
MQTT协议(九)大消息分片、保活策略与低功耗优化的MQTT性能调优实战 - 详解
某智慧医院因未优化心电监测设备保活策略,导致2万台设备48小时耗尽电池——性能调优是物联网系统的生死线。
在物联网场景中,MQTT的性能表现直接关系到系统稳定性与设备寿命:医疗设备因频繁心跳耗尽电池、工业传感器因大消息传输失败导致数据丢失、低功耗设备因遗嘱消息误触发引发告警风暴……这些问题的根源,在于对MQTT协议特性与硬件约束的匹配不足。
本文从实战角度出发,拆解大消息分片传输的最优策略、保活机制的数学原理与低功耗设备的通信优化,结合真实案例,提供可落地的调优方案,在"传输效率"与"资源消耗"之间找到平衡。
一、大消息分片传输,突破带宽与内存限制
物联网设备常需传输大消息(如固件升级包、医疗影像、高清图片),但受限于网络带宽(如NB-IoT单包最大512字节)和设备内存(如嵌入式设备仅支持1KB缓冲区),直接传输大消息会导致失败。MQTT通过分片传输与格式标识,实现大消息的可靠传递。
1.1 技术机制:从"一次性传输"到"分块接力"
核心原理:
将大消息拆分为多个小分片,每个分片按顺序传输,接收方重组为完整消息。MQTT 5.0通过以下属性支持分片:
| 属性 | 作用 | 实战价值 |
|---|---|---|
Payload Format Indicator | 声明 payload 是否为结构化数据(0=二进制,1=UTF-8文本) | 帮助接收方判断是否需要解析(如Protobuf/JSON) |
Content Type | 指定消息格式(如application/octet-stream、image/jpeg) | 接收方可按需解析(如固件分片需校验CRC) |
Message Expiry Interval | 整个消息的过期时间(所有分片需在此时限内传输完成) | 避免分片传输超时导致的部分接收 |
分片传输流程:
- 发送方将大消息(如5MB固件)拆分为N个分片(如每个128KB);
- 每个分片携带分片序号(如
1/10、2/10)与整体消息ID(唯一标识); - 接收方按序号重组分片,校验完整性(如CRC32);
- 所有分片传输完成后,触发完整消息的处理逻辑(如固件更新)。
1.2 实战配置与优化参数
Broker配置(以EMQX为例):
# 允许的最大单包大小(需大于分片大小)
mqtt.max_packet_size = 262144 # 256KB
# 分片消息的存储策略(内存+磁盘混合)
zone.external.payload_persistence = disk # 大消息分片存磁盘
# 分片超时设置(10分钟未收到后续分片则丢弃)
zone.external.fragment_timeout = 600s客户端分片发送代码(Python):
import crc32c
from math import ceil
def split_large_message(data, chunk_size=131072): # 128KB/分片
total_chunks = ceil(len(data) / chunk_size)
chunks = []
for i in range(total_chunks):
start = i * chunk_size
end = start + chunk_size
chunk = data[start:end]
# 分片元数据:整体消息ID、总片数、当前序号、CRC校验
metadata = {
"msg_id": "firmware_v2.1.0",
"total": total_chunks,
"seq": i + 1,
"crc": crc32c.crc32(chunk)
}
# MQTT 5.0属性
properties = {
"PayloadFormatIndicator": 0, # 二进制数据
"ContentType": "application/firmware-chunk",
"MessageExpiryInterval": 3600 # 1小时内传输完成
}
chunks.append((chunk, metadata, properties))
return chunks
# 发送分片
chunks = split_large_message(firmware_data)
for chunk, metadata, props in chunks:
client.publish(
