

图片文字-敏感词过滤,以及使用正则表达式 - 实践
什么是OCR? OCR (Optical Character Recognition,光学字符识别)是指电子设备(例如扫描仪或数码相机)检查纸上打印的字符,通过检测暗、亮的模式确定其形状,然后用字符识别方法将形状翻译成计算机文字的过程

Tesseract-OCR 特点: Tesseract支持UTF-8编码格式,并且可以“开箱即用”地识别100多种语言。 Tesseract支持多种输出格式:纯文本,hOCR(HTML),PDF等 官方建议,为了获得更好的OCR结果,最好提供给高质量的图像。 Tesseract进行识别其他语言的训练 具体的训练方式,请参考官方提供的文档:https://tesseract-ocr.github.io/tessdoc/
使用步骤:
①:创建项目导入tess4j对应的依赖
net.sourceforge.tess4j
tess4j
4.1.1②:导入中文字体库, 把tessdata文件夹拷贝到自己的工作空间下

③:编写测试类进行测试
package com.heima.tess4j;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import java.io.File;
/**
* @author NoFear
* @version 1.0
* @description: TODO
* @date 2025/8/18 22:34
*/
public class Tess4jApplication {
public static void main(String[] args) throws TesseractException {
// 创建实例
ITesseract tesseract = new Tesseract();
// 设置字体路径
tesseract.setDatapath("C:\\code\\workspace_web");
// 设置语言 --->简体中文,匹配文件前缀,通过修改这里的内容,可以实现语言切换
tesseract.setLanguage("chi_sim");
// 图片的路径
File file = new File("C:\\code\\workspace_web\\158.png");
// 识别图片
String result = tesseract.doOCR(file);
System.out.println("识别内容为 " + result.replaceAll("\\r|\\n", "-"));
}
}④提取成一个工具类
package com.heima.common.tess4j;
import lombok.Getter;
import lombok.Setter;
import net.sourceforge.tess4j.ITesseract;
import net.sourceforge.tess4j.Tesseract;
import net.sourceforge.tess4j.TesseractException;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.stereotype.Component;
import java.awt.image.BufferedImage;
@Getter
@Setter
@Component
@ConfigurationProperties(prefix = "tess4j")
public class Tess4jClient {
private String dataPath;
private String language;
public String doOCR(BufferedImage image) throws TesseractException {
//创建Tesseract对象
ITesseract tesseract = new Tesseract();
//设置字体库路径
tesseract.setDatapath(dataPath);
//中文识别
tesseract.setLanguage(language);
//执行ocr识别
String result = tesseract.doOCR(image);
//替换回车和tal键 使结果为一行
result = result.replaceAll("\\r|\\n", "-").replaceAll(" ", "");
return result;
}
}工具类要实现自动⑥装配,要配置
⑥使用
byte数组转bufferedImage,然后使用工具类
for (String image : images) {
byte[] bytes = fileStorageService.downLoadFile(image);
try {
// byte数组转换成imageContent
ByteArrayInputStream in = new ByteArrayInputStream(bytes);
BufferedImage bufferedImage = ImageIO.read(in);
String imageContent = tess4jClient.doOCR(bufferedImage);
boolean isSensitive = handleSensitiveScan(imageContent, wmNews);
if (!isSensitive)
return isSensitive;
} catch (Exception e) {
e.printStackTrace();
}⑤在使用到这个工具类的微服务的配置文件中添加配置
tess4j:
dataPath: C:\code\workspace_web #字体库所在路径
language: chi_sim #设置语言,即要使用的字体库这里用到了正则表达式:
String result = text.replace("\r", "-").replace("\n", "-");
//相当于
result.replaceAll("\\r|\\n", "-")正则表达式(Regular Expression),通常简称为 regex 或 regexp,是一种强大的文本处理工具,用于描述、匹配、查找、替换符合某种规则的字符串模式。
你可以把它理解为:一种“搜索模式语言”,就像在文本中“找东西”的高级说明书。
✅ 正则表达式能做什么?

