[中平] 网络爬虫:从入门到放弃-2
——突然发现爬虫常用词“爬取”简称“爬”
——我好像在教你们怎么爬
一.网络爬虫框架
上次提到,网络爬虫的奥义在模拟,那么先思考人类上网寻找资料,下载资料的过程:
1.打开浏览器,输入网址(URL),向服务器发送请求;
2.等待服务器响应请求,返回数据,通过浏览器加载网页;
3.在网页上找到自己想要的数据;
4.下载数据;
对于爬虫,也是类似的。它模仿人类请求网页的过程,但是又稍有不同:
首先,对于上面的步骤1、2,利用python实现请求一个网页的功能;
其次,对应于上面的步骤3,利用python实现解析请求到的网页的功能;
最后,对于上面的步骤4,利用python实现保存数据的功能。
于是分为三大步:发送请求,解析内容,保存数据。
二. requests:发送请求
网页请求的方式也分为两种:
1.GET:最常见的方式,一般用于获取或者查询资源信息,也是大多数网站使用的方式,响应速度快;
2.POST:相比 GET 方式,多了以表单形式上传参数的功能,因此除查询信息外,还可以修改信息;
在此先只介绍GET方式。
下载第三方库requests,可利用其中的函数实现发送请求的功能;
import requests
resp=requests.get('https://www.baidu.com') #请求百度首页
print(resp) #打印请求结果的状态码
print(resp.content) #打印请求到的网页源码
至此,我们只能得到HTML代码,响应状态码等,需要的数据呈现得不直观,
于是需要——
三. BeautifulSoup:解析内容
解析的对象是HTML,我们需要的数据,图片,超链接等等都在其中(对于简单的HTML来说是这样,但有的网页设计者利用其他方式呈现数据,则无法直接提取);
常用的解析的工具库:xpath,BeautifulSoup(百度翻译为靓汤,像是广东翻译呢);
在此先只介绍BeautifulSoup;
首先下载
pip install bs4
#bs4中 bs指BeautifulSoup ,4是第四代;
BeautifulSoup会将HTML内容转换成结构化内容,你只要从结构化标签里面提取数据就OK了:

*BeautifulSoup在搭配lxml使用时速度更快;
lxml也是一个第三方库,需下载:
pip install lxml
以下为一些BeautifulSoup的用法:
- 创建BeautifulSoup对象
首先导入bs4库:
from bs4 import BeautifulSoup
而后的演示将以b站首页为例;
对b站首页的HTML内容创建BeautifulSoup对象:
import requests
from bs4 import BeautifulSoup
html = requests.get('https://www.bilibili.com/')
bsoup = BeautifulSoup(html.content,'lxml')
- Tag
Tag即为HTML中的一个个标签;例如:
<title>哔哩哔哩 (゜-゜)つロ 干杯~-bilibili</title>
···
<a class="link" href="//www.bilibili.com"><i class="bilifont bili-icon_dingdao_zhuzhan"></i>主站</a>
以上的title、a及其<>内和···间的内容都属于一个Tag;
把HTML构建成BeautifulSoup对象后,可以方便地提取Tag;
print(bsoup.title)
print(bsoup.a)
<title>哔哩哔哩 (゜-゜)つロ 干杯~-bilibili</title>
<a class="link" href="//www.bilibili.com"><i class="bilifont bili-icon_dingdao_zhuzhan"></i>主站</a>
如果你有心情看完b站主页的HTML代码,你会发现Tag title和a远不止以上的两个,实际上上面只输出了第一个出现的title和a标签;
beautifulsoup.xxx:提取第一个出现的xxx标签
- find()
find()方法用于提取BeautifulSoup对象中的Tag,传入的参数为Tag名称,返回第一个在HTML文本中出现的目标Tag(所以和上面的效果其实是一样的);
print(bsoup.find('title'))
<title>哔哩哔哩 (゜-゜)つロ 干杯~-bilibili</title>
虽然效果看起来是一样的,但是find()方法可传入更多参数,对提取的Tag做出条件限制,例如可以利用Tag的属性对提取的Tag做出限定;
属性即为一个Tag的<>中的‘class’,‘href’等;
例如此时需要找到一个href属性为‘//www.bilibili.com’的Tag:
print(bsoup.find(href='//www.bilibili.com'))
<a class="link" href="//www.bilibili.com"><i class="bilifont bili-icon_dingdao_zhuzhan"></i>主站</a>
如果用class属性来做限制条件,会发现一些小问题,因为class是python的关键字,为了规避关键字的问题,在find()中我们把class写为class_,加一个下划线。
print(bsoup.find(class_='up'))
<p class="up"><i class="bilifont bili-icon_xinxi_UPzhu"></i>米哈游miHoYo</p>
