度,满足边缘设备对实时性的需求(如智能摄像头实时分析监控文本信息)。
- 微调成本低:继承了LoRA的优势,仅优化少量低秩矩阵参数,即使在边缘设备或普通计算机上,也能快速完成微调,无需依赖高端服务器。
4.2 劣势
- 麻烦任务性能损失:量化过程中会丢失部分参数精度,虽然LoRA能弥补一部分,但在复杂任务(如多轮对话、高精度文本生成)中,仍可能出现输出准确率下降、语言流畅度降低等问题。
- 操作复杂度高:需要掌握模型量化的相关知识(如量化方式选择、量化误差控制),且量化过程中可能出现“量化溢出”“精度骤降”等障碍,需要反复调试参数,执行门槛比普通LoRA更高。
4.3 操作步骤
- 选择支持量化的LLM框架(如Transformers结合bitsandbytes库),加载预训练模型时,将参数量化为低精度整数(如设置load_in_4bit=True或load_in_8bit=True),并借助量化校准(如动态量化、静态量化)减少量化误差。
- 在量化后的模型上,按照LoRA的执行流程,在关键模块中插入低秩矩阵,设置LoRA参数可训练,量化后的原模型参数冻结。
- 准备小规模的特定任务数据集(边缘设备场景通常数据量有限),进行预处理后,划分训练集和验证集。
- 设定适合量化模型的训练超参数(如采用更小的batch size、更低的学习率,避免训练过程中出现梯度爆炸),启动微调。训练过程中,仅优化LoRA矩阵参数,量化后的原模型参数保持不变。
- 训练完成后,保存量化模型权重和LoRA矩阵文件。部署时,将量化模型和LoRA矩阵加载到边缘设备,借助框架支持的量化推理接口,实现本地化任务处理。
5、总结与选择指南:找到最适合你的微调方案
四种LLM微调技术各有侧重,选择时需结合数据量、任务复杂度、设备资源三大核心因素综合判断,以下为具体选择指南:
| 微调技术 | 适用场景 | 核心优势 | 注意事项 |
|---|---|---|---|
| Full-tuning | 数据量庞大(数万条以上)、任务复杂(如专业领域文本生成)、设备资源充足 | 效果最优、适配性极强 | 成本高、需大量高质量数据、部署复杂 |
| Freeze-tuning | 数据量少(数千条以下)、任务便捷(如情感分析)、设备性能一般 | 资源消耗低、操作简单、泛化强 | 任务适配上限低、灵活性不足 |
| LoRA | 多数常规NLP任务(文本分类、问答等)、数据量适中、设备资源有限 | 成本低、效果好、部署灵活 | 极端困难任务效果略逊、依赖低秩假设 |
| QLoRA | 边缘设备(手机、传感器)、资源极度受限、任务对精度要求不极端苛刻 | 模型体积小、推理快、成本低 | 复杂任务性能有损失、操作复杂度高 |
简单来说:
- 若你是企业级开发,有海量数据、高端设备,且追求极致任务效果,选Full-tuning;
- 若你是个人开发者,资料少、任务简单,仅需快捷验证想法,选Freeze-tuning;
- 若你应该平衡效果与成本,应对多数常规任务,且希望灵活部署,选LoRA(性价比首选);
- 若你要求在手机、边缘设备上部署微调模型,资源极度紧张,选QLoRA。
根据实际需求合理选择技术,才能让LLM在你的任务中发挥最大价值,既避免资源浪费,又能高效解决业务问题。
那么,如何系统的去学习大模型LLM?
作为一名从业五年的资深大模型算法工程师,我经常会收到一些评论和私信,我是小白,学习大模型该从哪里入手呢?我自学没有方向怎么办?这个地方我不会啊。如果你也有类似的经历,一定要继续看下去!这些问题啊,也不是三言两语啊就能讲明白的。
因此我综合了大模型的所有知识点,给大家带来一套全网最全最细的大模型零基础教程。在做这套教程之前呢,我就曾放空大脑,以一个大模型小白的角度去重新解析它,采用基础知识和实战项目相结合的教学方式,历时3个月,终于完成了这样的课程,让你真正体会到什么是每一秒都在疯狂输出知识点。
由于篇幅有限,⚡️ 朋友们如果有需全套 《2025全新制作的大模型全套资料》,扫码获取~
为什么要学习大模型?
我国在A大模型领域面临人才短缺,数量与质量均落后于发达国家。2023年,人才缺口已超百万,凸显培养不足。随着AI技术飞速发展,预计到2025年,这一缺口将急剧扩大至400万,严重制约我国AI产业的创新步伐。加强人才培养,优化教育体系,国际合作并进是破解困局、推动AI发展的关键。


大模型学习指南+路线汇总
我们这套大模型资料呢,会从基础篇、进阶篇和项目实战篇等三大方面来讲解。

①.基础篇
基础篇里面包括了Python快速入门、AI开发环境搭建及提示词工程,带你学习大模型核心原理、prompt启用技巧、Transformer架构和预训练、SFT、RLHF等一些基础概念,用最易懂的方式带你入门大模型。
②.进阶篇
接下来是进阶篇,你将掌握RAG、Agent、Langchain、大模型微调和私有化部署,学习如何构建外挂知识库并和自己的企业相结合,学习如何使用langchain框架提高编写效率和代码质量、学习如何选择合适的基座模型并进行数据集的收集预处理以及具体的模型微调等等。
③.实战篇
实战篇会手把手带着大家练习企业级的落地项目(已脱敏),比如RAG医疗问答系统、Agent智能电商客服系统、数字人项目实战、教育行业智能助教等等,从而帮助大家更好的应对大模型时代的挑战。
④.福利篇
最后呢,会给大家一个小福利,课程视频中的所有素材,有搭建AI开发环境资料包,还有学习计划表,几十上百G素材、电子书和课件等等,只要你能想到的素材,我这里几乎都有。我已经全部上传到CSDN,朋友们如果需要可以微信扫描下方CSDN官方认证二维码免费领取【保证100%免费】
相信我,这套大模型系统教程将会是全网最齐全 最易懂的小白专用课!!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号