基本语法(常用符号)
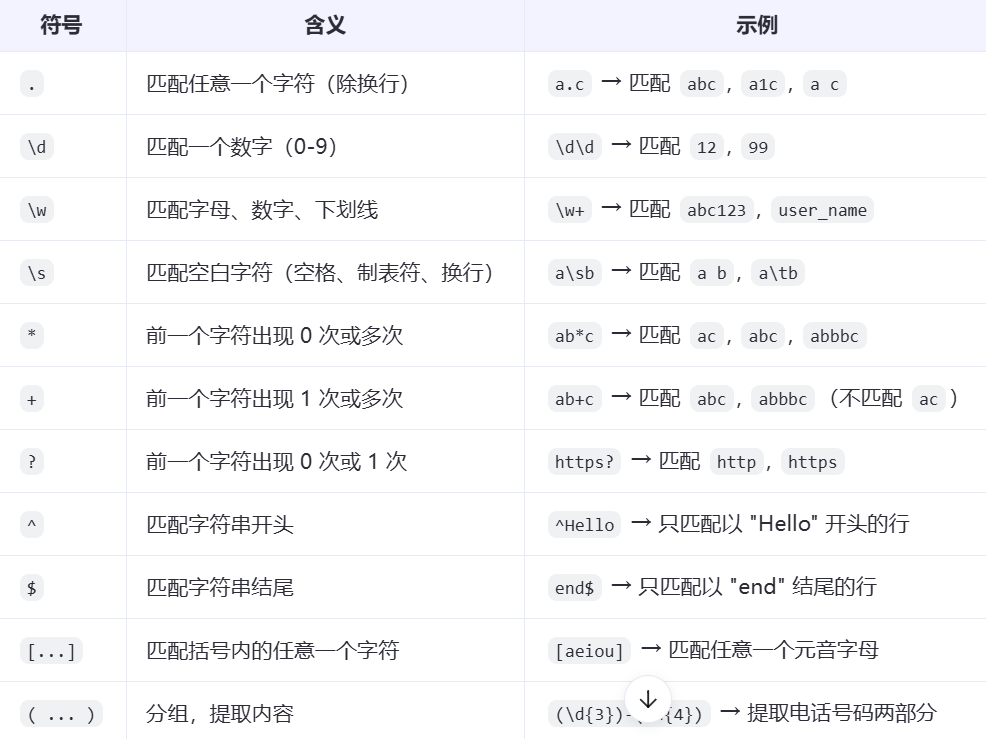
✅ 实际例子
1. 如验证手机号
^1[3-9]\d{9}$解释:
2. 匹配邮箱
^\w+@\w+\.\w+$
匹配:xxxx@example.com,xxxxxx@abc.cn
3. 匹配日期 YYYY-MM-DD
^1:以 1 开头[3-9]:第二位是 3~9\d{9}:后面跟 9 个数字$:结束
^\d{4}-\d{2}-\d{2}$匹配:2023-12-25,2024-01-01
在编程中怎么用?
Java 示例:
String text = "我的电话是**********,邮箱是 *******@example.com";
// 找手机号
Pattern pattern = Pattern.compile("1[3-9]\\d{9}");
Matcher matcher = pattern.matcher(text);
while (matcher.find()) {
System.out.println("找到手机号:" + matcher.group());
}⚠️ 注意事项
特殊字符要转义:
比如.、*、+、?、$、^等在正则中有特殊含义,如果想匹配字面意义,要用\转义:- 匹配
.com要写成\.,否则.会匹配任意字符
- 匹配
贪婪 vs 懒惰:
*和+默认是“贪婪”的,会尽可能多匹配。可以用*?变成“懒惰”模式。性能问题:
复杂的正则可能很慢,避免在大文本上使用过于复杂的模式。
✅ 总结
正则表达式 = 一套规则语言,用来描述你想要找的文本模式

 浙公网安备 33010602011771号
浙公网安备 33010602011771号