再举一个例子,找一个class属性为‘up’的p标签:
print(bsoup.find('p',class_='up'))
输出结果同上;
- find_all()
find_all()方法用于提取BeautifulSoup对象中的Tag,返回一个列表,包含所有符合条件的Tag;
具体用法与find()相同;
pritn(bsoup.find_all('a',class_='name'))
[<a class="name" href="//www.bilibili.com/v/douga/mad/">MAD·AMV</a>, <a class="name" href="//www.bilibili.com/v/douga/mmd/">MMD·3D</a>, <a class="name" href="//www.bilibili.com/v/douga/voice/">短片·手书·配音</a>, <a class="name" href="//www.bilibili.com/v/douga/garage_kit/">手办·模玩</a>, <a class="name" href="//www.bilibili.com/v/douga/tokusatsu/">特摄</a>,···, <a class="name" href="//www.bilibili.com/list/recommend/1.html" target="_blank">特别推荐</a>]
- attrs
print(bsoup.a.attrs)
{'href': '//www.bilibili.com', 'class': ['link']}
用以上方法,我们以一个字典的形式输出了a标签的所有属性。当我们需要提取其中具体的一个属性时,有两种方法,例如以下提取a标签的class属性:
print(bsoup.a['class'])
print(bsoup.a.get('class'))
['link']
- 更多关于BeautifulSoup的用法可参考崔庆才大佬的文章:https://cuiqingcai.com/1319.html
四.TASK:提取bilibili三星堆搜索页面中的所有视频标题与链接
- 发送请求并构建BeautifulSoup对象
import requests
from bs4 import BeautifulSoup
html=requests.get('https://search.bilibili.com/all?keyword=%E4%B8%89%E6%98%9F%E5%A0%86')
bsoup=BeautifulSoup(html.content,'lxml')
- 找到想要的数据
打开bilibili三星堆搜索页面,打开F12[开发者模式],用 定位到HTML文本中视频标题所在的位置;
定位到HTML文本中视频标题所在的位置;


由此我们找到了视频的标题和超链接都存在a标签下,分别存在title和href属性下,那么用get()输出就好了;
a_list=bsoup.find_all('a') #获取网页中的所有a标签对象
for a in a_list:
print(a.get('title')) #打印a标签对象的title属性,即这个对象指向的标题
print(a.get('href')) #打印a标签对象的href属性,即这个对象指向的链接地址
但你发现这个输出有些不太对:
···
/topic?keyword=%E4%B8%89%E6%98%9F%E5%A0%86
None
/upuser?keyword=%E4%B8%89%E6%98%9F%E5%A0%86
None
None
None
None
世界第九大奇迹三星堆!山海经里遗忘千年的远古文明 竟然不是神话?
//www.bilibili.com/video/BV1Wv411y7Mm?from=search
世界第九大奇迹三星堆!山海经里遗忘千年的远古文明 竟然不是神话?
//www.bilibili.com/video/BV1Wv411y7Mm?from=search
None
···
不仅会出现一些我们不需要的东西,我们想要提取的标题和超链接也会重复出现;
这说明了HTML文本中还有其他的很多我们不需要的a标签,而标题和超链接重复的问题也在HTML文本中得到了解释:

显然我们只需要特定的一些a标签,通过观察HTML代码可知,在上图的两个a标签中,class属性均不同,那么可以尝试用class作为限制条件,至少可以过滤掉重复的a标签;
a_list=bsoup.find_all('a',class_='title')
for a in a_list:
print(a.get('title'))
print(a.get('href'))
世界第九大奇迹三星堆!山海经里遗忘千年的远古文明 竟然不是神话?
//www.bilibili.com/video/BV1Wv411y7Mm?from=search
央视特别节目《三星堆新发现》 完整版3.20-3.23
//www.bilibili.com/video/BV1oz4y1172R?from=search
【才浅】15天花20万元用500克黄金敲数万锤纯手工打造三星堆黄金面具
//www.bilibili.com/video/BV16X4y1g7wT?from=search
三星堆“上新”!这波啊,DNA是真的动了
//www.bilibili.com/video/BV1xy4y1E7uu?from=search
···
这次只提取class属性为title的a标签,发现正好得出了我们想要的结果;
- 切换页面
以上的代码整合在一起,只能提取出第一个搜索页面的视频标题与超链接,如何取出多个页面的数据呢?
