Kafka 集群部署
Kafka是由Apache软件基金会开发的一个开源流处理平台,由Scala和Java编写。Kafka是一种高吞吐量的分布式发布订阅消息系统,它可以处理消费者在网站中的所有动作流数据。 这些数据通常是由于吞吐量的要求而通过处理日志和日志聚合来解决。 对于像Hadoop一样的日志数据和离线分析系统,但又要求实时处理的限制,这是一个可行的解决方案。Kafka的目的是通过Hadoop的并行加载机制来统一线上和离线的消息处理,也是为了通过集群来提供实时的消息。Kafka是一种高吞吐量的分布式发布订阅消息系统: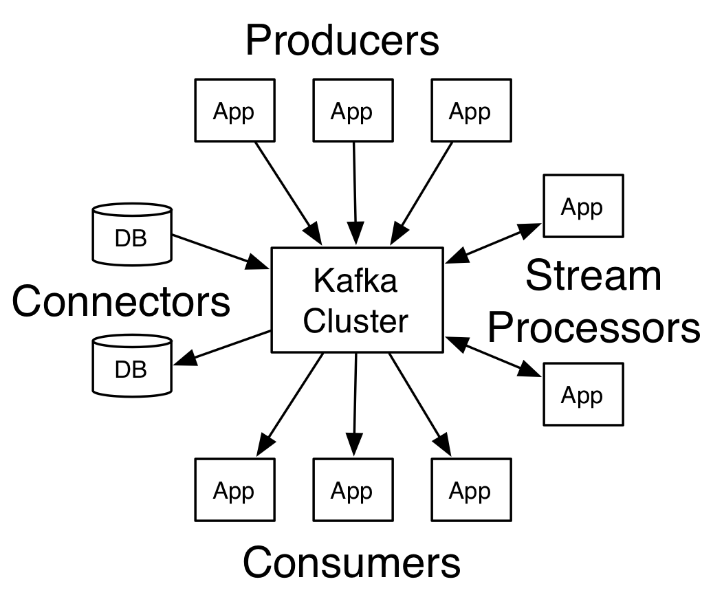
(1)通过O的磁盘数据结构提供消息的持久化,够保持长时间的稳定性能。
(2)高吞吐量:即使是非常普通的硬件Kafka也可以支持每秒数百万的消息。
(3)支持通过Kafka服务器和消费机集群来分区消息。
(4)支持Hadoop并行数据加载。
本博客主要以:单节点单Broker部署、单节点多Broker部署、集群部署(多节点多Broker)来讲解。在实际生产环境中常用的是第三种方式,以集群的方式来部署Kafka。Kafka比较依赖zookeeper集群,如果想要使用Kafka,就必须部署zookeeper集群,Kafka中的消费偏置信息、kafka集群、topic信息会被存储在ZK中。
在部署集群前,需要部署部署zookeeper集群,直接按照zookeeper3.5.5集群部署部署并启动。
一、Kafka 单节点部署
准备:
关闭防火墙:systemctl stop firewalld.service
禁止防火墙自动启动:systemctl disable firewalld.service
关闭selinux : setenforce 0
禁止selinux启动:vim /etc/selinux/config
SELINUX=disabled
各节点的host解析:
10.0.0.11 node01
10.0.0.12 node02
10.0.0.13 node03
1.Kafka 单节点单Broker部署及使用
wget http://mirrors.tuna.tsinghua.edu.cn/apache/kafka/2.2.1/kafka_2.12-2.2.1.tgz
安装
tar xf kafka_2.12-2.2.1.tgz -C /usr/local/src ln -s /usr/local/src/kafka_2.12-2.2.1 /usr/local/kafka
配置kafka
参考官网:http://kafka.apache.org/quickstart
mkdir -p /data/kafka/logs
添加环境变量
echo -e 'export KAFKA_HOME=/usr/local/kafka\nexport PATH=$KAFKA_HOME/bin:$PATH' >>/etc/profile
source /etc/profile
进入kafka的config目录下,在server.properties文件,添加如下配置
vim /usr/local/kafka/config/server.properties
#broker id 全局唯一 broker.id=0 #监听 port=9092 #日志目录 log.dirs=/data/kafka/logs #配置zookeeper的连接 zookeeper.connect=node01:2181
启动kafka
kafka-server-start.sh $KAFKA_HOME/config/server.properties
打印的日志信息没有报错,可以看到如下信息
[2019-06-16 17:44:14,757] INFO [KafkaServer id=0] started (kafka.server.KafkaServer)
但是并不能保证Kafka已经启动成功,输入jps查看进程,如果可以看到Kafka进程,表示启动成功
[root@node01 ~]# jps 8577 QuorumPeerMain 11000 Jps 1899 -- process information unavailable 10637 Kafka [root@node01 ~]# jps -m 8577 QuorumPeerMain /usr/local/zookeeper/bin/../conf/zoo.cfg 1899 -- process information unavailable 10637 Kafka config/server.properties 11022 Jps -m
创建topic
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 1 --partitions 1 --topic test
参数说明:
--zookeeper:指定kafka连接zk的连接url,该值和server.properties文件中的配置项{zookeeper.connect}一样