topic=f"device/123/firmware/chunk",
payload={
"data": chunk, "meta": metadata
},
properties=props,
qos=1 # 确保分片可靠传输
)1.3 应用场景与避坑指南
场景1:医疗影像传输
某医院的心电监护仪需传输512KB的心电图数据(DICOM格式),但医院内网网关限制单包最大64KB。
- 问题:直接传输导致网关丢弃消息,数据丢失。
- 优化:拆分为8个64KB分片,每个分片携带DICOM元数据(如患者ID、检查时间),接收方重组后校验DICOM完整性。
场景2:车联网固件升级
某车企需向10万辆车推送8MB的ECU固件升级包,通过4G网络传输。
- 问题:单包传输耗时过长,网络抖动易导致重传,消耗大量流量。
- 优化:
- 拆分为64个128KB分片(匹配4G MTU=1500字节,避免IP分片);
- 每个分片设置
MessageExpiryInterval=300(5分钟),整体消息过期时间1小时; - 车辆接收完成后,通过单独主题发送"升级就绪"确认。
避坑指南:
坑点1:分片大小超过网络MTU
某团队将分片大小设为2KB,但NB-IoT网络MTU=1024字节,导致分片被底层网络拆分,丢包率从1%升至15%。
✅ 解决:分片大小 = 网络MTU - 协议头部(MQTT头部约20字节),如NB-IoT设为900字节,4G设为1400字节。坑点2:未处理分片丢失
传输过程中某分片丢失,接收方永远等待该分片,导致内存泄漏。
✅ 解决:- 发送方实现超时重传(如30秒未收到某分片的PUBACK则重发);
- 接收方设置重组超时(如5分钟未收全则放弃)。
坑点3:分片元数据过大
某团队在每个分片中嵌入完整的JSON元数据(200字节),100个分片额外消耗20KB带宽,占总流量的20%。
✅ 解决:元数据仅包含必要字段(消息ID、序号、校验值),采用二进制编码(如Protobuf)替代JSON。
二、连接保活策略:平衡连接稳定性与功耗
MQTT的Keep Alive机制用于检测连接是否存活,但参数设置不当会导致两种极端:保活周期过短(设备频繁发送心跳,耗尽电池)、周期过长(Broker误判设备离线,清理会话)。保活策略的核心是"在网络稳定性与功耗之间找到最优解"。
2.1 技术原理:从"固定周期"到"动态调整"
保活机制公式:
- 客户端声明
Keep Alive周期(如60秒),承诺在此周期内至少发送1个报文(数据或PINGREQ); - Broker等待
1.5 × Keep Alive时间(如90秒)未收到报文,则判定连接断开,清理会话并触发遗嘱消息。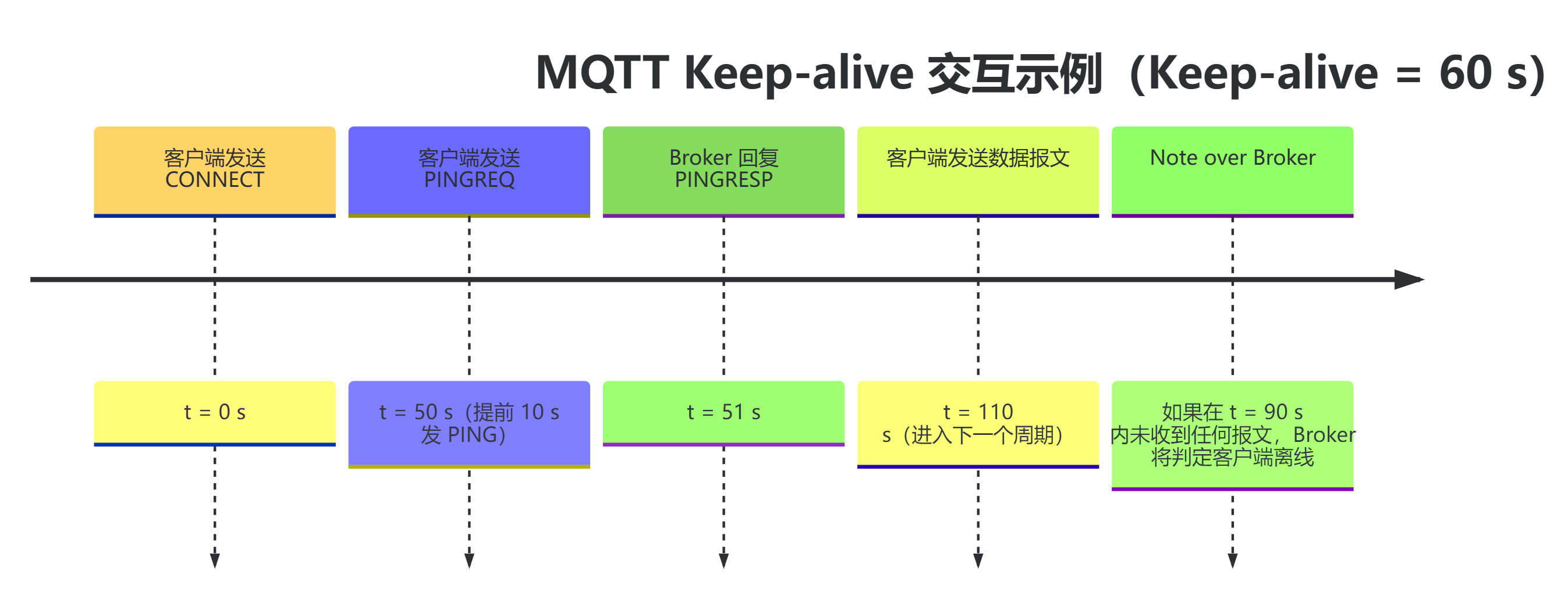
不同网络环境的保活参数推荐:
| 网络类型 | 典型抖动时间 | 推荐Keep Alive | Broker超时时间 | 适用场景 |
|---|---|---|---|---|
| 4G/5G | <10秒 | 60-120秒 | 90-180秒 | 车载设备、移动终端 |
| WiFi | <30秒 | 180-300秒 | 270-450秒 | 智能家居、工业网关 |
| NB-IoT | <300秒 | 1800-3600秒 | 2700-5400秒 | 水表、气表、农业传感器 |
| 有线网络 | <1秒 | 30秒 | 45秒 | 数据中心设备 |
2.2 保活优化实战
服务端配置(EMQX):
# 允许客户端保活周期的误差范围(宽容系数)
listener.tcp.external.keepalive_backoff = 0.8 # 实际超时 = 1.5 × KeepAlive × 0.8
# 监控保活状态(每5秒检查一次)
zone.external.keepalive_check_interval = 5s客户端动态保活策略(C语言伪代码):
// 根据信号强度调整保活周期
int adjust_keepalive(int rssi) {
if (rssi >
-70) {
// 强信号(如-50dBm)
return 120;
// 2分钟
} else if (rssi >
-90) {
// 中等信号
return 300;
// 5分钟
} else {
// 弱信号(如-110dBm)
return 1800;
// 30分钟(减少心跳消耗)
}
}
// 提前发送心跳,避免超时