多翻几页,观察URL的变化:
https://search.bilibili.com/all?keyword=%E4%B8%89%E6%98%9F%E5%A0%86&from_source=web_search
https://search.bilibili.com/all?keyword=%E4%B8%89%E6%98%9F%E5%A0%86&from_source=web_search&page=2
https://search.bilibili.com/all?keyword=%E4%B8%89%E6%98%9F%E5%A0%86&from_source=web_search&page=3
可以发现除第一页外,每一页在URL的末尾有page=x(x为页码数),而第一页虽然看起来没有,其实只是省略了page=1;
所以我们可以定义函数get_page(x),每次构造出第x页的URL,而后发出请求,构造BeautifulSoup对象并提取数据就好了;
- 完整代码
import requests
from bs4 import BeautifulSoup
def get_page(x):
url = 'https://search.bilibili.com/all?keyword=%E4%B8%89%E6%98%9F%E5%A0%86&from_source=web_search&page=' + str(x)
html = requests.get(url)
bsoup = BeautifulSoup(html.content,'lxml')
a_list = bsoup.find_all('a',class_='title')
for a in a_list:
f.write(a.get('title')+'\n')
f.write(a.get('href') + '\n')
f = open("三星堆bilibili.txt","w+")
for i in range(1,11):
get_page(i)
f.close()
五.TASK:下载XKCD网页的漫画*10
XKCD是兰道尔·门罗所创作的漫画的名称;兰道尔·门罗(Randall Munroe)给作品的定义是一部“关于浪漫、讽刺、数学和语言的网络漫画”。
XKCD中文站的URL:https://xkcd.in/

任务目标为:下载10张XKCD漫画到指定文件夹下,并用漫画名称为文件命名;
- 发送请求并构建BeautifulSoup对象
html = requests.get(url)
html.raise_for_status() #此行代码用于检查请求是否被正常响应,如果不正常则及时制止程序运行
soup=BeautifulSoup(html.content,'lxml')
- 找到漫画图片的url
为什么要找漫画图片的url?——因为下载要用;
打开开发者模式,观察HTML文本;
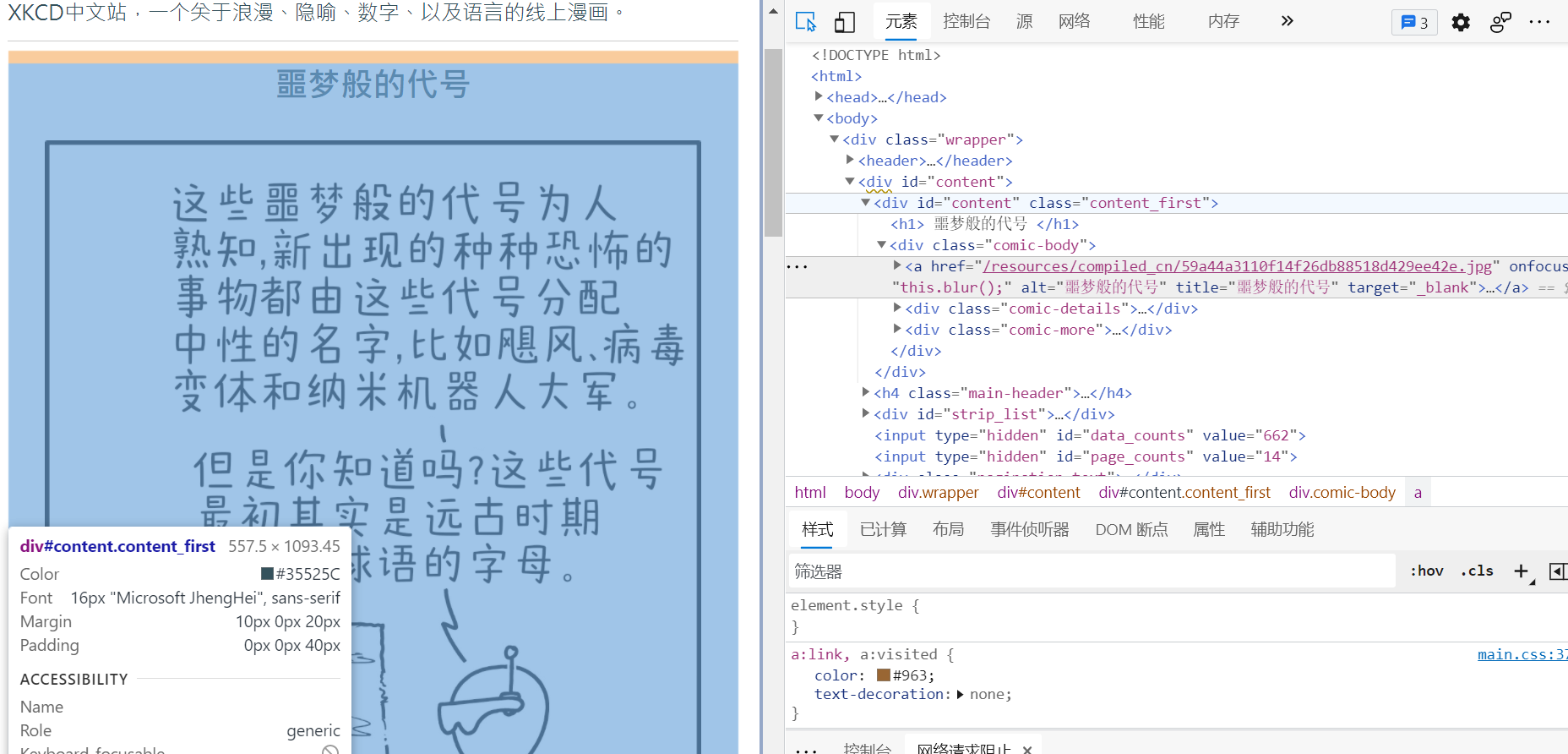
可以发现我们需要的漫画图片url在一个a标签的href属性中,所以根据上面的思路,我们需要用限制条件找出这个特定的a标签;但是,这个a标签中好像没有什么像id或class一样特殊而又唯一的属性让我们作为搜索条件;
此时我们向上看,包含这个a标签的div标签有一个特殊从class=‘comic-body’,因此我们可以先提取出这个div标签;