--replication-factor:指定副本数量
--partitions:指定分区数量
--topic:主题名称
删除主题
kafka-topics.sh --delete --zookeeper node01:2181 --topic test
查看所有的topic信息
kafka-topics.sh --list --zookeeper node01:2181 test
启动生产者
kafka-console-producer.sh --broker-list node01:9092 --topic test
启动消费者
kafka-console-consumer.sh --bootstrap-server node01:9092 --from-beginning --topic test
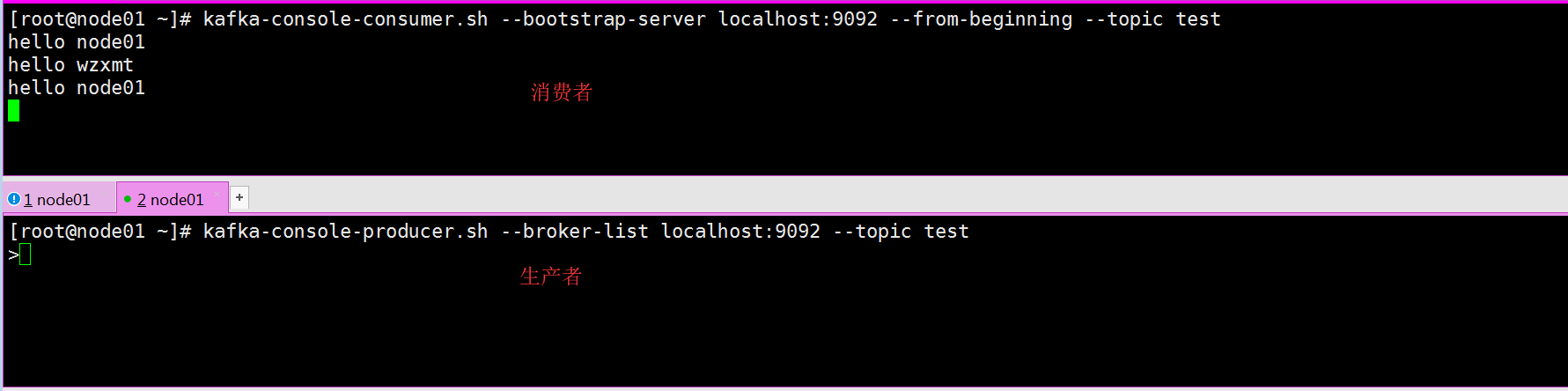
备注
--from-beginning:如果有表示从最开始消费数据,旧的和新的数据都会被消费,而没有该参数表示只会消费新产生的数据。
2.Kafka 单节点多Broker部署及使用
配置Kafka
参考官网:http://kafka.apache.org/quickstart
拷贝server.properties三份
cd /usr/local/kafka/config/ cp server.properties server-1.properties cp server.properties server-2.properties cp server.properties server-3.properties
修改server-1.properties
vim /usr/local/kafka/config/server-1.properties
#broker id 全局唯一 broker.id=1 #监听 port=9093 #日志目录 log.dirs=/data/kafka/logs-1 #配置zookeeper的连接 zookeeper.connect=node01:2181
修改server-2.properties
vim /usr/local/kafka/config/server-2.properties
#broker id 全局唯一 broker.id=2 #监听 port=9094 #日志目录 log.dirs=/data/kafka/logs-2 #配置zookeeper的连接 zookeeper.connect=node01:2181
修改server-3.properties
vim /usr/local/kafka/config/server-3.properties
#broker id 全局唯一 broker.id=3 #监听 port=9095 #日志目录 log.dirs=/data/kafka/logs-3 #配置zookeeper的连接 zookeeper.connect=node01:2181
创建日志文件夹
mkdir -p /data/kafka/{logs-1,logs-2,logs-3}
启动Kafka(分别启动server1、2、3)
kafka-server-start.sh $KAFKA_HOME/config/server-1.properties kafka-server-start.sh $KAFKA_HOME/config/server-2.properties kafka-server-start.sh $KAFKA_HOME/config/server-3.properties
查看进程
[root@node01 ~]# jps 8577 QuorumPeerMain 18353 Jps 17606 Kafka 1899 -- process information unavailable 17243 Kafka 17964 Kafka [root@node01 ~]# jps -m 8577 QuorumPeerMain /usr/local/zookeeper/bin/../conf/zoo.cfg 17606 Kafka /usr/local/kafka/config/server-2.properties 1899 -- process information unavailable 17243 Kafka /usr/local/kafka/config/server-1.properties 18363 Jps -m 17964 Kafka /usr/local/kafka/config/server-3.properties
创建topic(指定副本数量为3)
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 3 --partitions 1 --topic wzxmt
查看所有的topic信息
kafka-topics.sh --list --zookeeper node01:2181