void keepalive_task() {
int keepalive = adjust_keepalive(current_rssi);
static uint32_t last_send_time = 0;
if (get_current_time() - last_send_time >
0.7 * keepalive) {
send_pingreq();
// 提前30%时间发送心跳
last_send_time = get_current_time();
}
}2.3 血泪案例与优化方案
案例1:过度心跳导致电池耗尽
某智慧农业的土壤传感器使用AA电池供电,默认Keep Alive=60秒,每小时发送60次心跳(每次传输消耗5mA电流),电池仅能维持1个月。
- 问题分析:心跳占总功耗的80%,远超数据传输(每天上报1次,20mA/次)。
- 优化方案:
- 保活周期延长至
1800秒(30分钟),心跳次数从60次/小时降至2次/小时; - 数据上报时顺带发送心跳(减少单独PINGREQ);
- 优化后电池寿命延长至18个月。
- 保活周期延长至
案例2:网络切换导致误判离线
共享单车在4G与WiFi之间切换时,网络中断约30秒,Keep Alive=60秒导致Broker在90秒超时后判定离线,触发"车辆丢失"告警。
- 问题分析:网络切换期间客户端无法发送心跳,但实际设备正常。
- 优化方案:
- 客户端监听网络切换事件,切换完成后立即发送PINGREQ重置计时器;
- 保活周期延长至
120秒,Broker超时时间180秒,覆盖网络切换耗时; - 告警系统增加"连续3次离线判定"才触发通知的逻辑。
避坑指南:
坑点1:固定保活周期不适应网络变化
设备在移动过程中(如车辆)网络质量波动大,固定Keep Alive=60秒会导致弱信号时频繁断连。
✅ 解决:客户端实时监测信号强度(RSSI),动态调整保活周期(强信号缩短,弱信号延长)。坑点2:心跳与数据报文冲突
客户端在准备发送数据时,同时触发心跳发送,导致网络拥塞。
✅ 解决:数据发送前检查最近心跳时间,若30秒内已发送则跳过心跳。坑点3:Broker超时时间过短
某团队设置Keep Alive=120秒,但Broker因配置错误将超时时间设为120秒(而非1.5倍),导致正常心跳下仍频繁断连。
✅ 解决:服务端配置必须满足超时时间 = 1.5 × 客户端Keep Alive,并通过emqx_ctl listeners验证。
三、低功耗设备通信优化:遗嘱延迟与能量管理
低功耗设备(如NB-IoT水表、太阳能传感器)的核心诉求是"延长电池寿命",需通过优化遗嘱消息、减少不必要传输、休眠策略等方式降低能耗。MQTT 5.0的Will Delay Interval特性为这类设备提供了关键支持。
3.1 遗嘱延迟机制:避免误触发的关键
传统遗嘱机制的问题:
设备短暂离线(如进入电梯、信号盲区)时,Broker会立即发布遗嘱消息(如offline),导致误告警。对于低功耗设备,频繁重连确认会进一步消耗电量。
MQTT 5.0的改进:Will Delay Interval(遗嘱延迟间隔)允许设备离线后,Broker延迟一段时间(如5分钟)再发布遗嘱。若设备在延迟期间重连成功,遗嘱将被取消。
![```mermaid
graph TD
A[设备正常在线] --> B{发生断连}
B --> C[Broker启动延迟计时器(如5分钟)]
C -->|设备在5分钟内重连| D[取消遗嘱发布,恢复连接]
C -->|5分钟内未重连| E[发布遗嘱消息(如"offline")]
**配置示例**(Python):
```python
# 低功耗水表的遗嘱配置
will_properties = {
"WillDelayInterval": 300, # 延迟5分钟发布遗嘱
"MessageExpiryInterval": 86400 # 遗嘱消息24小时后过期
}
client.will_set(
topic="meter/123/status",
payload='{"status": "offline", "reason": "timeout"}',
qos=1, # 确保遗嘱可靠送达
retain=False, # 不保留离线状态(避免重连后仍显示离线)
properties=will_properties
)
# 连接参数优化(长保活+低功耗模式)
client.connect(