comic_img = soup.find('div',class_='comic-body')
print(comic_img)
<div class="comic-body">
<a alt="噩梦般的代号" href="/resources/compiled_cn/59a44a3110f14f26db88518d429ee42e.jpg" onfocus="this.blur();" target="_blank" title="噩梦般的代号"><img alt="噩梦般的代号" src="/resources/compiled_cn/59a44a3110f14f26db88518d429ee42e.jpg" title="噩梦般的代号"/></a>
<div class="comic-details">字符表甚至本来被称为alpha-bets,但这个词带有的明显的消极含义使人们后来把它忘得一干二净。
脚注:
title text这地方管由字符构成的表叫charsets,然后提出来说alphabet(字母表)是它的古代名称,但是alphabet这个词是alpha加beta来的,因为alpha和beta很恐怖所以这个词消失了。</div>
<div class="comic-more">
<div class="prevLink">
<a href="/comic?lg=cn&id=2337" onfocus="this.blur();">试试运气</a>
</div>
<div class="nextLink">
<a href="/comic?lg=cn&id=2484" onfocus="this.blur();" target="_self" title=" H-alpha">下一篇</a>
</div>
</div>
</div>
提取出的这个div标签含有很多子标签,我们需要的a标签也是其中之一;而这段div标签又像是一个新的HTML文本,可以再对其使用find(),找出我们想要的那个a标签;
(后来我发现不用这么麻烦,因为同样含有目标数据的img标签只有一个
comic_img = soup.find('div',class_='comic-body').find('a')
print(comic_img)
<a alt="噩梦般的代号" href="/resources/compiled_cn/59a44a3110f14f26db88518d429ee42e.jpg" onfocus="this.blur();" target="_blank" title="噩梦般的代号"><img alt="噩梦般的代号" src="/resources/compiled_cn/59a44a3110f14f26db88518d429ee42e.jpg" title="噩梦般的代号"/></a>
而后提取出该a标签的href;
但需要注意一点,这个href不是完整的URL,它省略了开头的‘https://xkcd.in/’,在得到href后需要补上这段才是漫画图片的URL;
comic_url = comic_img.get('href')
comic_url = 'https://xkcd.in/' + comic_url
- 下载漫画
下载漫画需要先请求漫画的URL,等待服务器响应并返回漫画图片的数据,而后可进行下载:
html = requests.get(comic_url)