查看某个topic的详细信息
kafka-topics.sh --describe --zookeeper node01:2181 --topic wzxmt

启动生产者
kafka-console-producer.sh --broker-list node01:9093,node01:9094,node01:9095 --topic wzxmt
启动消费者
kafka-console-consumer.sh --bootstrap-server node01:2181 --from-beginning --topic wzxmt

单节点多borker容错性测试
Kafka是支持容错的,上面我们已经完成了Kafka单节点多Blocker的部署,下面我们来对Kafka的容错性进行测试,测试步骤如下
(1).查看topic的详细信息,观察那个blocker的角色是leader,那些blocker的角色是follower
kafka-topics.sh --describe --zookeeper node01:2181 --topic wzxmt

(2).手工kill掉任意一个状态是follower的borker,测试生成和消费信息是否正确
步骤1中可以看到 1为leader,2 和 3为 follower,将follower为2的进程kill掉

启动生产和消费者测试信息是否正确

结论:kill掉任意一个状态是follower的broker,生成和消费信息正确,不受任何影响.
(3).手工kill掉状态是leader的borker,测试生产和消费的信息是否正确
borker1的角色为leader,将它kill掉,borker 3变成了leader .

启动生产和消费者测试信息是否正确.

结论:kill掉状态是leader的borker,生产和消费的信息正确
总结:不管当前状态的borker是leader还是follower,当我们kill掉后,只要有一个borker能够正常使用,则消息仍然能够正常的生产和发送。即Kafka的容错性是有保证的!
二、Kafka 多节点部署(多节点多borker)
在多个节点进行安装部署,部署方式与前面单节点一样。
修改配置文件server.properties
vim /usr/local/kafka/config/server.properties
#broker的全局唯一编号,不能重复,只能是数字
broker.id=1
#此处的host.name为本机IP(重要),如果不改,则客户端会抛出:Producerconnection to node01:9092 unsuccessful 错误!
host.name=10.0.0.11
#用来监听链接的端口,producer或consumer将在此端口建立连接
port=9092
#处理网络请求的线程数量
num.network.threads=3
#用来处理磁盘IO的线程数量
num.io.threads=8
#发送套接字的缓冲区大小
socket.send.buffer.bytes=102400
#接受套接字的缓冲区大小
socket.receive.buffer.bytes=102400
#请求套接字的缓冲区大小
socket.request.max.bytes=104857600
#kafka消息存放的路径(持久化到磁盘)
log.dirs=/data/kafka/logs
#topic在当前broker上的分片个数
num.partitions=2
#用来恢复和清理data下数据的线程数量
num.recovery.threads.per.data.dir=1
#segment文件保留的最长时间,超时将被删除
log.retention.hours=168
#滚动生成新的segment文件的最大时间
log.roll.hours=168
#日志文件中每个segment的大小,默认为1G
log.segment.bytes=1073741824
#周期性检查文件大小的时间
log.retention.check.interval.ms=300000
#日志清理是否打开
log.cleaner.enable=true
#broker需要使用zookeeper保存meta数据
zookeeper.connect=node01:2181,node02:2181,node03:2181
#zookeeper链接超时时间
zookeeper.connection.timeout.ms=6000
#partion buffer中,消息的条数达到阈值,将触发flush到磁盘
log.flush.interval.messages=10000
#消息buffer的时间,达到阈值,将触发flush到磁盘
log.flush.interval.ms=3000
#删除topic需要server.properties中设置delete.topic.enable=true否则只是标记删除
delete.topic.enable=true
#延迟初始使用者重新平衡的时间(生产用3)
group.initial.rebalance.delay.ms=0
#broker能接收消息的最大字节数
message.max.bytes=2000000000
#broker可复制的消息的最大字节数
replica.fetch.max.bytes=2000000000
#消费者端的可读取的最大消息
fetch.message.max.bytes=2000000000
不同节点之间只需要修改server.properties 的 broker.id,broker.id不能相同。
保证zookeeper集群运行正常情况下,启动服务
kafka-server-start.sh -daemon $KAFKA_HOME/config/server.properties
#备注”&“或”-daemon"在后台运行,不占用当前窗口
查看Kafka是否启动成功,输入jps查看进程,如果可以看到Kafka进程,表示启动成功

创建topic
kafka-topics.sh --create --zookeeper node01:2181 --replication-factor 3 --partitions 2 --topic www
查看topic详细信息
kafka-topics.sh --describe --zookeeper node01:2181 --topic www

启动生产者
[root@node01 ~]# kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic www
启动2个消费者
[root@node02 bin]# kafka-console-consumer.sh --bootstrap-server node02:9092 --from-beginning --topic www [root@node03 bin]# kafka-console-consumer.sh --bootstrap-server node03:9092 --from-beginning --topic www

Kafka 集群与单节点多Broker是测试相同,结果相同;从Kafka 单节点多Broker与多节点多Broker的容错性测试,得出的结论是:
不管当前状态的borker是leader还是follower,当我们kill掉后,只要有一个borker能够正常使用,则消息仍然能够正常的生产和发送。即Kafka的容错性是有保证!

 浙公网安备 33010602011771号
浙公网安备 33010602011771号