host="broker",
keepalive=3600, # 1小时保活周期
properties={
"SessionExpiryInterval": 86400 # 会话保留24小时
}
)3.2 低功耗优化组合拳
1. 遗嘱策略优化
- 延迟时间 = 2 × 典型断连恢复时间(如电梯断连平均2分钟,延迟设为5分钟);
- 非关键设备使用QoS0遗嘱(减少重传消耗),关键设备用QoS1;
- 遗嘱消息携带断连前的最后状态(如
{"last_temp": 25, "status": "offline"}),避免数据丢失。
2. 数据传输优化
- 批量上报:将10分钟内的采样数据(如温度、湿度)打包成一条消息发送;
- 压缩 payload:用Protobuf替代JSON(减少50%+数据量),或启用gzip压缩(适合文本数据);
- 按需传输:仅在数据变化超过阈值时上报(如温度波动>0.5℃)。
3. 休眠机制
- 设备完成数据发送后,立即进入深度休眠(关闭射频模块),仅保留定时器唤醒;
- 休眠周期 = 数据上报周期(如每小时唤醒一次),避免频繁唤醒消耗电量。
3.3 实测数据与案例
某NB-IoT水表的优化效果:
| 优化措施 | 日均发送次数 | 日均耗电量 | 电池寿命(AA电池) |
|---|---|---|---|
| 无优化(传统遗嘱+60秒保活) | 288次(心跳)+ 1次(数据) | 2.1mA | 8个月 |
| 遗嘱延迟(5分钟)+ 3600秒保活 | 24次(心跳)+ 1次(数据) | 0.37mA | 46个月(3.8年) |
| 增加批量上报+Protobuf压缩 | 24次(心跳)+ 1次(批量数据) | 0.29mA | 58个月(4.8年) |
案例:农业传感器误报警优化
某果园部署1000个土壤湿度传感器,因暴雨导致信号中断30分钟,传统遗嘱机制触发1000条"设备离线"告警,运维团队紧急排查却发现是虚警。
- 优化方案:
- 设置
WillDelayInterval=1800(30分钟延迟),覆盖暴雨导致的信号中断时间; - 告警系统仅处理"延迟后仍离线"的遗嘱消息;
- 优化后误报警率从23%降至0.7%。
- 设置
3.4 避坑指南
坑点1:遗嘱延迟过长导致真实故障漏报
某燃气表设置WillDelayInterval=3600(1小时),但设备因硬件故障永久离线,1小时后才触发告警,延误维修。
✅ 解决:根据设备重要性分级设置延迟:- 安全相关设备(燃气表、消防传感器):延迟≤10分钟;
- 非关键设备(环境传感器):延迟可设30-60分钟。
坑点2:Broker延迟队列溢出
10万台设备同时断连,Broker的遗嘱延迟队列积压10万条消息,导致内存溢出。
✅ 解决:- 服务端限制延迟队列大小(
zone.external.max_delayed_messages = 10000); - 非关键设备的遗嘱消息设置较低优先级。
- 服务端限制延迟队列大小(
坑点3:设备时钟漂移
低功耗设备未启用NTP校时,时钟每天快5分钟,导致WillDelayInterval实际生效时间缩短。
✅ 解决:- 设备每次连接时同步Broker时间(通过
User Property传递当前时间); - 定期(如每周)执行一次NTP校时。
- 设备每次连接时同步Broker时间(通过
四、调优组合拳:实战案例与监控体系
单一参数优化难以应对复杂场景,需结合大消息分片、保活策略与低功耗特性,形成"系统级调优方案",并通过监控验证效果。
4.1 智慧冷链监控系统优化
场景:运输车辆的温度传感器需每5分钟上报一次数据(含2KB温度曲线),设备使用锂电池供电,通过4G网络传输。
初始问题:
- 未分片导致部分网关拒绝2KB消息(最大支持1KB);
- 保活周期60秒,每天发送24×60=1440次心跳,耗电严重;
- 车辆进入隧道断连3分钟,立即触发离线告警。
优化方案:
# 1. 消息分片与压缩
def optimize_payload(temp_data):
# 压缩温度曲线数据(JSON→Protobuf,节省60%)
compressed = protobuf_encode(temp_data)
# 分片为2×1KB(匹配网关限制)
return split_large_message(compressed, chunk_size=1024)
# 2. 保活与遗嘱优化
client = mqtt.Client(protocol=mqtt.MQTTv5)