html.raise_for_status()
name=comic_img.get('title')
name=name+'.jpg'
#此时顺便提取漫画的名称,加上后缀名后即为文件名
image_file=open(os.path.join('D://xkcd//',name),'wb')
for i in html.iter_content(100000):
image_file.write(i)
image_file.close()
- 找到下一张漫画
把网页往下翻,看到漫画注脚下有两个按键是用于跳转到下一张漫画的:

下面均选择点击下一篇;
同样在开发者模式下,找到下一篇在HTML文本中的位置;
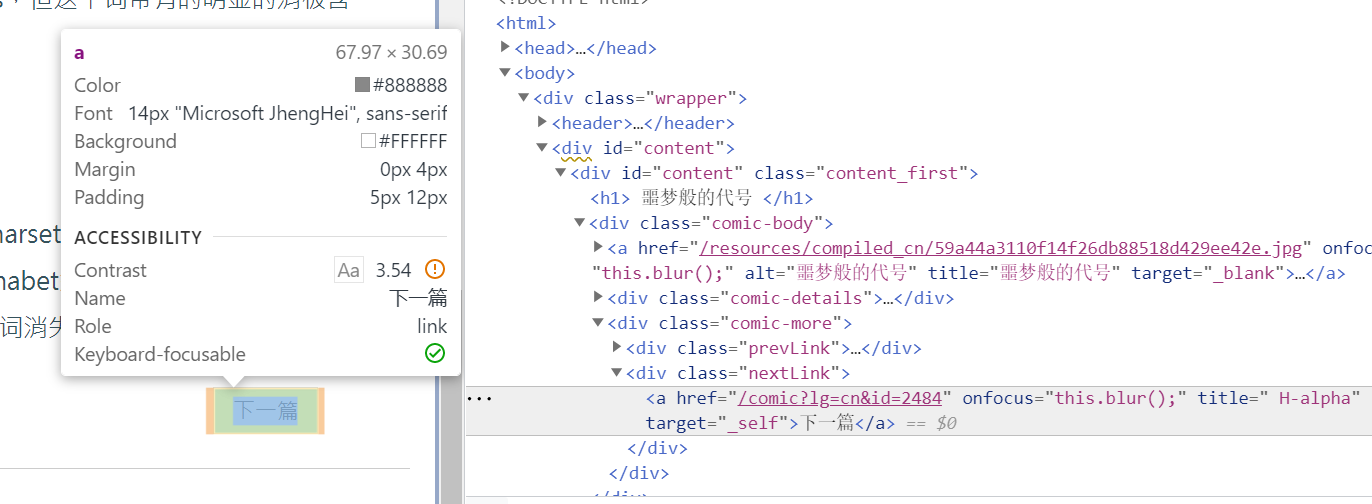
可以发现下一个漫画的网页URL在此a标签的href属性中,同样我们利用上一个div的class属性定位这个唯一的a标签;
nextLink = soup.find('div',class_=('nextLink')).find('a')
url = 'https://xkcd.in/'+nextLink.get('href')
我们得到了下一个URL,而在下一个URL的网页中,下载漫画的操作是一样的,所以用循环串起整个过程;
- 完整代码
import requests,os
from bs4 import BeautifulSoup
url='https://xkcd.in/'
n=1
while n<=10 :
#提取该页面的HTML代码
print('Downloading page %d...' % n)
html = requests.get(url)
html.raise_for_status()
soup = BeautifulSoup(html.content,'lxml')
#找到漫画图片的url
comic_img = soup.find('div', class_='comic-body').find('a')
#print(comic_img)
comic_url = comic_img.get('href')
comic_url = 'https://xkcd.in/' + comic_url
print('Downloading image %s...' % (comic_img.get('title')))
html = requests.get(comic_url)
html.raise_for_status()
#下载图片
name = comic_img.get('title')
name = name+'.jpg'
image_file = open(os.path.join('D://Material//xkcd//',name),'wb')
for i in html.iter_content(100000):
image_file.write(i)
image_file.close()
#找到前往下一张漫画的url
nextLink = soup.find('div',class_=('nextLink')).find('a')
url = 'https://xkcd.in/'+nextLink.get('href')
n = n+1
print('Done.')


 浙公网安备 33010602011771号
浙公网安备 33010602011771号