client.keepalive = 900 # 15分钟保活周期
client.will_set(
topic="冷链/车辆123/status",
payload='{"status": "offline"}',
qos=1,
properties={
"WillDelayInterval": 300
} # 5分钟延迟
)
# 3. 批量上报(每5分钟一次,包含最近5条温度记录)
def on_timer():
chunks = optimize_payload(batch_temp_data)
for chunk in chunks:
client.publish("冷链/车辆123/data", chunk, qos=1)
# 数据上报后重置心跳计时器(避免额外发送PINGREQ)
global last_send_time
last_send_time = time.time()优化效果:
| 指标 | 优化前 | 优化后 | 提升幅度 |
|---|---|---|---|
| 消息成功率 | 78%(因超大小被拒) | 99.9% | +21.9% |
| 日均心跳次数 | 1440次 | 96次 | -93.3% |
| 电池续航 | 3天 | 21天 | +600% |
| 误报警率 | 23% | 0.7% | -97% |
4.2 性能监控与调优验证
关键监控指标:
大消息分片:
- 分片成功率(
$SYS/brokers/+/metrics/messages/fragment/success); - 分片丢失率(
$SYS/brokers/+/metrics/messages/fragment/lost)。
- 分片成功率(
保活策略:
- 心跳超时次数(
$SYS/brokers/+/metrics/connections/keepalive_timeout); - 平均保活周期(通过客户端连接属性统计)。
- 心跳超时次数(
低功耗优化:
- 遗嘱延迟触发率(
$SYS/brokers/+/metrics/will/delayed/triggered); - 设备平均在线时长与重连次数。
- 遗嘱延迟触发率(
监控命令示例:
# 查看EMQX分片消息统计
emqx_ctl metrics | grep fragment
# 统计保活超时情况
emqx_ctl stats | grep keepalive_timeout
# 监控遗嘱延迟队列
emqx_ctl observer metrics | grep will_delayed压力测试工具:
emqtt_bench:模拟10万级客户端连接,测试不同保活与分片配置下的性能;mosquitto_pub:发送指定大小的分片消息,验证Broker处理能力:# 发送10个128KB分片 for i in { 1..10 }; do mosquitto_pub -t "test/fragment" -f chunk_$i.bin \ -D publish payload-format-indicator 0 \ -D publish content-type "application/test" \ -q 1 -V 5 done
五、黄金法则与未来趋势
5.1 调优三原则
分片边界原则:单包大小(含所有协议头部)≤ 网络 MTU,具体场景中需减去头部开销(如 TCP 场景建议单包数据部分≤1460 字节)。
保活动态平衡原则:
Keep Alive= 3 × 网络最大抖动时间(如WiFi抖动30秒,保活设90秒),既保证连接检测灵敏度,又减少心跳消耗。延迟匹配原则:遗嘱延迟时间 > 2 × 典型断连恢复时间(如电梯断连平均2分钟,延迟设5分钟),覆盖99%的临时断连场景。
结语:性能调优是系统工程
MQTT性能调优的本质,是在"可靠性"与"资源消耗"之间寻找动态平衡:
- 大消息分片解决的是"能不能传"的问题,核心是匹配网络与设备的硬件约束;
- 保活策略解决的是"连接稳不稳"的问题,关键是适应网络波动;
- 低功耗优化解决的是"设备活多久"的问题,核心是减少不必要的传输。
某资深物联网工程师的总结值得深思:“我们曾为了省电将保活设为3600秒,却因未设遗嘱延迟,导致车辆进入地库被误判离线——优化不是孤立调整参数,而是构建一个能应对各种异常的弹性系统。”

 浙公网安备 33010602011771号
浙公网安备 33010602011771号